也许过不了多久,语音也可以自如地指挥车子自动驾驶了。比如我们想喝咖啡,于是就让车子找家咖啡馆把我们带过去。
这种场景并不是一种在脑海中的设想,而是正在成为现实。理想智驾研发负责人贾鹏在今天的英伟达 GTC 大会上,就通过视频的方式演示了这种场景。
与此同时,贾鹏还演示了另外两种场景,一种是车主也不清楚自己在哪儿,但是可以呼唤车子来接;另一种则是车主先行下车,接着让车子自行去寻找车位。
总的来说,贾鹏把这形容为「每个人的专职司机」,并且他还表示理想会「重新定义智能驾驶」。
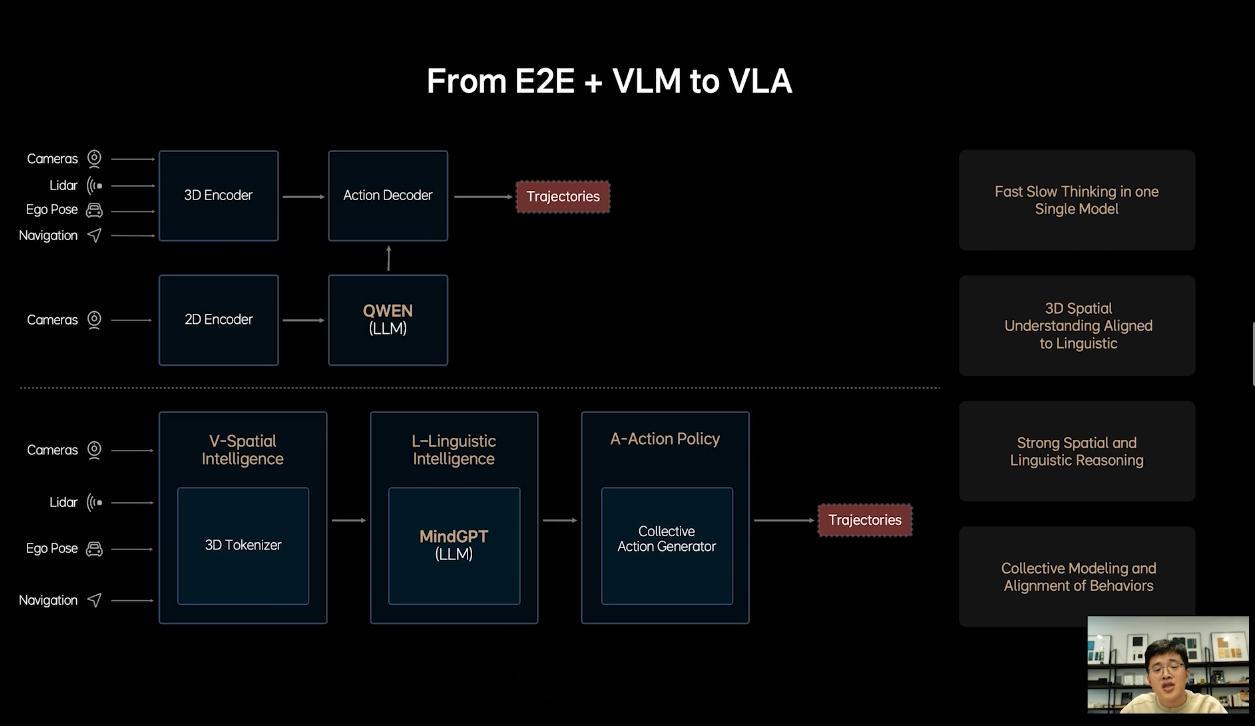
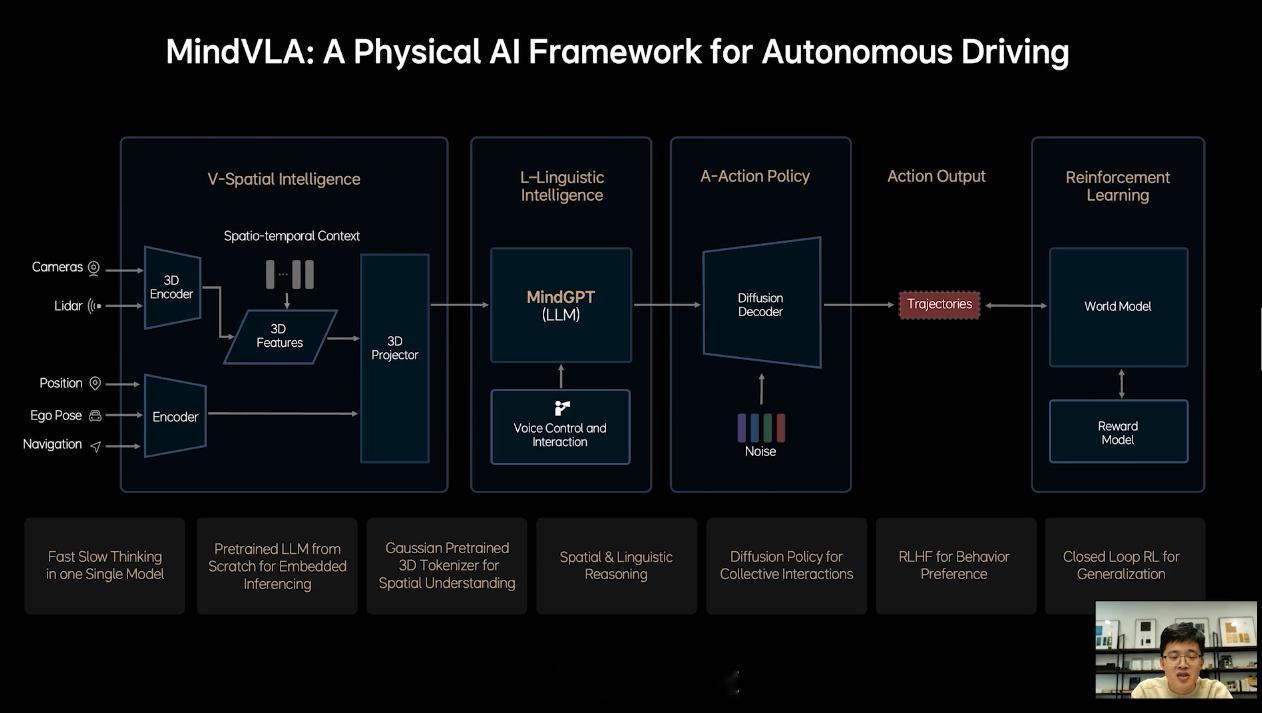
之所以能够实现这样的场景,据贾鹏介绍,理想依靠的就是 VLA 技术,也就是视觉语言动作模型(Vision-Language-Action Model),而理想则把自己的 VLA 技术称作 MindVLA。
当前,理想的智能驾驶技术仍是端到端 + VLM。