咱们AI技术确实像开了挂,Manus和DeepSeek这些爆款背后还真有个共同秘密,阿里通义千问大模型(Qwen)撑腰。这事儿说白了就是开源生态往大了玩,让全球开发者都来搭把手。 Manus创始人直接摊牌,说自家产品就是基于Qwen魔改出来的。这可不是个例,DeepSeek开源的6个模型里,4个都用了Qwen当底子,尤其是Qwen-32B蒸馏模型,性能直接对标OpenAI的o1-mini。现在全球开发者用Qwen搞出的衍生模型都突破10万了,比Llama系列还猛,直接成了开源界的顶流基座。 Qwen小身材大能量。比如最新发布的QwQ-32B模型,参数只有DeepSeek-R1的1/20,但性能硬是能打平手。更狠的是这玩意儿用消费级显卡就能跑,创业公司不用砸钱买天价算力也能玩AI。斯坦福团队用Qwen调出来的模型,16块显卡训练半小时就干翻了一众大佬,这性价比谁扛得住? 阿里把Qwen开源后,相当于给行业发了套乐高积木。Manus这种创业公司不用从零造轮子,专注搞应用场景就行。反过来,用户反馈又能帮阿里优化模型,形成“你升级底座,我开发功能”的良性循环。再加上国内手机厂商转型造车、互联网大厂砸钱搞基建,整个AI产业链比国外更"抱团"。 如今,全球开源社区都在讨论Qwen,有开发者直接喊它“AI界的Linux”。Chatbot Arena这些权威榜单上,Qwen动不动就拿冠军,逼得海外团队不得不研究中国模型。就连Meta的首席科学家都承认,中国AI科研论文数量早就超美国了。 说白了,中国AI这波爆发不是靠某个天才灵光乍现,而是把开源生态、市场需求、政策扶持这几张牌打成了组合拳。就像当年智能手机换道超车,现在轮到AI吃这波红利了。
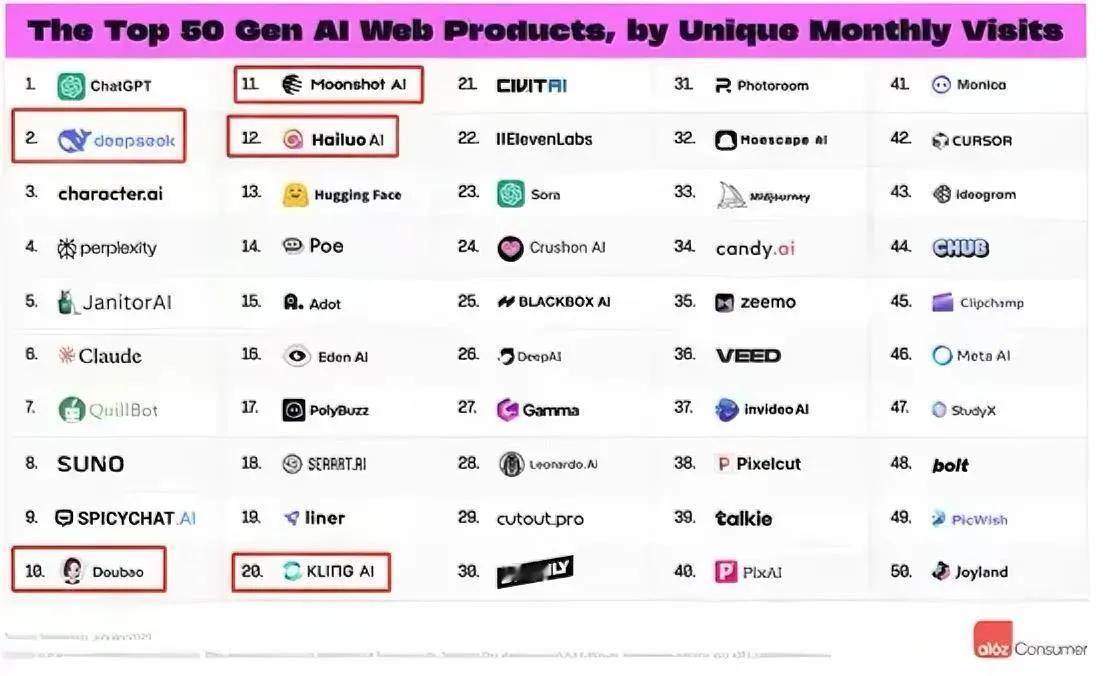
世界排名前20的AI模型中国占了5个!分别是:1、deepseek,杭州深度
【1评论】【15点赞】