
「特斯拉端到端智驾方案到底是怎么做的?」
在一次端到端智能体研讨会上,有人向一众端到端专家学者们抛出疑问。
现场包括赵行(清华交叉信息研究院助理教授)、许春景(华为车 BU 智驾 AI 首席科学家)、王乃岩(小米智驾杰出科学家)、贾鹏(理想算法研发副总裁)这些学界、业界人士在内,没人能给出确切回答。
没有人清楚,特斯拉 FSD V12 具体模型架构是怎样的,但特斯拉就是凭一己之力,搅动了端到端的潮水。
我们试图从马斯克发言和特斯拉动态中拼凑出特斯拉端到端的大致体征:从感知到决策由统一神经网络控制,很大可能基于生成式 AI,在原有 Occupancy 模型基础上构建世界模型。
但从中捕捉的确定性是,端到端方案对于云端算力的需求来到一个新高潮。
正如马斯克多次表示:「FSD V12 端到端模型迭代主要受到云端算力资源的掣肘。」
于是,特斯拉选择重金堆算力,计划 2024 年底前对 DOJO 超算中心投资超 10 亿美元,目标是总算力提升至 10 万 PFLOPS。
如果说算力是端到端的必要条件,那这意味着,端到端正在掀起新一轮军备竞赛,赢家往往是大力出奇迹者。
同时,正如无人知晓特斯拉端到端具体如何实现一样,大家只是瞄准了潮水涌动的方向,一股脑向那涌去。
于是,忽如一夜春风来,端到端方案遍地开,谁都跟紧节奏,不想因此出局。
01、端到端智驾,大「力」才能出奇迹
端到端智驾,基于 AI 模型化的主路径,对其训练算力资源的超大需求,势必助长了算力燃烧的火焰。
智算中心进入了跑马圈地时代,一场关乎算力的竞赛就此展开。

这边,特斯拉、长安、吉利等车企都不遗余力地筹备智算中心,或选择自建,或选择与第三方合作。
特斯拉的 DOJO 智算中心,预计到 2024 年 10 月,总算力将达到 100EFLOPs(10 万 PFLOPS),相当于约 30 万块英伟达 A100 的算力总和。
国内车企也在算力上奋力追赶,吉利、长安,以及新势力「蔚小理」,都没掉队。
值得一提的是,蔚来与腾讯合作建立智算中心,虽然暂未公布其超算中心的具体实力,但李斌曾用「丧心病狂」一词来形容蔚来在算力方面的布局,并称在未来一两年内都还会是全球天花板。
那边,以华为、商汤绝影、毫末智行为代表的智驾供应商,也丝毫不占下风。
华为车 BU 云智算中心的乾崑 ADS 3.0,在算力方面已达到 3500PFLOPS,训练数据量为日行 3000 万公里,按照全球道路总长约为 6400 万公里计算的话,2.1 天系统就能完全覆盖。
而商汤科技在最新财报中显示,其智算中心 GPU 数量达到 4.5 万张,总体算力规模为 12000PFLOPS,相较于 2023 年初提高了一倍。以及毫末智行联合火山引擎推出的智算中心「雪湖·绿洲」,算力高达 670PFLOPS。
显然,智算中心的建设已成为端到端自动驾驶的标配,对于算力的需求正在以一种倍极速率疯狂增长。
「没有智算中心的端到端智驾企业是不合格的。」毫末智行一位专家直言,算力越多,对模型的迭代效率、迭代方式速度,以及各种情况的修复效率,均有大幅提升。
商汤绝影智能驾驶副总裁石建萍也表示,高算力,意味着它所容纳的应用空间是广泛的,它允许更多的尝试、试错发生,那么就更有可能研发出性能更强的端到端模型。
那这是否意味着实现端到端智驾,必须大力才能出奇迹?
有意思的是,针对这个答案,行业呈现了两种发展路径:
一面是倾向于重投算力的「暴力计算」;另一面是深耕算法的「工匠主义」。诚然,行业对于智驾三要素(算法、数据、算力)的共识是三者相辅相成,任何一个出现短板,都会引发水桶效应。
但在此基础上,三个长板,哪方面现在需要重点强化,则出现了一些分歧。
暴力计算者认为,现在各家算法其实没有本质区别,核心点在于把数据在超算中心中如何高效训练起来。
一位行业人士就指出,在学界已经公开了可行的端到端算法架构,甚至不断更新前沿进展的情形下,业界完全可以参照学界的研究成果进行量产、落地实验,那么这就要求其现阶段在算力基础、数据规模上积攒足够实力。
但也有另一种声音夹杂在其中。他们认为,实现端到端智驾,深耕算法是当前更为紧迫的突破方式。
元戎启行就对汽车之心表示,算力中心比拼只是一方面,但现阶段更重要的是打造一套满足 Scalling law 的网络模型。
Scalling law 即规模定律,随着模型规模的增加(包括参数数量、数据规模和计算资源),模型的性能也会相应提高。
也就是说,想要规模定律生效,需要先谋定的是模型优化问题,这才是后续大力出奇迹的发力点所在。
说到底,两种路径无关绝对优劣之分,毕竟各家的端到端战略规划、资本实力各不相同。
但从特斯拉、华为等头部车企都重投超算中心的动作评判,算力愈高,端到端智驾效果的天花板的确会随之抬高,也就是上限会有所提升。
那么,超算中心到底多大的算力能够支撑起端到端智驾?
