Netflix的研究员Cameron R. Wolfe解释了为什么之前没有人用DeepSeek-R1的算法来搞大模型:基础模型不一样了。
以下为翻译:
DeepSeek-R1 背后的关键思想是将简单/有效的强化学习算法扩展到解决可验证任务。但是,为什么我们以前没有尝试过呢?
正确的答案是,研究人员确实尝试过将这些类型的方法用于以前的大型语言模型 (LLM),但直到现在它们才如此有效。这主要有两个原因:
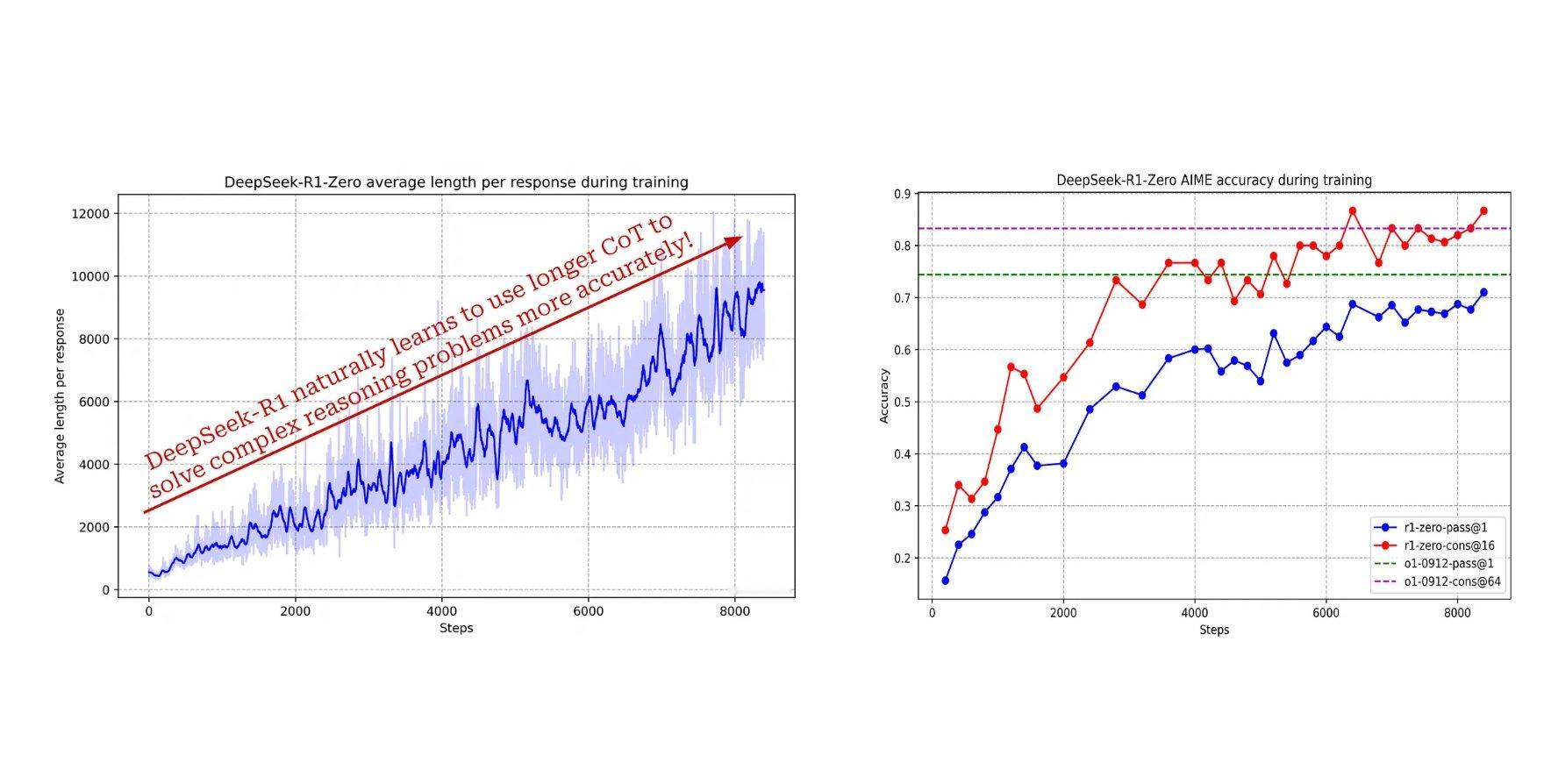
(1)更好的基础模型: DeepSeek-R1 基于 DeepSeek-v3,这是一个在 15 万亿个文本 token 上训练的 6710 亿参数的混合专家模型 (MoE) —— 这是一个非常好的基础模型。与 1-2 年前的基础模型(例如 LLaMA 或 LLaMA-2)相比,最近的模型至少强大一个数量级 —— 大 10 倍,并在超过 10 倍的数据上进行训练。这些更好的基础模型在强化学习训练期间更有可能找到有趣的解决方案(例如,长思维链)。
(2)合成数据/思维链: 大多数现代 LLM 在其训练流程中大量使用合成数据。此外,思维链是 LLM 非常常见的输出结构 —— 人们几乎在所有地方都利用思维链提示。通过综合考虑这些事实,我们可以推断出以下内容:
1. 现代 LLM 生成大量思维链式数据。
2. 生成的数据通常会回到训练循环中。
3. 因此,现代 LLM 在训练期间可能会看到许多思维链。
简而言之,如今的 LLM 更熟悉并且更可能产生思维链式的输出,这为它们在面向推理的强化学习中的探索提供了更好的先验。
我们怎么知道这是真的?为了更多地证明这两个因素对最近在可验证任务上大规模强化学习的成功做出了贡献,我们可以看看这些模型的训练流程(例如,DeepSeek-R1 和 Kimi-k1.5)。此训练流程的第一步是生成 SFT 式的长思维链数据(即“冷启动”数据),这是通过提示完成的。
换句话说,基础模型(可能)已经能够生成长思维链数据。一旦我们基于这些例子训练模型,强化学习就会更稳定,收敛更快,这清楚地表明初始强化学习 actor 对成功有巨大影响!