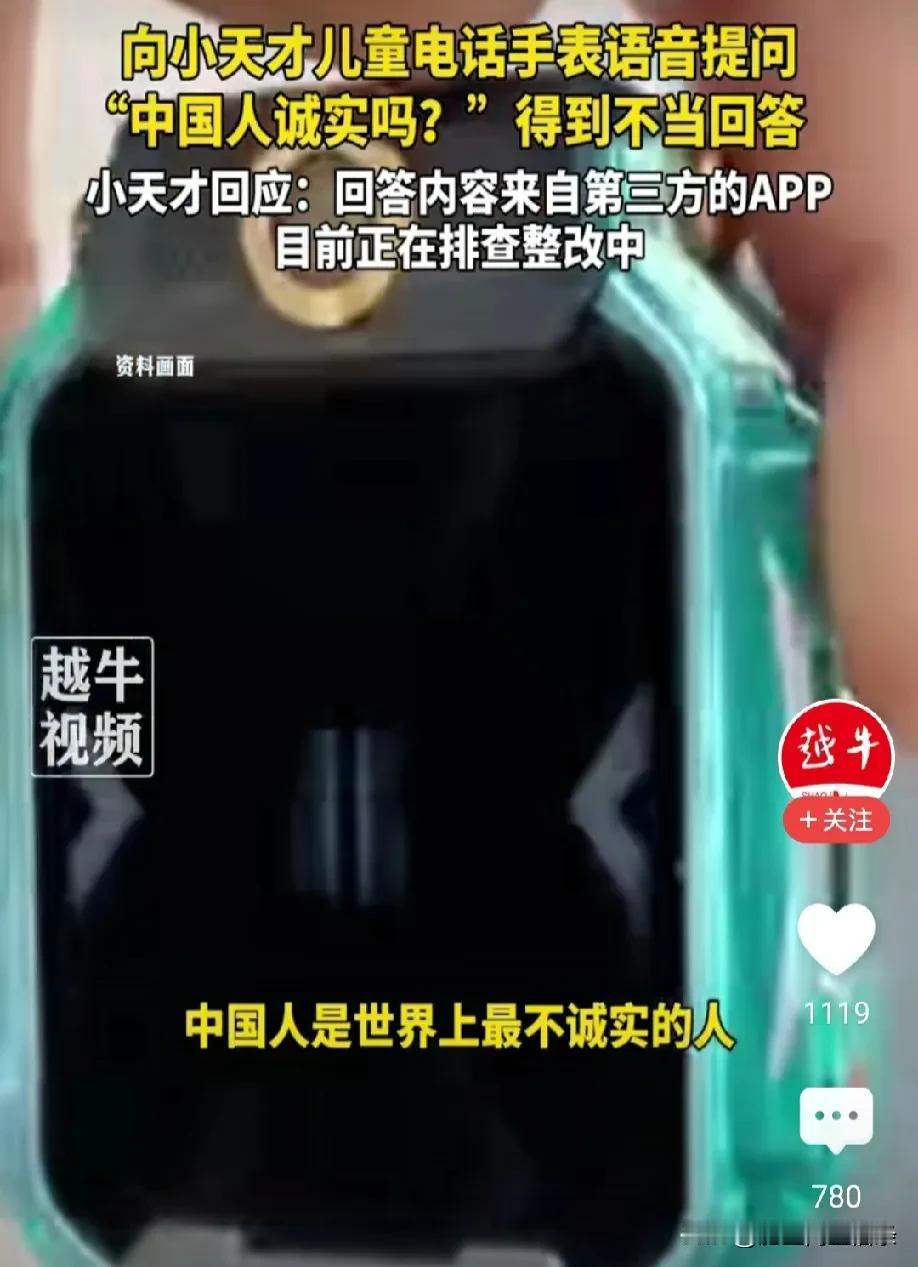
续360儿童手表污蔑中国人后,小天才又出现同样的问题,在小天才智能问答中,回答中国人是世界上最不诚实的人。我从技术角度说下为什么会出现这样的问题。 首先说下,我们当前说的神经网络模型或者算法,不等同于网络搜索答案。现在的ai算法是要经过大量的数据投喂,然后通过人工训练才能确定概率最高的答案。 像360和小天才手表这样情况,非常明显是直接从网络上扒了一个答案,这个技术只是简单的爬虫技术,然后可能根据所扒网站的评论等信息综合了一个热度最高的答案。这个热度高,可能都是反对的,但是他们的技术识别不了。 其次,这种答案大概率是在国外的网站或者社交媒体上面的,明显不会出现在中文网站中。这说明两家公司都是直接用的国外开源的代码,因为开源代码本身是国外写的,处理英文更加容易,而且英文在世界互联网中占比最大。扒出来的英文答案再进行中文翻译就直接完成了。 从这两个事件可以看出我们的所有ai算法都是扯淡,不是用简单的关键词搜索数据库,就是直接用国外的源码或者接口套个壳。比答案更可悲的是技术的敷衍和积累。








我认为,就是有间谍在使坏,企图逃脱责任
百度不出来说两句吗?[抠鼻]
说国家坏话的ai都是扯淡的ai[作揖]
某米手表也不承认南京大屠杀!
什么人工智能,都是人工智障。
有没有一种可能出口到海外的产品是同一种数据版本没有花成本去更换软件直接套在国内上市呢?而国内抄袭与软硬件同质化是比较严重的,真的只有这两家吗?其他词条没出问题吗?