在辰韬资本发布的《端到端自动驾驶行业研究报告》(以下简称「报告」)中显示,大部分公司表示 100 张大算力 GPU 可以支持一次端到端模型的训练,但这大概率支撑不了方案走到量产阶段。
毫末智行认为,基于算法需要不断迭代,端到端起步需要 1000 张 GPU。
但至于上限如何衡量,却没有定论。
行业一致认为,量力而行。毕竟巨头特斯拉横亘在众多选手面前。

据悉,特斯拉今年计划将英伟达 GPU H100 增加至 85000 张以上,达到和谷歌、亚马逊同一量级,这是国内企业望尘莫及的程度。
毕竟,一张 H100 目前售价在 2.5 万-4 万美元之间,相当于特斯拉今年至少要投超 20 亿美元。
没有雄厚家底,这不是谁都「玩」的起的。因为特斯拉的使命在于具身智能的全球化,其目标还包括 Robotaxi、智能机器人等,解决问题的难度涉及到一个新的阶层。
因此,特斯拉这般大动作,是基于财力、目标、数据规模的适配,其它企业没必要向它看齐,追求一味的超高算力。
对于国内智驾企业而言,眼下目标是解决城市 NOA 量产落地,实现高阶自动驾驶。
毫末智行表示,要实现全国都能开,2000-5000 张 GPU 已经足够。
但随着目标的不断进阶,从 L2 到 L3、L4,甚至 L5,算力需求将会继续水涨船高。
无论如何,端到端的浪潮,的确推动了一场新的洗牌运动,无论是数据规模、算法结构还是算力要求,都将掌握技术核心的企业洗到了最前面。
02、端到端迷局:谁才是真端到端?
端到端热潮正在造就新一场网络迷因。
谁都想搭上端到端的快车,就算技术没跟上,宣传高地也必须占领。
有意思的是,在「你也是端到端,我也是端到端」的情形下,很难把真伪的泡沫戳破。
究其根本在于,端到端实现路径尚未统一,各家都有发言权。
现在对于端到端的定义可以区分为广义与狭义。
广义强调端到端是信息无损传递,不因人为定义接口产生信息损耗,可以实现数据驱动的整体优化。
而狭义的端到端只强调从传感器输入到规划、控制输出的单一神经网络模型。
也就是说,只要满足广义标准,都能称之为端到端,因此能看到各家端到端智驾企业,从输入到输出的实现形式具有差异化,现在主流方案有以下三种:
一是感知认知模型化。将大模型拆分为感知与认知(预测决策规划)两个阶段,串联二者做训练。以华为乾崑 ADS 3.0 为代表,其感知部分采用 GOD 大感知网络,认知部分采用 PDP 网络实现端到端一张网。
二是模块化端到端。将智驾的所有模型串联在一起,用高端的方式统一训练。以 OpenDriveLab 的 UniAD(2023)为代表,通过跨模块(感知预测规划)的梯度传导完成全局优化。
三是单一神经网络。也就是狭义端到端概念。用一整个囊括输入到输出端的大模型,直接进行训练。以 Wayve 为代表,其生成式世界模型 GAIA-1、视觉-语言-动作模型 LINGO-2 可能是未来 One Model 端到端的重要基础。
值得一提的是,要跟紧端到端潮流的转向,站在传统规则算法之上的企业一时无法推翻重来,于是他们遵循了一条递进式的技术路径。
报告中也明确标明了自动驾驶架构演进的四个阶段:感知「端到端」、决策规划模型化、模块化端到端、单一模型(One Model) 端到端。
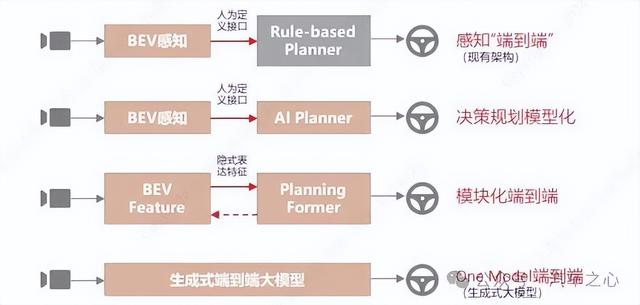
图源:辰韬资本《端到端自动驾驶行业研究报告》
也就是说,从感知端模型上车,再进行规划模型化,最后串联起来做端到端训练。这是一种相对平滑的过渡形式。
蔚来智能驾驶研发副总裁任少卿同样认为,自动驾驶的大模型需要拆解成若干个层级,第一步是模型化,行业基本完成了感知模型化,但是规控模型化方面头部公司也没有完全做好,第二步是端到端,去掉不同模块间人为定义的接口,第三步是大模型。
当然,通往端到端的路径既可以平滑过渡,也可以推倒重来。