这套技术方案上车之后,不仅大幅提升了理想的智驾水平,而且还助推了 AD Max 车型销量的增长。不过,贾鹏表示,端到端 + VLM 也有很多问题。
比如,端到端和 VLM 是两个独立的模型,要联合训练比较困难。此外,端到端 + VLM 还有对 3D 空间理解不够、驾驶知识和内存带宽不足、难以处理人类驾驶的多模态性等问题。
对于人类驾驶的多模态性,贾鹏专门做了进一步的解释,就是指同样一个驾驶行为,人不同的话,驾驶状态也会不同。另外,即使是同一个人,心情不一样的时候,开车的方式也会出现不同。
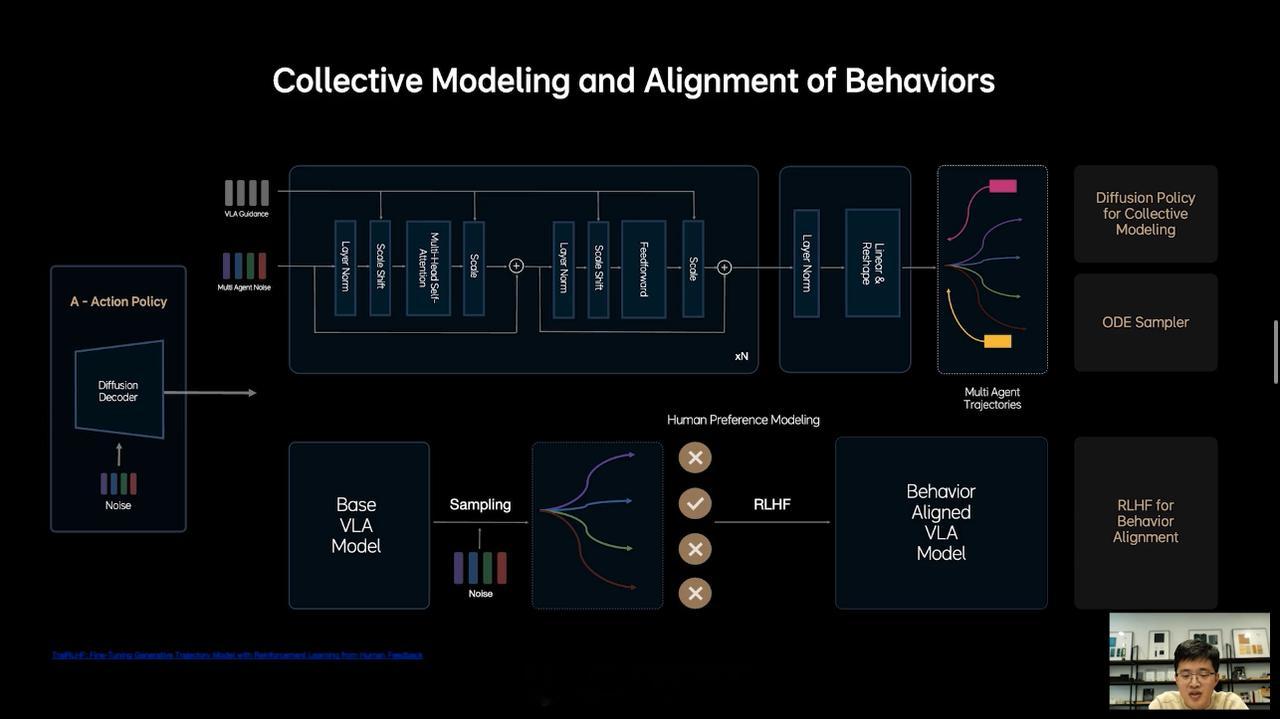
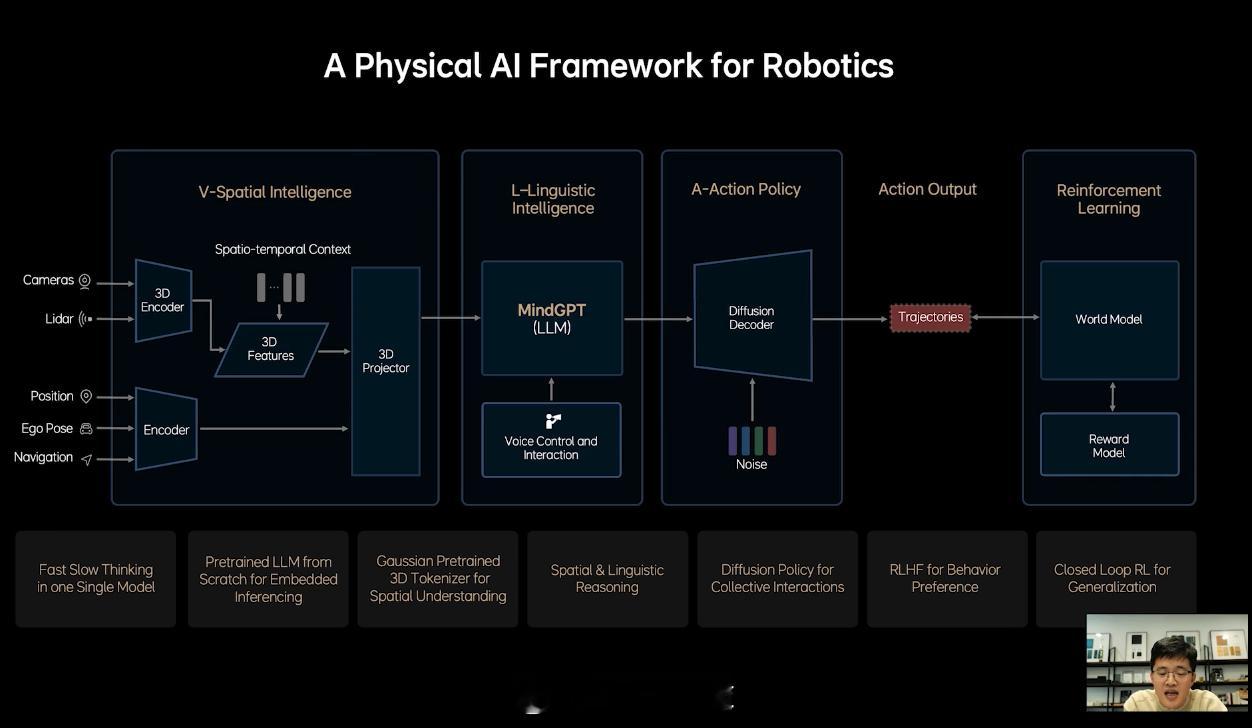
而 MindVLA,据贾鹏介绍,它并不是简单粗暴地将端到端和 VLM 这两个模型统一在一起,这其中有很多模块都需要重新设计。在能力上,MindVLA 可以同步提高智驾的上限和下限,实现空间、行为和语言的统一。
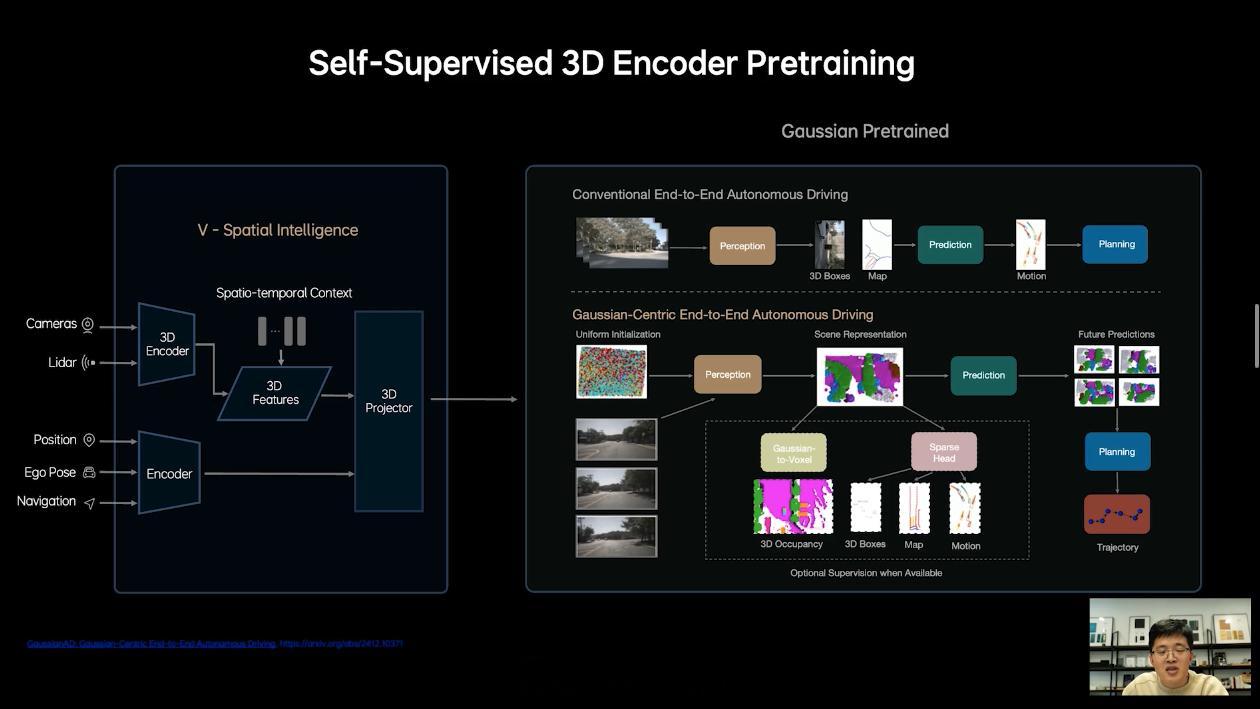
