技术博文 从第一性原理出发《Making Deep Learning Go Brrrr From First Principles》让深度学习飞速运转
horace.io/brrr_intro.html
“你想提高你的深度学习模型的性能。你可能会如何处理这个任务呢?通常,人们会依赖一些以前可能有效或在推特上看到的技巧。--使用in-place operations!将梯度设置为 None!安装 PyTorch 1.10.0 而不是 1.10.1!
用户为何常常采取这种临时性的方法来处理性能问题是可理解的,因为在现代系统(尤其是深度学习)中,性能优化往往既像科学又像炼金术。 话虽如此,从第一性原理出发进行推理仍能排除大量方法,从而使问题更易于解决。
例如,在使用深度学习对数据集进行良好性能训练时,也涉及大量猜测。但是,如果你的训练损失远低于测试损失,那么你正处于“过拟合”状态,此时若试图增加模型容量,则是在浪费时间。 或者,如果你的训练损失与验证损失相同,那么如果你尝试正则化你的模型,就是在浪费时间。
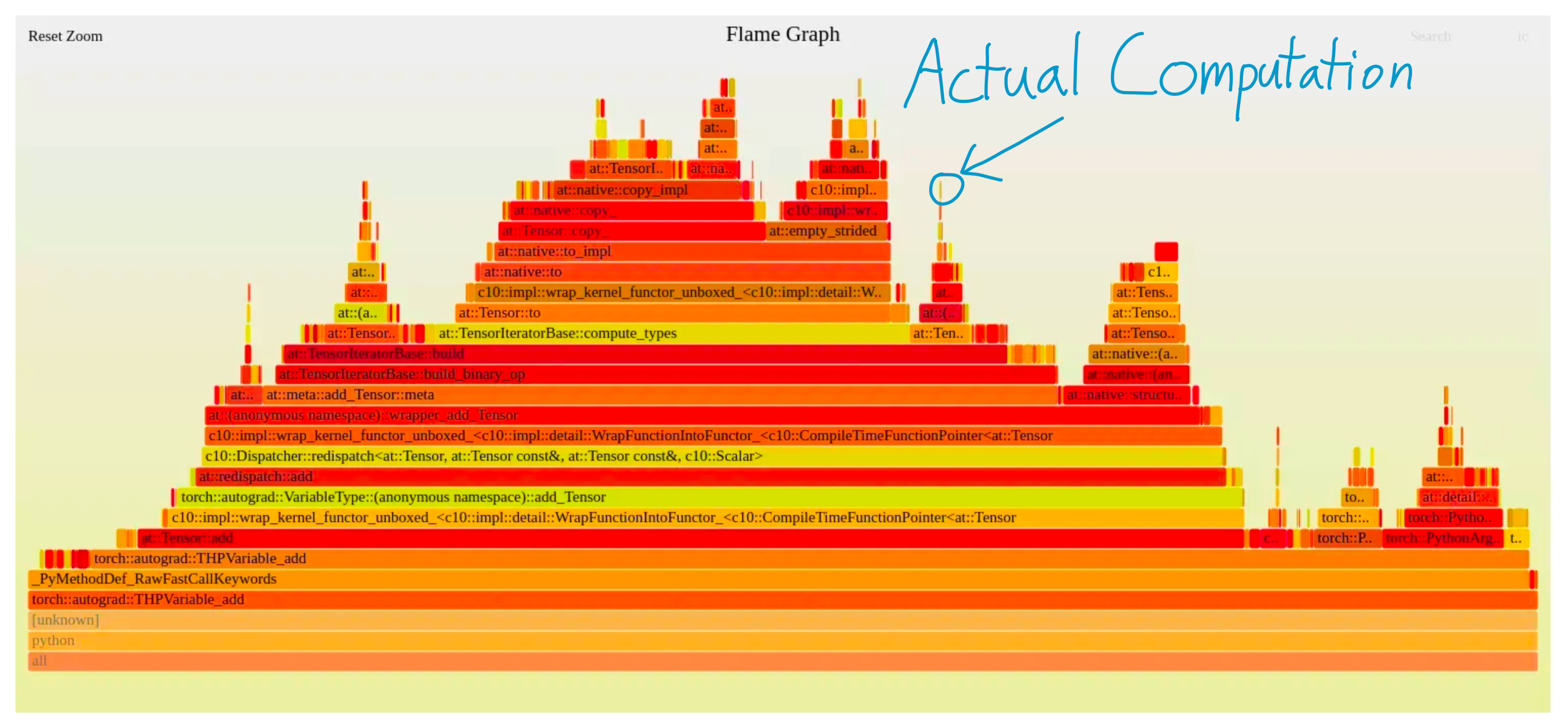
同样,你可以将深度学习机制的效率理解为包含三个不同的组成部分。
⭐计算:在 GPU 上进行实际浮点运算(FLOPS)所花费的时间
⭐内存:在 GPU 内传输张量所花费的时间
⭐开销:其他所有内容
就像训练机器学习模型一样,了解你所处的状态能让你专注于那些真正重要的优化。例如,如果你把所有时间都花在内存传输上(即你处于内存带宽受限的状态),那么提高 GPU 的浮点运算能力(FLOPS)将无济于事。 另一方面,如果你把所有时间都花在执行大块的矩阵乘法(即计算密集型模式)上,那么将模型逻辑重写为 C++以减少开销并不会有所帮助。
所以,如果你想让你的 GPU 保持高速运转,让我们讨论一下你的系统可能花费时间的三个部分——计算、内存带宽和开销。”