文:回溯档案
编辑:回溯档案
植物开花是植物生长过程中最重要的过程之一,它反映了从营养生长到生殖生长的转变,并影响作物产量和对各种环境的适应性,因此,开花模式的特征不仅有助于研究对被子植物遗传和生理学的理解,而且还有可能有助于培育新品种,以实现最佳产量和环境适应性。
而高通量植物表型(HTP)的进步和深度学习的突破,在田间快速表征植物的开花模式成为可能,在一些研究表明中,使用深度卷积神经网络(CNN)和元模型

尽管这些研究取得了相对较高的计数准确性(R2>0.92),它们主要用于产量估算的“一次性”测量,开花表征的一大挑战是,在许多植物中,它发生在很长一段时间内,需要人们经常检测和计算植物上新开放的花朵。

在深入研究了基于深度学习的花卉检测和计数解决方案中,以用于小麦,玉米,高粱,水稻和棉花等试验,在试验中根据计数策略,这些方法可分为三类:基于回归的计数、基于分类的计数和基于检测的计数。
基于回归的计数是一种单阶段策略,它使用 CNN 提取特征,以直接回归图像中花朵/花卉结构的连续计数,基于分类的计数是一种类似的策略,不过它将图像分类为表示离散计数/花朵结构百分比的类。

这两种计数策略大大降低了训练复杂性和数据注释的成本,在实验中表明,它们可以提供相当好的计数精度(高达90%),然而基于回归和分类的方法可能会遇到过拟合问题,而CNN模型通常比训练目标(一个数值或几个类)复杂得多。
此外,无法从回归/分类结果中获得花朵/花结构的空间信息,这限制了花分布分析和基于致动的应用(如作物负荷管理中的花朵疏伐)的潜力,为了解决或缓解这些问题,最近的研究使用了基于检测的计数策略。

基于检测的计数是一种两阶段策略,用于检测图像中的花朵/花卉结构,然后计算检测次数,一项研究报告称,基于检测的计数可以比基于回归的计数提供更好的计数准确性和稳健性,这表明基于检测的花卉生长季节计数策略的伟大之处。
在过去两年的许多花卉检测和计数研究中,只有三项使用开发的计数方法来监测整个开花期的植物开花情况,以表征关键的开花模式,之后所有三项研究都表明,由于深度学习模型在花卉检测和计数方面的卓越性能,抽头日期估计的准确性很高(误差最多为2天)。

另一方面,只有少数研究能够监测植物开花,这重申了在很长一段时间内进行密集数据收集和分析以表征开花模式的挑战。
同样值得注意的是,几乎所有的研究都集中在具有简单芽结构的作物上,其中花朵/花结构在植物冠层顶部形成,这大大简化了数据收集以及花卉检测和计数,相比之下,棉花植物具有更复杂的芽结构,并且可以在整个植物中形成花朵,这对棉花花的检测和计数提出了极大的挑战。
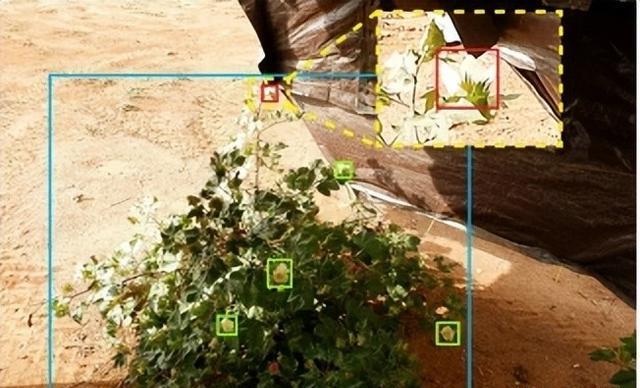
迄今为止,只有一项研究报告了一种两阶段方法,从航拍图像中检测和计数棉花地块中的花朵(白色花朵),该方法首先使用阈值方法分割水华的候选区域,然后使用自定义CNN将候选区域分类为开花或非开花,以计算单个棉花样地中的花朵数量。
尽管两阶段方法在计算水华数量方面取得了一些成功,但它有一个主要限制,即由于遮挡,相当一部分水华无法通过航拍图像捕获,导致对水华计数的低估相对较大,此外,这项研究只测量了几天的开花次数,缺乏在长花期内进行开花模式分析的能力。