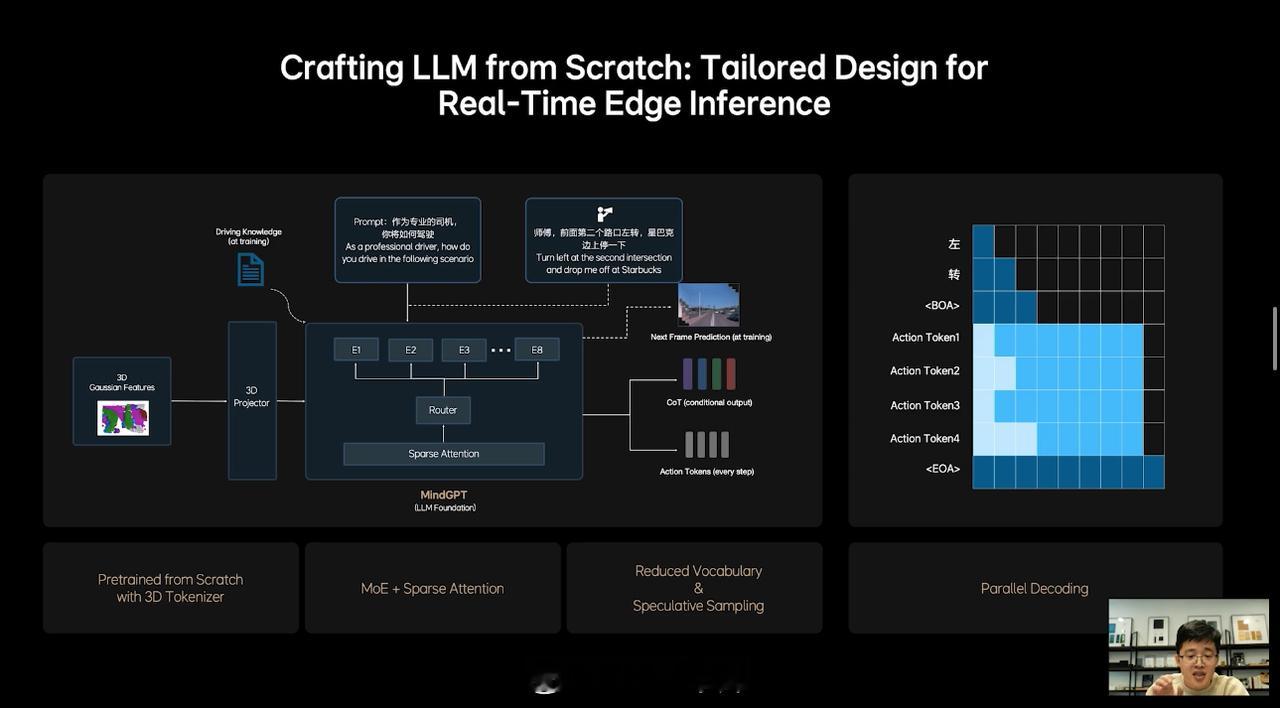
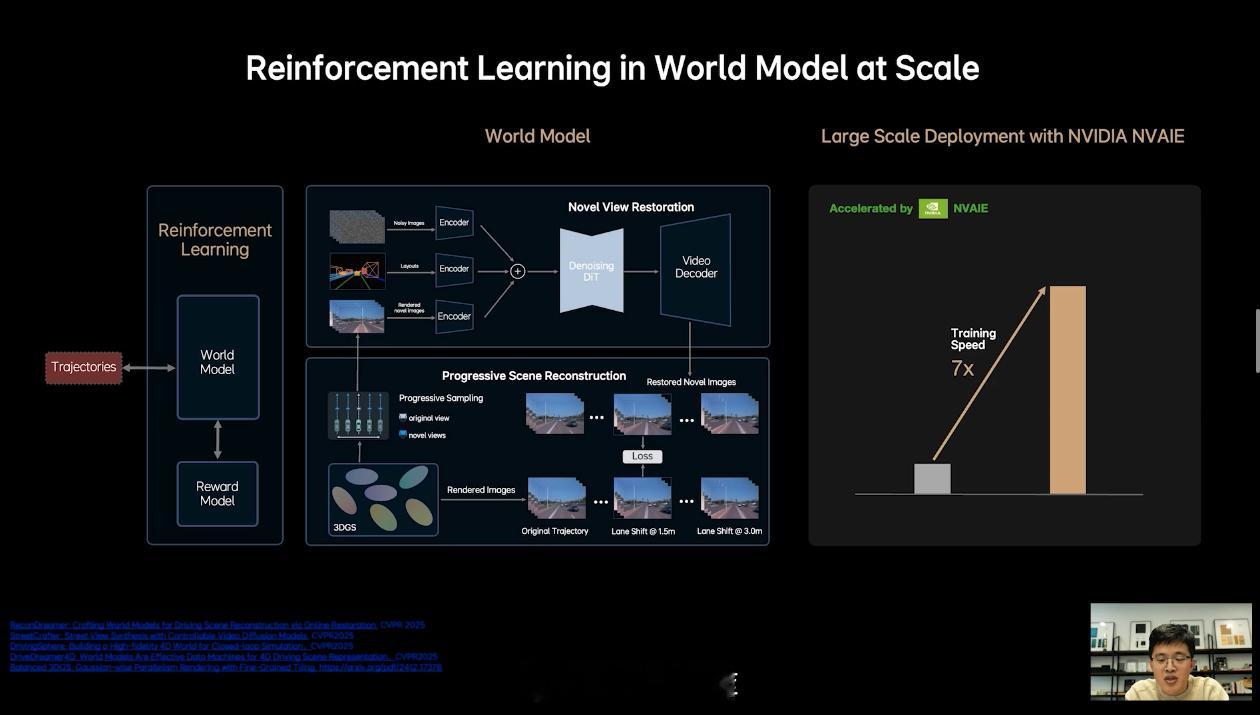
具体地说,MindVLA 可以对 3D 空间有更好的理解;具备语言智能,可以理解车主的语音驾驶指令;能够在世界模型中强化学习等。
最终,借助 VLA,理想就是要实现类似于开头所说的那些驾驶场景。等到那些驾驶场景真的落地的时候,车子也就更像是一个四轮机器人了。
新能源汽车42how理想汽车