deepseek输出质量的关键:精心准备中文素材、RLHF奖励模型中文博士多少分,确立中文在大模型研发里的至尊地位
最近看deepseek的输出,在写诗写文方面让人印象深刻,和学术界的关注是相反的。学术界更重视数学、编程、逻辑能力,对于强化学习创新很赞。而大众不懂这些,就以自家维持得最好的语文水平来考察,发现很厉害。
为什么deepseek的语文水平让大众很满意?窍门在哪?我猜是有两招,但是论文和技术报告里没说。
大模型就是从训练素材里学本事。deepseek精心准备了14万亿个token的预训练素材,其实数量不算多。我猜测,开发者在中文素材上下了大功夫。
这是因为,从语言活力来看,中文在全球各种语言中是断崖领先的。不仅表示能力领先一个维度,而且还很有开放性,新事物、新表达方式都能很好融合进来。很多中文诗翻译成英语就不对劲了,而英文诗翻成中文,意境能明显提升。中外网友在小红书对话,不仅中文好玩,中国网友写英文都更好玩。
deepseek应该在中文素材收集、整理上下了很大功夫,作为大模型语言能力的基础。即使输出外文,也会受益于优秀的中文素材库。如很多中国大陆网络上的梗,都收集了。
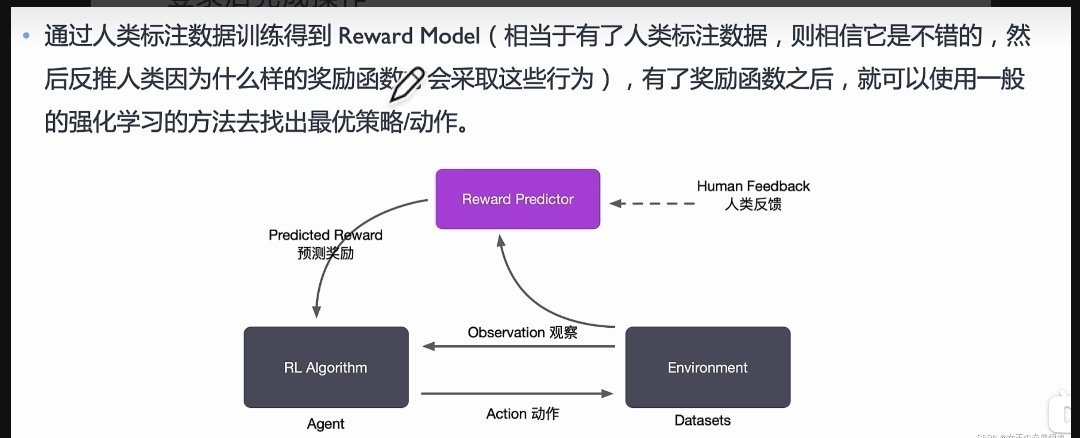
另外一个很重要,但是一般人不知道的,是RLHF评估模型。RLHF是大模型输出给人类看感觉好的最关键一步,之前是预训练,不需要人为打分,就是大模型看素材自己学,但是输出人类看了很不满意。
解决办法就是RLHF(Reinforcement Learning from Human Feedback),人类反馈的强化学习。这不是说大模型的每个输出,人类来打分,然后让大模型改系数优化,这样人会累死,要打的分太多了。很妙的绝招是,机器学习建立一个“打分器”,自动打分。可以用少量但是足够的大模型输出,让人来评分,根据这些打分训练打分器,也就是“奖励模型”(reward model)。再用这个打分器,给大模型的海量输出打分,自动训练。
等大模型输出水平提升了,又去让人打分,进一步训练打分器,提升打分水平。来回搞多次,大模型的输出就让人满意了。
deepseek的大招是,对打分器要求极高!据说找了语文水平最高又肯劳动的北大中文博士来打分。老师要求严格,学生水平才能很高。不仅古诗词、文学,各种网络吐槽都要评估水平。
这样,几个论文没说的大招,把大模型的中文能力推到了前所未有的高度。群众看了就惊呼,大模型成精了!
中文能力强了,那别的语言就更不在话下了。deepseek帮助中文确立了在全球各种语言的至尊地位。OpenAI模仿的新版,也不由自主用中文思考。这就是中文的实力,大模型时代,中文素材是核心。

老广杰克
人多反馈多的国家说了算