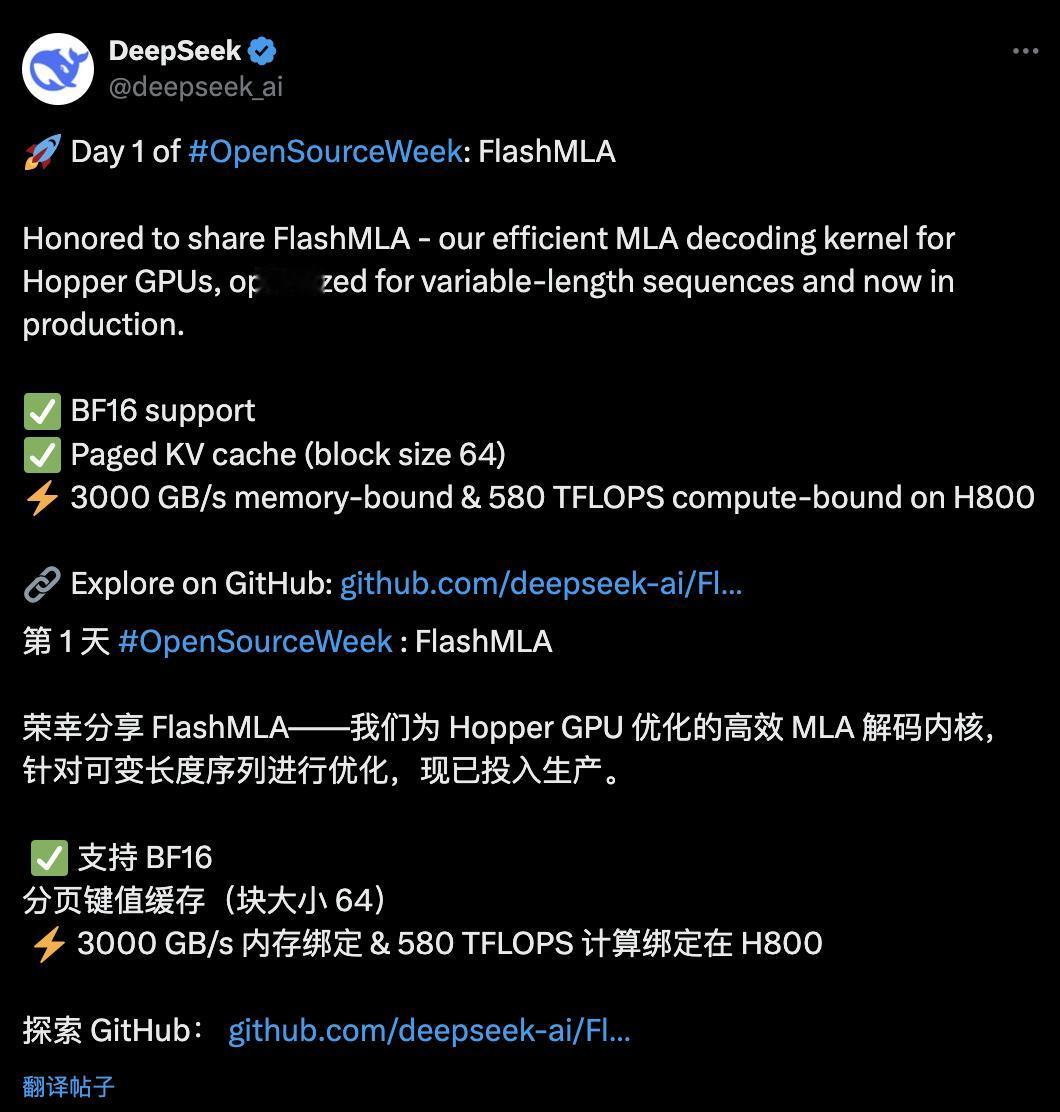
DeepSeek 发布开源项目 FlashMLA 2 月 24 日,DeepSeek 开源周第一个项目 FlashMLA 正式发布。 据官方介绍,FlashMLA 的灵感来自 FlashAttention 2&3 和 cutlass 项目。具体来说,FlashMLA 是一个针对 Hopper GPU 优化的高效 MLA(Multi-Head Latent Attention)解码内核,支持变长序列处理,现在已经投入生产使用。 FlashMLA 专门针对多层注意力机制进行了优化,能够加速 LLM 的解码过程,从而提高模型的响应速度和吞吐量,而这对于实时生成任务(如聊天机器人、文本生成等)尤为重要。简而言之,FlashMLA 是一个能让 LLM 模型在 H800 上跑得更快、更高效的优化方案,尤其适用于高性能 AI 任务。 目前,FlashMLA 已发布版本支持「BF16」与「分页 KV 缓存,块大小为 64」两个特征,其在 H800 上能实现 3,000 GB/s 的内存带宽与 580 TFLOPS 的计算性能。 FlashMLA 现已上架 GitHub。并且其在上线 6 小时,便收获超 5,000 的 Star 收藏,拥有 188 个 Fork(副本创建)。