AI视角| 最客观的DeepSeek深度解析:精打细算的王者,借米之炊的巧妇(3)
摘自蘇硯Qiantech 小签科技
大模型科普之大模型训练流程
我们来以GPT的训练阶段,来看大模型训练所要经历的四个阶段:
预训练阶段(Pretraining)
有监督微调阶段(Supervised Finetuning)
奖励建模阶段(Reward Modeling)
强化学习阶段(Reinforcement Learning)
3.1第一阶段:预训练
预训练阶段相当于就是大模型第一次获取样本学习的过程,这个过程就像我们刚进入小学阶段学习知识,训练样本的数据集(通常非常大量)就是我们的课本,把这些课本里的知识先“转化”成一个一个Token(1个Token约等于0.75个英文单词),再编码后(向量化)就成了计算机可以理解的语料,喂给大模型进行预训练,生成一个基础模型。
3.1.1“课本”由哪些组成?
通常训练样本集来源于两个方面:公开的互联网爬虫数据如网页新闻和各种刊物(70%以上)和一些更高质量的数据集如专利和论文(20%左右)。
3.1.2大模型的训练需要多少Tokens?
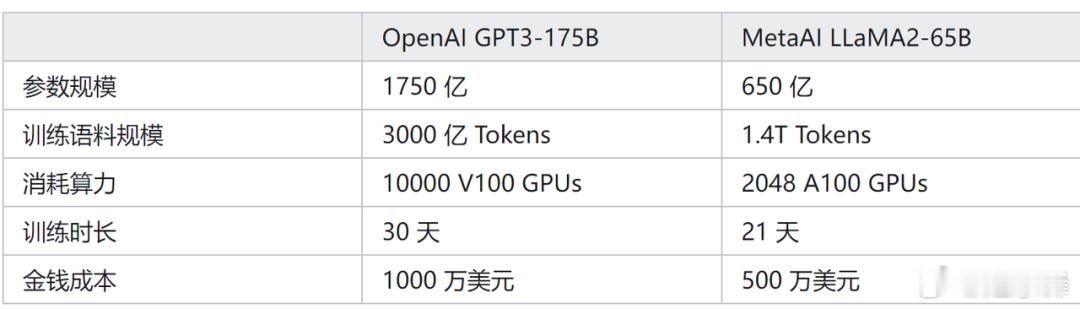
我们以GPT和LLaMA-2为例:
GPT3使用了3000亿Tokens,而LLaMA-2使用了1.4万亿tokens。
GPT Transformer 是一个拥有超大规模参数的深度神经网络模型,正是这些参数的取值(权重)组合在一起,才能输出了相应的预测结果(概率),而 Transformer 就是通过预测结果,再反向更新自己的参数权重。这个过程叫做反向传播Backpropagation,是预训练中重要的一步,也是产生最大消耗的一步,因为这种更新不是一次性完成的,而是多次迭代,逐步逼近的过程。
最开始训练的时候,大模型脑子是混乱无序的,随着多轮反向调整每个参数的权重,才开始展现出正常有序的行为,并且越来越逼近目标,降低损失值(LOSS)。由于预训练的目标是通过训练来改变模型中巨大规模的参数权重,所以现在的它非常擅长遮挡训练,即根据输入的内容预测下一个单词,有点类似我们英文考试中的完形填空。他没有办法记住之前对话的内容,也无法理解人类的对话风格,总结起来就是很书面很生硬,经常会生成逻辑不通或不合理的语句。
3.2:第二阶段:有监督微调(SFT)
于是就来到了第二个阶段:有监督微调。
有监督意思就是开始有老师(人工)介入,训练大模型的明确指令和精准回答的对话交互语料,对于模型构建提供者,尤其是垂直领域的大模型供应商来说,高质量的微调数据是非常宝贵的智力资产,在基础模型普遍开源的情况下,微调数据质量的高低往往成为影响最终模型表现的关键因素。
