AI技术发展迅猛,但越是前沿的AI方向就越是曲高和寡。而人像、语音、手写这三类传统的AI应用,则历久弥新,已经普惠大众。
大多数用户日常使用的语音和手写相关AI应用主要是文字输入。人像类AI的应用更加广泛,例如基于人脸识别的门禁系统、拍照之后对脸部进行修饰、更换照片的背景、更换人物的发型和服饰等。
在基于龙芯CPU的国产电脑上,有一些专业领域的AI应用,但缺乏大众化的AI应用软件,至少没有“美女主播”用龙芯电脑做直播。随着龙芯电脑的用户基数扩大,用龙芯电脑做直播、修图等需求也越来越多。那么在龙芯电脑上开发原生的AI应用软件就是必需的,也是必然的。下面我就尝试一下在龙芯3A6000这款CPU上运行几种基础的AI人像处理功能,顺便探查36000在执行AI运算时的性能水平。
功能展示基于神经网络技术的AI框架都分为“训练”和“推理”两个部分。“训练”时要先准备好大量同类型的“题目”和“答案”,AI程序通过对这些数据数据归纳总结,得到一个包含了“经验”的模型文件。“推理”就是依据模型文件中的“经验”,从用户输入的图片等数据得到与“训练”时作为“答案”的数据相似的结果。在用户电脑上运行的都是“推理”的部分,由运行库和各种模型文件组成。
能在龙芯3A6000上运行的AI推理框架(软件)很多,一部分是开发者明确表示支持的,例如NCNN、ONNX Runtime等,一部分是可以用开源代码自行构建的,例如DLib、PyTorch、Transformers等。我本次使用的是ONNX Runtime,这是由微软主导的开源AI框架,兼容很多其它框架的功能。那些AI框架的模型文件可以转换成ONNX格式,然后作为ONNX Runtime的模型。我本次使用的模型文件就分别来自于Insightface、Tensorflow、PyTorch。
用于人像处理相关的各种大众化软件,都是以下面几种AI处理为基础:
 检测人脸位置并标定人脸轮廓关键点。分割头发、衣服、人脸五官等区域。分离人像与背景并处理边缘透明度。
检测人脸位置并标定人脸轮廓关键点。分割头发、衣服、人脸五官等区域。分离人像与背景并处理边缘透明度。最初的人像处理基本上只检测了人脸位置,甚至没有轮廓关键点。有了人脸位置信息,就可以通过肤色检测进一步获得皮肤区域,然后进行磨皮、去斑、美白等处理。然后有了轮廓关键点之后,就可以对脸型和口、鼻、眼的大小及位置进行调整。还可以进行局部的颜色修改,比如调整唇色和眼影,以及在脸部、头部增加饰品。
主要由于硬件性能提高,数年前实现了有实用价值的头发检测,再加上更细致的区域分割,使调整头发颜色、更换发型、更换衣服等也功能也可以轻松实现。基于这些分割信息,已经可以较粗糙地分离人像与背景,再配合一些边缘透明度的处理方法,就可以得到可接受的抠图效果,画面质量和视频直播、通话、会议类软件换背景功能的效果差不多。
但很快AI就进化出了更加精细的自动化抠图能力,人像与背景的分离非常干净,对头发与背景融合处的半透明处理也比较合理。一些高精度的模型甚至能达到发丝也纤毫毕现的程度,只是代价是运算量大幅度增加。
性能对比AI是典型的计算密集型应用,各种AI框架一般都同时支持CPU计算和GPU加速。然而即使“推理”对硬件的要求远低于“训练”,但因为GPU加速基本上只支持Nvidia的CUDA,且对显存容量的要求极高,所以现存的绝大多数电脑,包括龙芯在内,大多数情况下都只能使用CPU进行AI计算。
那么,在只使用CPU计算的条件下,龙芯3A6000与同类产品有多大性能差距呢?
测试环境都是使用的Deepin R23系统,GCC13编译器。使用UOS专业版、银河麒麟、Loongnix等系统也可以运行,只是编译程序时的工序要多一些。
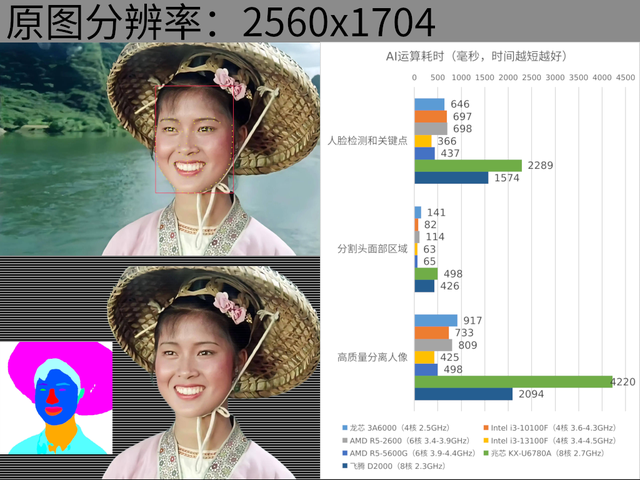
先来试一张有多张人脸的图片,原图分辨为2048×2144,一般视频聊天和会议等软件的视频画面远远低于这个分辨率。图片是5个人的合影,但程序从图片中找出了6张脸,第6张脸在远处,只占很小的面积。