小鹏就在 AI DAY 上就强调自己卸下包袱,落地端到端大模型。
毫末也提到,「如果具备足够勇气和决心去重构一套系统,效率可能会更高一些。」
所以选择何种路径,何种方式,全凭自家结合实际条件考量。
但综上来看,由于各家实现路径、实现进度、宣传力度均不一致,的确造就了端到端众说纷纭的迷局。
一个尴尬点是,当尝试从一些明显特征判别真伪端到端时,会发现都行不通。
比如 BEV+Transformer 架构,很多企业将其视为感知模型化的标配,但这不代表一种绑定关系。只能说,这是当下在感知模型上一种较好的实现方式。
以及特斯拉的纯视觉路线,与华为的激光雷达融合路线,都可以称为端到端,这仅是不同企业的路线选择。
尽管有企业强调,不摆脱高精地图,无法做端到端模型。
但更多声音还是更倾向于二者之间没有绝对联系。
石建萍强调,去高精地图,不是端到端的一个前提条件。尽管现在商汤做到了「无图」,但为了交互更友好,也准备把导航地图加进去。
尤其,结合模型训练复杂性、量产落地的安全性、端到端方案成本等多因素考量,纯视觉还是激光雷达路线,都是各家企业的技术选择。
而这些无法论证端到端的根源在于,端到端智驾强调的是结构上的梯度可传导以及全局优化,这仅是一种训练方式。
它会经常和另一个词「大模型」混淆在一起。
行业人士都一致指明,这是两个不同维度的概念,大模型关注的是模型的参数数量以及涌现能力。目前大模型为端到端实现提供了解决方案,但端到端并非必然基于大模型实现。
那么,回归到最初的疑问,真假端到端到底怎么看?
答案是,要么扒代码,要么看体验。
前者看它代码到底怎么编写,是否完成了从输入到输出的信息无损传递。显然,这不太现实。
后者则是到落地验证阶段,判断其智驾水平是不是像「老司机」,能处理各种 Corner case。这是唯一可靠的辨别方式。
有行业人士表示,「端到端方案做出来后,自动驾驶水平会有明显飞跃,如果效果差不多,那说明端到端方案是假的。」
03、端到端不一定是最终解,但是现今最优解
从上海人工智能实验室发表的 UniAD 获得 CVPR 2023 最佳论文,到特斯拉 FSD V12 的问世,再到智驾企业 Wayve 获 10 亿美元融资,在学界、业界、资本的「共谋」下,端到端智驾开启了新一轮产业革命。
英伟达汽车事业部副总裁吴新宙认为,端到端正是智驾三部曲的最终曲。
小鹏 CEO 何小鹏也直言,端到端将对智驾带来颠覆性变革。
不过,在端到端智能体研讨会关于端到端 VS 传统模块化的圆桌辩论中,最后结论却是端到端设计并未完全碾压传统模块化设计,这其中依然存在关于验证、落地、量产的冷思考。
所以只能说,端到端不一定是靠近智驾终局的最终解,但目前来看是最优解,它能够处理传统路径难以解决的极端案例,并且代表了一种减少人工编码依赖,更高效的思路。
基于这个路径,或许能够通往智驾的更高阶段。
现在,包括学界、车企、智驾供应商在内,所有人都朝向端到端这个方向奔去。
从主体细分,三者在端到端智驾发展路径中的侧重点与分工角色还不太一样。
学界侧重算法架构和技术路径的探索,正如上海人工智能实验室开源的 BEVFormer 架构,是当下通用的视觉感知算法结构;以及清华 MARS Lab 最早发表了「无图」自动驾驶方案,实现了自动驾驶地图的记忆、更新、感知一体化。

学术思想的迸发被投射到业界,进而推动了技术的落地与发展方向。比如清华 MARS Lab 的 BEV 检测算法、BEV 跟踪算法等,就在理想汽车的产品中广泛应用落地。
不过链接商业端的智驾供应商与车企,考虑更多的除了方案的系统性、落地可行性,更重要的,是在时间竞赛中抢占上风。
目前,诸多智驾供应商于近两年都推出了自研的端到端量产方案。
去年 4 月,毫末智行发布智驾生成式大模型 DriveGPT(雪湖·海若),这是实现端到端智驾的重要技术载体。