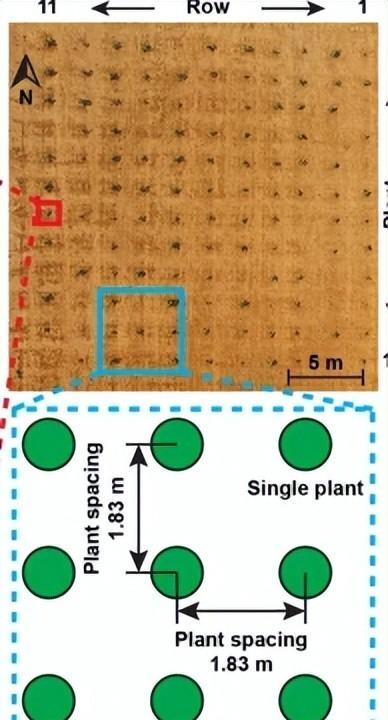
为了克服上述限制,我们需要在技术和农艺方面进行改对于技术方面,有必要探索使用侧视近端成像和基于CNN的物体检测来检测和计数整个花期的单个花朵,对于农艺方面,种植方案需要从传统的基于地块的布局修改为单株布局(SPL),其中单个植物被视为行距为1.52 m的地块。
通常,更快的RCNN模型(FrRCNN5-厘升)可以准确检测不同光照、水华负荷和遮挡条件下的植物和新出现的水华,如果使用适当的视角,外壳大多提供均匀明亮的照明。

照明可能是一个问题,因为外壳没有完全覆盖成像区域。当太阳天顶角陡峭或摄像机配置为面向外壳入口时,摄像机的视野(FOV)可以包括阴影和强照明。
然而,FrRCNN5-cls模型无法处理某些情况,叶片的远轴表面比近轴表面具有更高的反射率,显示出与新兴花朵相似的对比模式(比相邻区域更亮),当叶子的远轴表面暴露在相机下并被苞片包围时,即使通过人类观察也无法轻易将这些叶子与真正的新出现的花朵区分开来,从而产生对新兴水华的假阳性检测。

此外,由于高反射率,在强光照下出现的花朵失去了与背景和细节纹理的对比度,因此在图像中变得更加难以识别,在这种情况下,FrRCNN5-cls模型无法准确检测到新兴的绽放物体。