不知道大家还记不记得,人工智能产业背后的数据标注暗面在2018年引发重大伦理争议。当时为降低GPT模型训练成本,OpenAI通过外包渠道雇佣大量非洲数据标注员进行训练和审核,这些时薪不足2美元的"数字劳工"持续暴露在暴力、色情等有害内容中,其工作环境经媒体曝光后,OpenAI一度陷入"人工智能血汗工厂"的舆论漩涡。这些被系统剥削的标注员群体,正是塑造大模型认知能力的"人类教师"。
美国电视节目《60分钟》曝光,Meta 的分包商 Samasource 签约培训 Open AI 模型的肯尼亚人没有获得体面的报酬,并被迫在恶劣的条件下工作。
而今目前大部分这些工作已经由美国的Scale-AI公司垄断,Scale-AI是华人创办的专门为监督微调提供服务的供应商。
3.3:第三阶段:奖励建模(RM)
奖励建模是一种基于人类反馈的强化学习,当我们很小的时候,认知对错往往是依靠反馈来做,父母会告诉我们这样是对的,那样是错的,大模型也是一样,它需要精准的反馈来帮助他优化自身。
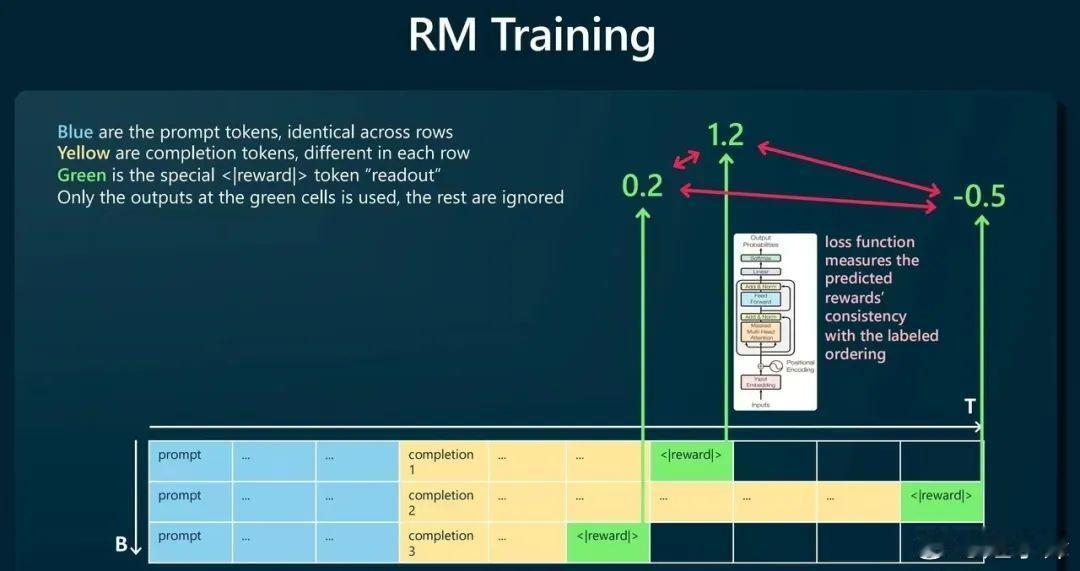
奖励模型也是一个机器学习的模型,和SFT 一样采用有监督学习方式,其数据样本标签就是这个由人类给出的评分值。在实际过程中所做的事情如上图所示,蓝色格子是输入给 SFT 模型的内容,黄色格子是 SFT 模型预测的结果,绿色格子则是 Transformer 针对 SFT 预测结果所给出的评分值。可以基于这个评分结果设计损失函数LOSS,然后通过不断降低 LOSS 来训练出符合人类要求的奖励模型。
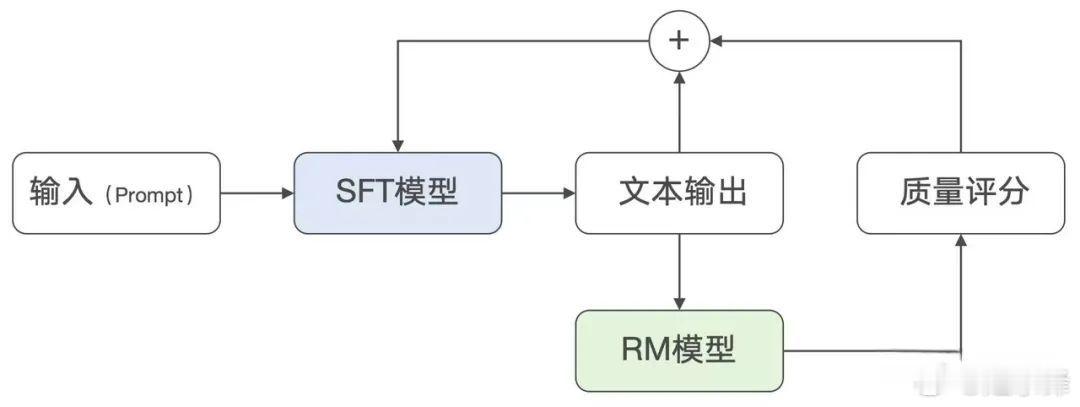
一旦构建了奖励模型,后续就可以用它来对大模型的预测结果进行有效的打分。这个阶段有点像从中学毕业迈入了大学校门的大学生,不能再指望着“被监督着学习”,而是要学会评估自己的学习情况,进行自我监督。需要注意的是,这个阶段输出的评分,并不是给最终的用户,而是在第四个阶段 —— 强化学习中发挥重大作用。
第四阶段:强化学习(RL)
这个阶段其实是一个整合的过程,针对特定的输入文本:通过有监督微调获得输出结果;基于奖励模型为多个输出文本打分;基于打分为输出文本加入结果权重,权重体现在每个Token参数中,再把最后的加权结果反向传播,对有监督微调模型参数的权重进行调整。这一系列操作下来就形成了强化学习。简单理解就是通过评分再优化输出方式,让大模型知道什么是好的,被鼓励的,不断朝着考高分的目标去优化自身。