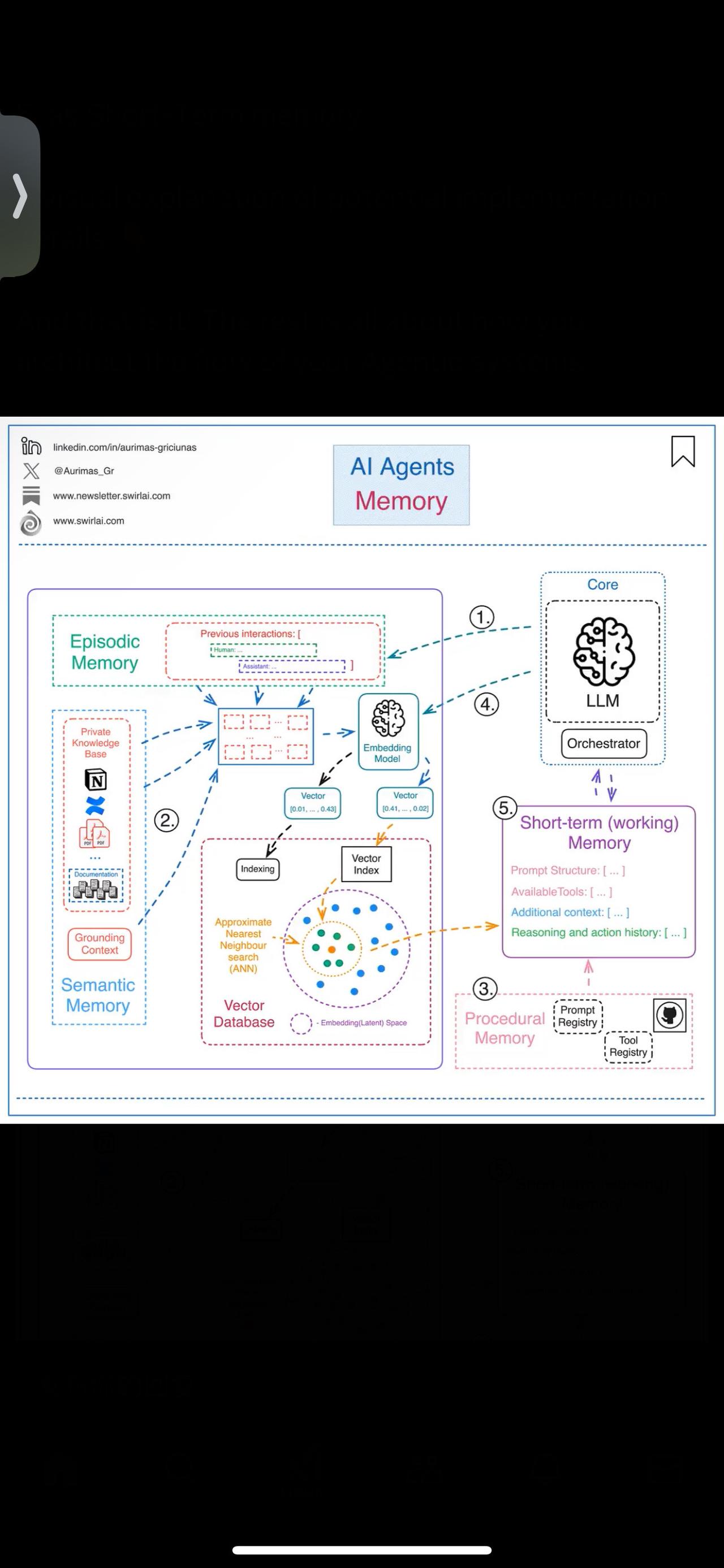
解释人工智能代理内存的简单方法。 一般来说,代理的内存是我们通过传递给LLM的提示中的上下文提供的东西,这有助于代理更好地计划和做出反应,因为过去的交互或数据不能立即可用。 将内存分组为四种类型是有用的: 1.剧集-这种类型的记忆包含代理人过去的互动和操作。执行操作后,控制代理的应用程序将将操作存储在某种持久存储中,以便在需要时稍后检索。一个很好的例子是使用矢量数据库来存储交互的语义含义。 2.语义-代理可获得的任何外部信息以及代理应该拥有的关于自己的任何知识。您可以将此视为类似于RAG应用程序中使用的上下文。它可以是只有代理才能获得的内部知识,也可以是接地上下文,以隔离部分互联网规模数据,以获得更准确的答案。 3.程序性-这是系统性信息,如系统提示的结构、可用工具、护栏等。它通常会存储在Git、Prompt和Tool Registry中。 4.偶尔,代理应用程序会从长期内存中提取信息,并在手头任务需要时将其存储在本地。 5.从长期提取或存储在本地内存中的所有信息被称为短期或工作内存。将其全部编译成一个提示将生成要传递给LLM的提示,它将提供系统要采取的进一步行动。 我们通常将1.-3标记为长期记忆,5.标记为短期记忆。 对潜在实施细节的直观解释👇 就是这样!其余的都是关于你如何构建代理系统的流程。 你对人工智能代理中的内存有什么看法? LLM AI 编程严选网 想学习如何在没有任何LLM编排框架的情况下从头开始构建代理吗?软件开发