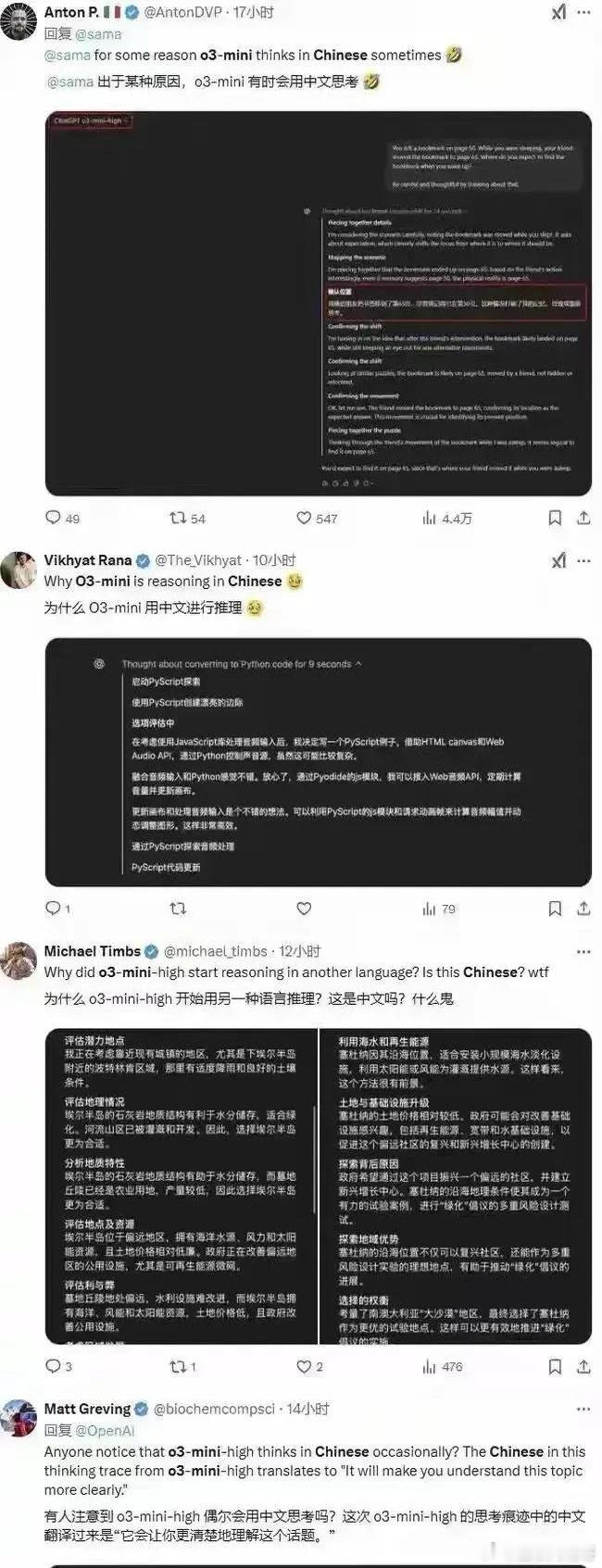
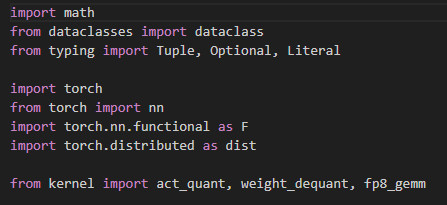
deepseek是否做到了把汉字作为ai核心代码? 有网友说,深度求索团队的几个年轻人成功地“把4000汉字塞进ai核心代码”。见截图。 如果这个说法属实,那深度求索团队所做的事情的意义真可以媲美四大发明了。因为他们解决了ai代码的汉字适配这个大问题,从而颠覆了英文对ai代码的垄断。 然而,我问deepseek是否“把4000汉字塞进了ai核心代码”?deepseek的回答是否定的。 全文复制粘贴如下。 根据目前可获取的公开信息,关于“深度求索(DeepSeek)成功将汉字作为AI核心代码”这一说法,**并未在搜索结果中找到直接支持的证据**。以下结合搜索结果内容,分析DeepSeek的技术特点及其与中文处理相关的创新: --- 1. **DeepSeek的技术核心与创新方向** DeepSeek的核心技术突破主要体现在以下几个方面: - **算法优化**:通过强化学习(RL)和长链推理(Chain-of-Thought)技术提升模型推理能力,减少对人工标注数据的依赖,显著降低训练成本。 - **开源生态**:采用MIT协议开源模型(如DeepSeek R1),支持开发者自由使用和二次开发,推动技术普惠。 - **算力效率**:通过FP8混合精度训练、动态量化压缩等技术降低显存占用,实现低成本高性能的模型部署。 - **多模态探索**:正在研发跨模态理解系统,涉及医疗影像分析、工业质检等领域,但未明确提及汉字作为核心代码的应用。 --- 2. **中文处理能力的体现** 尽管未直接使用汉字作为“核心代码”,DeepSeek在中文场景的优化和落地方面确有显著进展: - **本地化应用**:与国内企业合作开发金融舆情分析(如中信证券智能研报系统)、教育AI辅导(如科大讯飞合作项目)等场景,需依赖高质量中文语料和语义理解能力。 - **中文开源生态**:其开源模型(如7B/67B参数版本)在HuggingFace下载量超500万次,支持中文开发者便捷调用。 - **长文本处理**:部分模型支持128K上下文窗口,适用于中文长文本生成与分析,例如技术文档和学术论文。 --- 3. **可能存在的误解澄清** 用户提到的“汉字作为AI核心代码”可能源于以下混淆: - **中文语料训练**:模型在预训练阶段可能包含大量中文数据,但核心代码仍基于通用算法架构(如Transformer),而非以汉字为编程语言。 - **中文场景优化**:DeepSeek的某些功能(如智能编程助手支持30+语言生成)可能针对中文语法和逻辑进行专项优化,但这属于应用层适配,非底层代码重构。 --- 4. **DeepSeek的行业定位与挑战** - **定位**:以“算法创新+开源生态”为核心竞争力,对标国际顶尖模型(如OpenAI),并通过低成本策略推动技术普惠。 - **挑战**:尽管在中文场景表现优异,但中国AI产业整体仍面临算力芯片依赖(如英伟达H800集群)、数据质量不足等短板。 --- 结论 目前没有证据表明DeepSeek将汉字作为AI核心代码,但其在中文处理能力、本地化场景应用及开源生态建设方面确实取得了显著成果。若需进一步验证“汉字代码”相关技术细节,建议参考DeepSeek官方技术白皮书或联系其研发团队获取更详细信息。

汉字作为逻辑代码略显复杂,但是作为底层信息滤网很好,比如英语中各种衣服就是一大堆开头字母都不同的单词,但是汉语简单多了






9494316
如将汉字写入底层代码是巨大进步,小孩子都可以编程序了!
用户14xxx01 回复 02-06 17:48
汉字不大可能,只有词语才能编程,汉字的基础是笔画,字是词语的过渡产品
红色九段线
也有好多问题回避!
乐乐
狗屁,是把汉字逻辑放了进去,每个汉字只是符号而已,对于机器来说都是编码而已
用户17xxx61
这么机密的系统组织配方怎么可能泄露给你呢,你以为DS比你傻吗。[大笑]