截至今年 5 月,搭载毫末 HPilot 智驾车辆超过 20 款,用户辅助驾驶行驶里程突破 1.6 亿公里。
小马智行也于去年 8 月推出端到端智驾模型,已同步搭载到 L4 级自动驾驶出租车和 L2 级辅助驾驶乘用车。
今年 4 月,元戎对外展示了即将量产的高阶智驾平台 DeepRoute IO 以及基于 DeepRoute IO 的端到端解决方案。
同个时段,商汤绝影推出面向量产的 UniAD,实现去高精地图,同时还发布了下一代智驾技术 DriveAGI,是基于多模态大模型打造的自动驾驶解决方案。
显然,端到端量产落地,已经箭在弦上。
尤其是在特斯拉 FSD 释放入华信号后,车企们更是坐不住了。
小鹏在 5 月份就宣布端到端方案量产上车,蔚来、理想也于今年上半年加紧推动端到端模型上车计划。
不过,2024 年只能勉强称之为端到端量产落地元年,真正的大范围上车预计在 2025 年。
商汤绝影表示,端到端更合理的落地时间在明年下半年,能够达到一个量产导入状态。因为端到端技术方案想要成熟上线,需要经过大量可靠性验证。
一位端到端行业人士也指出,「端到端上车,说上肯定能上,但上完之后到底有什么效果是另一回事,如果想要达到特斯拉这般效果,今年之内还是非常困难。」
但无论如何,端到端的确掀起了新一场检验智驾实力的竞赛,而现在竞赛来到了下半场。
学界、业界在赛跑的同时,也在相互助力,一同探索端到端的落地阶段。
目前来看,探索方向呈现三大趋势,主要对应的是端到端落地三大挑战,即:
端到端如何控制成本?端到端如何应对黑盒问题?端到端落地如何进行标准化验证?一是端到端的优化。
端到端作为一个新技术路径,大算力、大数据、大算法的高需求,构建了玩家的高门槛。大多数企业难以有特斯拉的决心与实力,投入十亿,甚至百亿美元 All in 端到端。
更何况,考虑到新事物的试错成本,在算法架构上,需要有意斟酌,如何平衡效率与成本。
据 Momenta CEO 曹旭东介绍,Monmenta 的思路是把端到端架构分为两条支路,即一条是端到端大模型,类比人的长期记忆;另一条支路是感知、认知阶段,类比人的短期记忆。
通过短期记忆形式先验证方法正确性与数据有效性后,再转移至端到端大模型的支路上,保证高效训练。相比直接应用端到端模型,这种技术方式的训练成本能缩小 10-100 倍。
二是端到端的兜底。
端到端智驾相当于类人驾驶,但真正到了落地,还存在黑盒子的不可解释性问题亟待解决,尤其面对国内复杂的城市路况,安全性难以得到完全保障。
比如理想推出了一套双系统方案对端到端兜底。系统 1 采用端到端,对应正常的驾驶能力;系统 2 承载了 VLM 模型,对应泛化能力。
这相当于,系统 1 只需处理简单的路况问题,而对于复杂的逻辑推理、未知问题,系统 2 可以解决。这套体系能够提升大模型的空间理解能力,并规避大模型的推理速度问题。
三是端到端的验证。
端到端方案的落地,首先要经历成熟的验证方式。但直接实车验证显然成本过于高昂,而基于数据回灌的开环测试条件(离线数据回归测试),与端到端智驾验证需要的可交互性并不匹配。
因此,基于模拟器实现模型的闭环测试验证,成为了当下验证的可行路径。报告指出,闭环仿真工具的研发是端到端上车的必要条件。
目前行业在积极开展闭环仿真工具的探索:
学术界普遍采用 CARLA 作为端到端开发的闭环仿真模拟器;智驾生成式 AI 企业光轮智能结合生成式 AI,开发出针对端到端算法研发的数据与仿真全链路解决方案;以及另一家同类型企业极佳科技,也打造出一套被称为世界模型的多模态视觉生成大模型。尽管端到端落地的「门前雪」还未扫净,但行业对于端到端的信心已经到达一个至高点。
毕竟,端到端的出现,让人工智能领域从由「规则驱动」为主导,跨越到以「深度学习」为引擎,这代表了一种技术鸿沟式的飞跃。
智能驾驶,毫无疑问地成为物理世界中,率先体验并展示这一变革的重要端口。
