想过ChatGPT的“大脑”是如何炼成的吗?Andrej Karpathy带你解开大语言模型的神秘面纱!
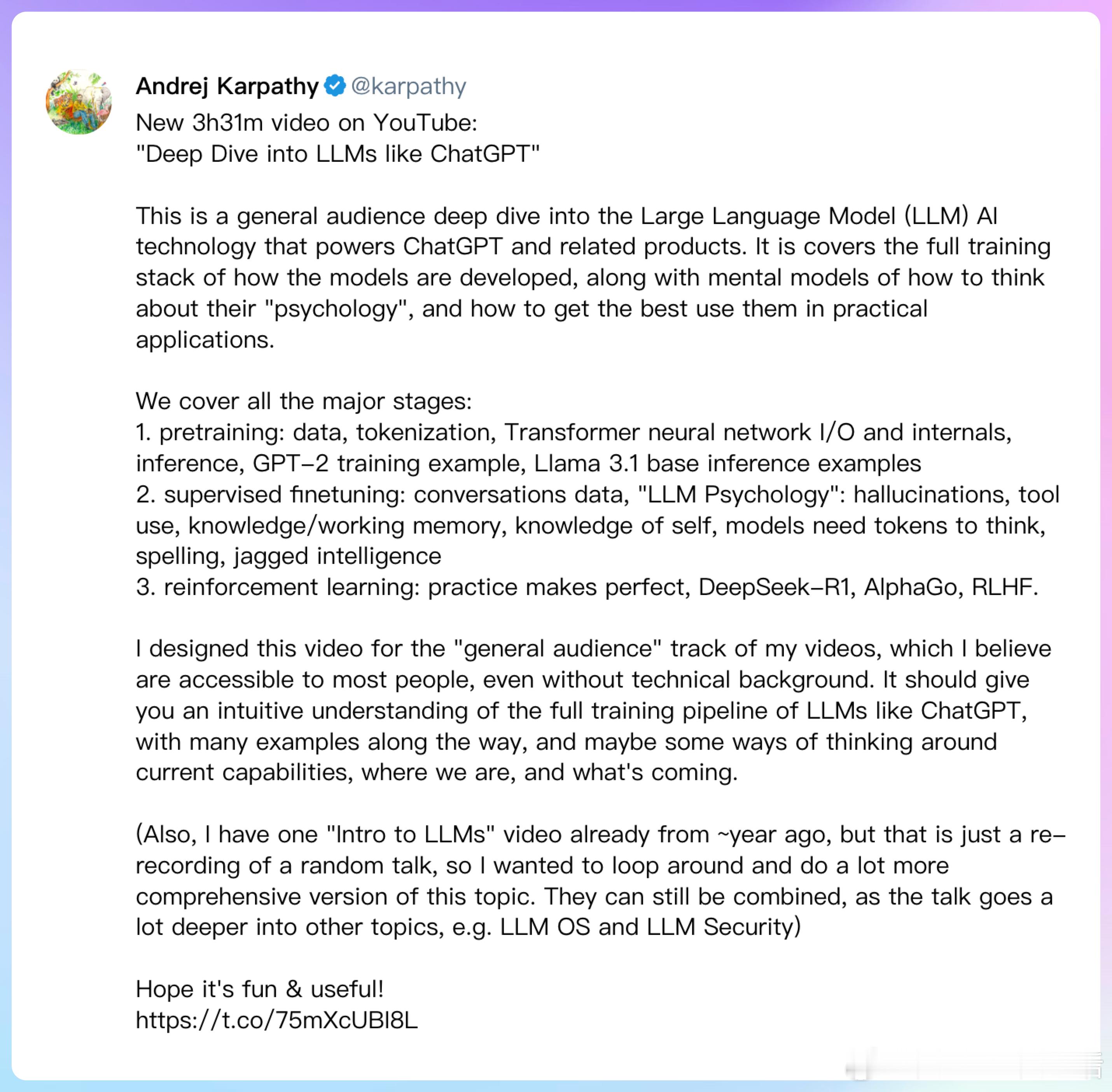
这个长达3小时31分钟的深度视频,将带你走进LLM的完整训练之旅。从最基础的预训练阶段,到精调过程中的“性格塑造”,再到通过强化学习实现“技能进化”,每一步都经过精心设计,即使没有技术背景也能轻松理解。
三个核心阶段清晰呈现:
1、基础训练:就像婴儿学习语言一样,从基本的数据输入、语言理解开始,逐步建立起模型的思维方式
2、精细调教:让AI学会对话、理解上下文,甚至发展出自我认知,这个阶段决定了它的“个性特征”
3、实战强化:通过持续练习和改进,像AlphaGo那样不断突破能力边界
这不是简单的入门讲解,而是一次全方位的探索之旅。不仅讨论当下能力,更展望未来发展。如果你对AI技术感兴趣,这绝对是一个不容错过的宝藏视频。
视频内容要点:
- 大型语言模型 (LLM) 简介
- 该视频全面介绍了大型语言模型,例如 ChatGPT 及其工作原理。
- LLM 功能强大且用途广泛,但也有局限性和潜在风险。
- 该视频旨在让观众了解 LLM 的功能、局限性和道德影响。
- 构建类似 ChatGPT 的 LLM
- 构建 LLM 的第一步是收集和处理大量文本数据。
- 预训练阶段包括从互联网下载和处理文本数据。
- 预训练数据用于训练神经网络来模拟文本数据中的模式。
- 神经网络学习预测序列中的下一个词,从而生成类似人类的文本。
- 从预训练到对话
- 为了使 LLM 具有对话性,它们会经过微调阶段。
- 微调包括使用对话数据集训练 LLM。
- 对话数据集包含人类与助手之间的对话示例。
- LLM 学习根据对话数据集生成类似人类的回复。
- 工具使用和功能扩展
- LLM 可以通过使用工具(例如网络搜索)来扩展其功能。
- 工具使 LLM 能够访问外部信息并执行各种任务。
- 为了使用工具,LLM 会接受使用工具的对话数据集的训练。
- 通过工具使用,LLM 可以提供更丰富、更全面的响应。
- 强化学习与人工反馈 (RLHF)
- RLHF 是一种用于改进 LLM 行为的技术。
- RLHF 包括训练奖励模型来预测人类偏好。
- 奖励模型用于优化 LLM,使其生成人类喜欢的响应。
- RLHF 可以帮助 LLM 生成更符合人类价值观和偏好的响应。
- LLM 的未来方向
- LLM 正在迅速发展,未来有很大的潜力。
- 未来的方向包括多模态 LLM、改进的推理能力和自主任务执行。
- 多模态 LLM 可以处理文本、图像和音频等多种模态。
- 改进的推理能力将使 LLM 能够解决复杂的推理问题。
- 自主任务执行将使 LLM 能够执行复杂的任务,而无需人工干预。
- 实际使用和注意事项
- LLM 是强大的工具,可以用于各种应用。
- LLM 应该用作工具箱中的工具,而不是完全信任。
- LLM 可能会犯错、产生幻觉或产生有偏差的输出。
- 始终检查和验证 LLM 的输出,并在工作中使用它们时拥有产品的所有权。
- 查找和使用 LLM 的资源
- 视频中提到了查找和使用 LLM 的各种资源。
- 对于专有模型,您可以访问 OpenAI 和 Google 等 LLM 提供商的网站。
- 对于开源模型,您可以使用 Together.ai 等推理提供商。
- AI 新闻通讯和 Twitter 是了解 LLM 领域最新进展的绝佳资源。
“Deep Dive into LLMs like ChatGPT”
Youtube: