
建设10万卡集群的必要性不言而喻,当前AI公司第一梯队的门票已经是3.2万卡集群。预计明年,这一数字将上升至10万卡(H100)集群,提升空间巨大。
由10万张H100构成的AI集群,其功耗高达150MW,投资超过40亿美元(约300亿人民币)。每年耗能约为$1.59\times10^9$千瓦时。按照0.078美元/kWh的费率计算,每年电费高达1.24亿美元。这一数字令人瞠目,足以引发对能源消耗和成本效益的深入思考。
挑战(1)能源跟空间挑战算力瓶颈的背后,有着“能源”和“工程能力”这两座大山。
"10万块H100构成的集群,功率需求高达150MW,超越了目前世界最大的超级计算机El Capitan的30MW,后者的功率仅为前者的五分之一。"
在H100 Server内部,每块GPU的独立功耗约为700W。为满足其运行需求,大约需要575W的电源来驱动与之配套的CPU、网络接口卡(NIC)和电源单元(PSU)。
H100 Server外部,AI集群还囊括了存储服务器、网络交换机、光收发器等许多其他设备,约占总功耗的10%。
X.AI 将田纳西州孟菲斯市的一家旧工厂改造成了数据中心,每天消耗100万加仑水和150兆瓦电力。目前世界上还没有任何一座数据中心有能力部署150MW的AI集群 。
这些AI集群通过光通信进行互联,而光通信的成本与传输距离成正比。
多模 SR 和 AOC收发器的最长传输距离约为50米。
在数据中心的世界中,每栋大楼都被赞誉为一个“计算岛”。这些岛屿内部充满了多个“计算仓”,它们之间的连接是通过经济实用的铜缆或者多模互联实现的。而为了实现这些岛屿之间的联通,我们采用长距离的单模光通信技术。这种方式不仅高效,而且能够确保数据的稳定传输,从而满足现代数据中心对高性能和可靠性的需求。
由于数据并行相对的通信量比较少,因此,可以跑在不同 计算岛之间:
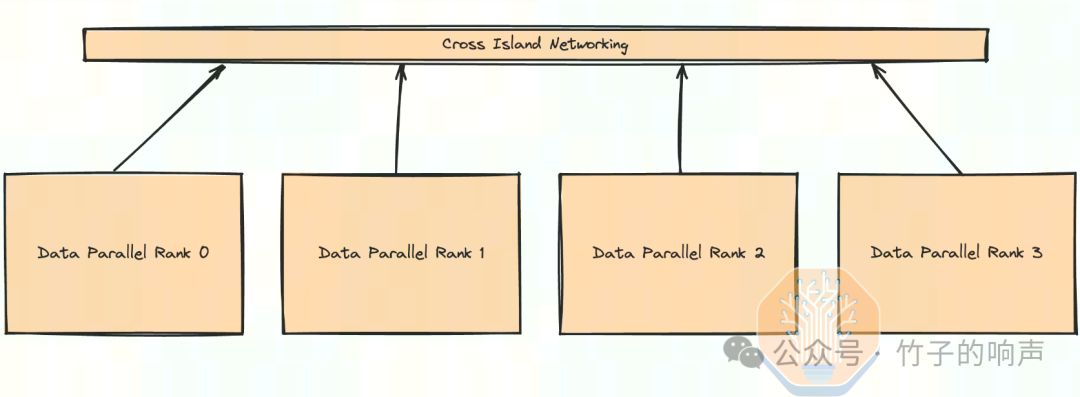
目前,这个拥有10万+节点的集群中,已有3栋建筑(3个计算岛)完工,每座计算岛容纳约1000-1100个机柜,总功耗约为50MW。
(2) 网络架构及并行策略数据并行(Data Parallelism)
这种并行方式的通信要求最低,因为GPU之间只需要传递梯度数据。
然而,数据并行要求每块GPU具备充足的内存以存储整个模型的权重。对于拥有1.8万亿参数的GPT-4模型而言,这意味着高达10.8TB的内存需求。
张量并行(Tensor Parallelism)
为了克服数据并行带来的内存限制,人们发明了张量并行技术。
在张量并行中,GPU之间需要频繁通信,以交换中间计算结果,从而实现更高效的计算。因此,张量并行需要高带宽和低延迟的网络连接。
通过张量并行,可以有效减少每块GPU的内存要求。例如,使用8个张量并行等级进行NVLink连接时,每块GPU使用的内存可以减少8倍。
流水线并行(Pipeline Parallelism)
另一个克服GPU内存限制的方法是流水线并行技术。
流水线并行是一种在分布式计算环境中实现模型并行的技术,主要用于深度学习领域,特别是在处理大规模神经网络模型时。通过将模型的不同部分(如神经网络的层)分配到不同的计算节点上,流水线并行能够在不牺牲训练效率的情况下,利用集群中的多台机器共同完成模型训练 。
当一块GPU完成层的前向、反向传播运算后,它可以将中间结果传递给下一块GPU,以便立即开始计算下一个数据批次。这样可以提高计算效率,缩短训练时间。
尽管引入了GPU之间的通信量,但每个GPU在完成计算后需将数据传递给下一个GPU,因此需要高效的网络连接以确保数据快速传输。
流水线并行对通信量的要求很高,但没有张量并行那么高。
3D并行(3D Parallelism)
采用H100 Server内的GPU张量并行,计算岛内节点流水线并行,跨计算岛实现数据并行,提高效率。
网络架构
进行网络拓扑设计时需要同时考虑到所用的并行化方案。
GPU部署有多种网络,包括前端网络、后端网络和扩展网络(NVLink),每个网络中运行不同的并行方案。
NVLink网络是处理张量并行带宽需求的唯一快速选择。尽管后端网络能轻松应对大多数其他类型的并行,但在存在收敛比问题时,数据并行成为首选。
当前建设10万张H100的超级AI算力集群,可以选择的网络方案主要有三种,分别是Broadcom Tomahawk 5,Nvidia Infiniband,以及Nvidia Spectrum-X。在大型AI集群中,Spectrum-X相比InfiniBand具有显著优势,包括性能、功耗和成本 。其中,Spectrum-X是NVIDIA推出的高性能以太网交换芯片平台,仅用于Spectrum-X平台,不单独销售。
