之前听一个AI专家说:模型的摩尔定律是「3个月」,3个月就可以用更小的模型达到大一级模型的效果。
在deepseek出来之前,我还半信半疑。现在等于是击碎了所谓高算力,以及储备算力的迷信。
这个规律放在智能驾驶行业里亦然,智驾的摩尔定律可能也是3个月。而且不再看所谓的储备算力,看的是各家的模型算法。所以,智能驾驶的竞赛可能才刚刚开始。
由于模型需要的算力越来越少,接下来的趋势将是AI PC,每个终端都将是一台本地AI。
所以,未来几年最火的不再是云端算力,而是终端算力。
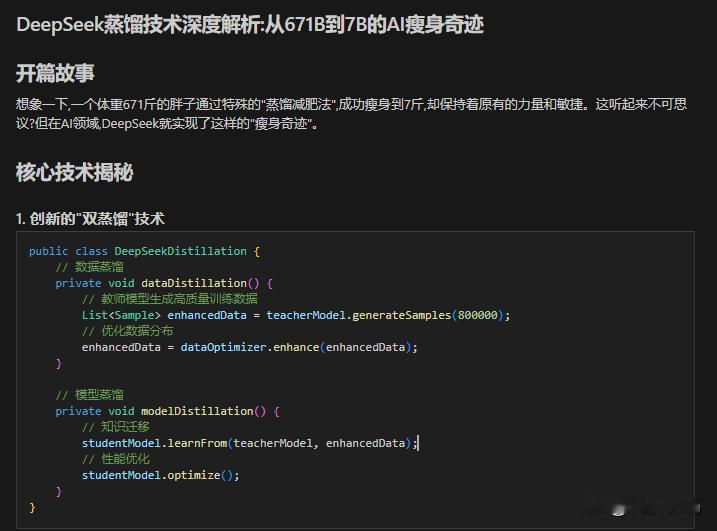
车端的算力越强,蒸馏下来的模型越完整,比如deepseekr1 llama支持8b-70b(80亿-700亿的参数)的版本,70b比8b的强不少。
总结一下,储备算力将不再那么重要,特斯拉那1.6万张A100可能是打水漂。虽然云端算力不再那么重要,但是大模型需要的算力对于终端来说非常大的,必然需要蒸馏后,才能下放到终端,这个时候又比较考验终端的算力能力。