总体而言,该模型(FrRCNN5-厘升)使用5类标记策略训练的性能(平均平均精度,mAP和每个类的平均精度,AP)比(FrRCNN3-厘升) 使用 3 类标记策略进行训练.特别是采用3类标注策略,新兴布隆检测的AP提高了5%。与3类标注相比,5类标注策略可以更有效地拆分外观相似的类。
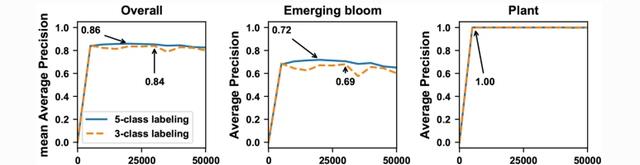
因此,类内的差异将小于类之间的差异,从而为训练深度神经网络提供好处。例如,可能有几种类型的非泛光对象具有不同的外观,植物枝条和叶子之间也有一些明亮的间隙,这些间隙形成了与新兴花朵外观相似的区域,而还有一些其他物体。
值得注意的是,即使使用0类标记策略,水华类的AP得分为72.5,这意味着模型可以将不相关的区域检测为水华,并导致过度检测问题。因此,通过使用高分类置信度评分,我们希望缓解此问题并为水华计数提供准确的检测结果。
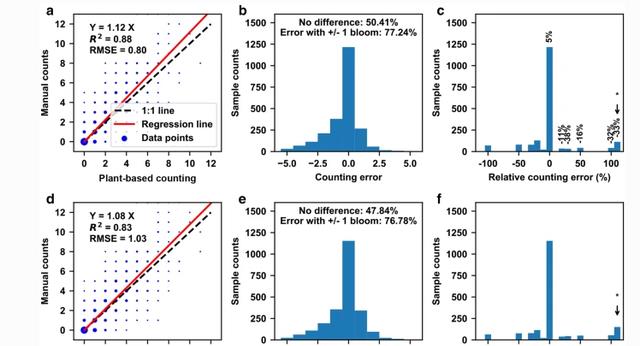
虽然 FrRCNN5-厘升和“基于植物的计数”策略分别在新兴水华检测和计数方面表现出更好的性能,通过联合使用FrRCNN识别出显着的计数错误5-厘升以及作为计数方法的“基于植物的计数”策略. 对于绝对计数,FrRCNN 的组合5-厘升模型和“基于植物的计数”策略为每天出现零到四次水华的植物(大约82%的病例)提供了准确的测量结果(少于一次水华)。
然而,当植物有五个或更多新开花时,绝对计数误差明显增加(大约18%的情况),以平均而言,开发的计数方法也达到了每株植物,每天6次开花,因此,当植物达到开花高峰期(每天超过10次出现花朵)时,绝对计数误差为每株植物每天超过4次开花,相当于约50%的相对计数误差。

这主要是因为发达的计数方法中的假设,即来自特定视角的单个图像,将在一天内捕获植物上大多数(甚至所有)新兴的花朵,因此计数方法可以从单个植物的四张图像中的一个中获得最大开花数。
这种假设在开花阶段通常成立,当时植物每天有少量的新兴开花,因此计数方法为大多数植物提供了准确的计数,然而,在植物每天有大量新花的开花高峰期,这一假设是无效的。
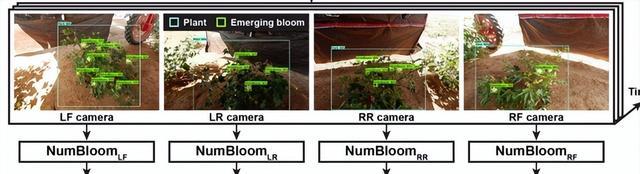
此外,新兴水华分布在植物冠层周围,因此从任何视角拍摄的单个图像都不足以捕捉植物上的所有水华,从而导致对绝对水华数量的严重低估。
开花特性
使用开花期间每株植物每天出现的开花次数来推导出单个植物的开花曲线. 开花曲线定义为生长时间内开放花朵的累积百分比(以DAP为单位),使用公式1计算个别日子开放花朵的累积百分比。
在开花曲线上定义了三个关键点,包括确定第一次开花时的首次开花日期(FBD)、至少5%的新兴开花发生在植物上的开花开始日期(FSD)和至少95%的新兴开花发生在植物上的开花结束日期(FED)。
从三个临界点推导出三个开花特征。FBD和FSD直接用作开花特性,而FSD和FED用于计算开花持续时间(FD),这对于许多与改善环境适应性相关的应用非常重要。

结论
地面移动系统(GPhenoVision)被修改为多视图彩色成像模块,以一次从四个视角获取植物的图像,在大约116个月内,来自23个基因型的2株植物共成像,平均扫描间隔为 2-3 天,产生包含8666张图像的数据集。
回归分析表明,深花法可以准确(R2= 0.88和RMSE = 0.79)检测和计数棉花植株上新出现的水华,统计分析表明,成像衍生的开花特征在识别遗传类别或基因型之间的差异方面与人工评估具有相似的有效性。
因此,所开发的方法可以成为表征具有复杂冠层结构的开花植物(如棉花)开花模式的有效工具
参考文献