本次使用的AI模型都是针对图片处理,而未对视频进行优化,也就是比较侧重于质量,而非偏向于效率,因此在测试的各款CPU上都远远达不到视频级别的“实时”水平。
在开发视频类的应用时,通过使用精度较低的模型文件、充分利用视频帧间差异较小的特性、降低图像分辨率、限制要检测的最小人脸的画面占比、限制需处理的人脸数量等方式,就能把效率提高上百倍,满足实时处理的需求了。

上面以及下面的测试结果清晰地表明了龙芯3A6000的AI计算性能还是很不错的,与同样4核8线程的Intel i3-10100F,以及6核12线程的AMD R5-2600是相同的水平。
龙芯3A6000能够以仅仅2.5GHz的频率与它们打平,是因为龙芯CPU每GHz的性能比较强,3A6000每GHz的性能与Intel 13代酷睿是相同的水平,因此能以较低的频率打平10代酷睿,甚至比6核12线程的AMD R5-2600略好一些。

而Intel 13代酷睿i3-13100F和AMD R5-5600G虽然每GHz的性能并不比龙芯更强,但它们工艺先进,运行频率高,所以性能更高也在情理之中。AMD的浮点和向量运算能力明显弱于Intel,因此在AI运算方面,6核的AMD CPU只与相同时期的4核Intel产品差不多。
龙芯下一代产品将再次提高每GHz的性能,再加上频率也有小幅度提高,单核的AI运算性能估计能与13代酷睿持平。并且龙芯下一代桌面CPU是8核16线程,那么多核并行时的AI运算性能就应该是13代酷睿i7的水平。
受限于手机CPU的运算能力,手机端很多图片处理软件的AI运算任务是在云端进行,使用服务器来完成AI方面的计算。那么龙芯当前的服务器CPU应该也可以承担这样的计算任务,因为在核心数量相同的时候(16、32、64,或多路达256核),它各方面的性能都不弱于与10代酷睿同代的Intel服务器CPU产品。唯一的缺点是Nvidia没有推出支持龙芯的显卡驱动,对龙芯CPU的适用场景造成了限制。
飞腾和兆芯的CPU似乎极不擅长浮点和向量运算,它们8核并行的运算能力只有龙芯3A6000的1/2到1/5,而龙芯3A6000只有4个核心。不过飞腾和兆芯都已经有新型号的桌面CPU,据宣传最新的飞腾D3000和兆芯KX-7000的性能都相对于上一代实现了翻倍,只可惜它们去年发布的产品至今仍无法在零售渠道买到。虽然它们性能翻倍后也仍然难以承担计算密集型任务,但有进步总是好的。
上面所有的测试结果,都是使用的Deepin R23系统,GCC13编译器,ONNX Runtime 1.18版的运行库。测试程序也已经放在了Gitee上,所有人都可以下载源码,查看、编译、验证。
代码开源不只ONNX Runtime是开源的,我编写的测试程序也是开源的。开源测试程序的主要目的不是为了便于大家验证,而是演示在龙芯电脑上用C++调用ONNX Runtime进行AI推理的过程。

实际上程序本身并不区分CPU指令集架构,无论是用龙芯CPU还是Intel CPU,都是一样的代码,一样的开发流程。只是因为用Python调用AI框架的例子很多,但用C++的很少,因此我编写了一个C++的例程。毕竟,Python不是很方便用来开发“小而美”且与普通用户亲和的桌面应用软件。
如果是在Deepin R23、AOSC等核心版本较高的Linux发行版上运行,那么只需要下载和编译ONNX Runtime就算是配置好了开发环境。但UOS专业版、Loongnix等系统的Linux核心版本较老,配套的各种软件包的版本也相对较老,是不能直接编译ONNX Runtime的。
这种情况下,就至少需要升级Python和CMake。
先分别从Python和CMake官网下载其最新版本的源码,然后编译并安装。

因为Python允许多版本并存,所以在安装后要切换到新版本。切换Python版本的方法很多,这里不再赘述。
关于程序代码和编译,这里也不多说,有兴趣的朋友可以在gitee上找到我。