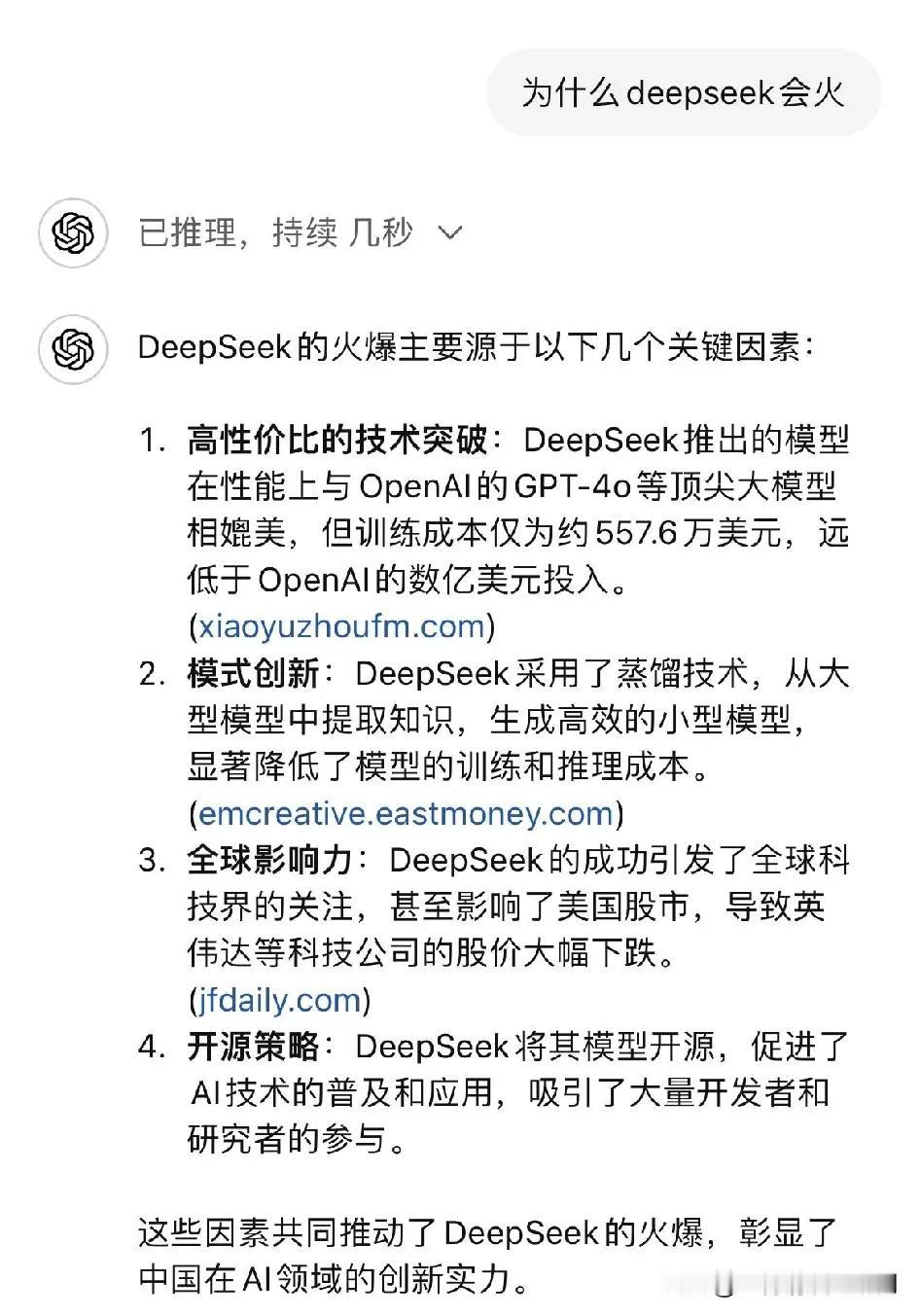
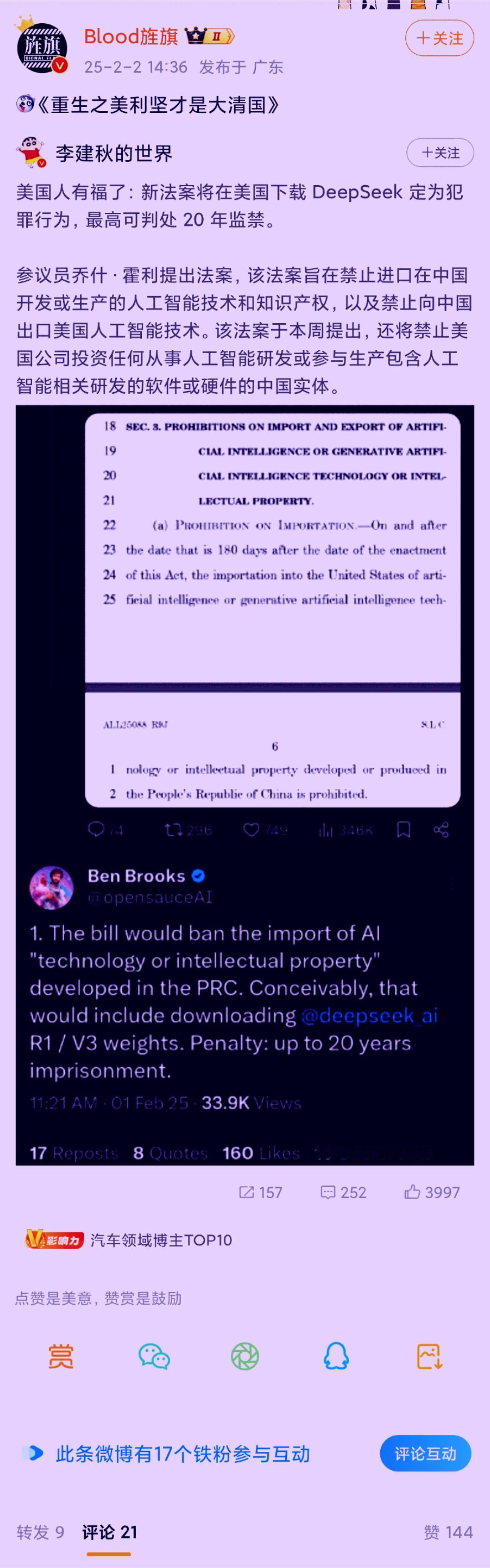
说实话,这次deepseek爆火,反而是首先在国外火出圈,然后才是国内爆火。 然后再说为啥两个模型带来反响差这么多。 文心一言、豆包这些AI模型,其实基本还是在AIGC的老路上,这些是没有办法和ChatGPT、o1模型一教高下的,不光是技术水平的差异。虽然这些是中国AI领域的代表,但始终是一个追随者。 而deepseek在数学、代码、自然语言推理等任务上性能比肩 OpenAI 的 系列模型,但训练成本却远远低于投入。比如去年 12 月发布的 DeepSeek - v3,训练仅需 2048 张英伟达 H800 AI 芯片,成本 557.6 万美元,而类似模型业界一般需 1.6 万张 GPU 的集群训练。这对整个将算力和芯片作为护城河的美股企业是一个很大的冲击。 在创新性上,此前行业基本遵循 “Scaling Law” 的线性逻辑,拼参数规模、算力储备等。但deepdeek 的成功证实了大模型可通过训练方法创新、数据质量提纯等跳出 “堆资源” 陷阱,这对行业传统技术发展路线是巨大冲击,使投资者开始重新审视现有科技企业的技术路径和发展前景。