这三种方案各有优劣,具体选择需要根据实际需求进行评估。如果您需要更多信息,请参考相关文献或咨询专业人士。
InfiniBand
InfiniBand的优势在于,以太网并不支持SHARP网络内缩减。
InfiniBand NDR Quantum-2交换机拥有64个400G端口,相较之下,Spectrum-X以太网的SN5600交换机和Broadcom的Tomahawk 5交换机ASIC均提供128个400G端口,提供了更高的端口密度和性能。
"Quantum-2交换机端口有限,10万节点集群中最多只能实现65,536个H100 GPU的完全互联。"
下一代InfiniBand交换机Quantum-X800将通过144个800G端口解决容量问题,但仅适用于NVL72和NVL36系统,因此不太可能在B200或B100集群中广泛应用。
Spectrum-X
Spectrum-X,得益于NVIDIA库如NCCL的一级支持,为您带来无与伦比的优势。加入他们的新产品线,您将成为首批客户,体验前所未有的创新。
Spectrum-X需搭配Nvidia LinkX收发器购买,因为其他收发器可能无法正常工作或未通过验证。
英伟达在400G Spectrum-X中,采用Bluefield-3替代了ConnectX-7作为暂时的解决方案,而ConnectX-8预计将与800G Spectrum-X完美协同。
在庞大的数据中心中,Bluefield-3和ConnectX-7的成本分别为约300美元/ASP,但Bluefield-3需额外消耗50瓦电力。因此,每个节点需增加400瓦功率,从而降低了整体训练服务器的每皮焦尔智能度。
Spectrum-X在数据中心部署10万个GPU需5MW功率,相较之下,Broadcom Tomahawk 5无需此功率。
为了避免给英伟达支付高昂的费用,许多客户选择部署基于Broadcom Tomahawk 5的交换机。这款芯片能够以5.5W的功率为800Gbps的流量供电,减少了将信号驱动到交换机前端的可插拔光学器件的需要。此外,Broadcom周二推出了该公司最新的交换芯片Tomahawk 5,能够在端点之间互连总计每秒51.2太比特的带宽。
基于Tomahawk 5的交换机与Spectrum-X SN5600交换机同样具备128个400G端口,若公司拥有卓越的网络工程师,可实现等同性能。此外,您可从任何供应商购买通用收发器及铜缆并进行混合使用。
众多客户选择与ODM厂商合作,如Celestica的交换机、Innolight和Eoptolink的收发器等。
"根据交换机和通用收发器的成本考虑,Tomahawk 5在价格上大大优于Nvidia InfiniBand。而且,与Nvidia Spectrum-X相比,它更具成本效益。"
遗憾的是,要为Tomahawk 5修补和优化NCCL通信集群,您需要具备扎实的工程技能。诚然,NCCL开箱即用,但其仅针对Nvidia Spectrum-X和Nvidia InfiniBand进行了优化。
如果你有40亿美元用于10万个集群,那么你应该也有足够的工程能力来修补NCCL并进行优化。
软件开发充满挑战,然而Semianalysis预测,超大规模数据中心将转向其他优化方案,摒弃InfiniBand。
轨道优化为了提高网络维护性和延长铜缆(<3米)及多模(<50米)网络的使用寿命,部分客户选择摒弃英伟达推荐的轨道优化设计(rail optimized design),转向采用中间架设计(Middle of Rack design)。
"轨道优化技术,让每台H100服务器与八个独立的叶交换机建立连接,而非汇聚在同一机架。这种设计让每个GPU仅需一次跳转就能与更远的GPU进行通信,从而大幅提升全对全集体通信性能。"
比如在混合专家(MoE)并行中,就大量使用了全对全集体通信。
在同一机架内,交换机可采用无源直连电缆(DAC)和有源电缆(AEC)。但在轨道优化设计中,若交换机位置不同,需借助光学器件实现连接。
此外,叶交换机到骨架交换机的距离可能大于50米,因此必须使用单模光收发器。
通过非轨道优化设计,您可以用廉价的直连铜缆替换连接GPU和叶交换机的98304个光纤收发器,从而使您的GPU链路中铜缆占比提高至25-33%。
DAC铜缆在运行温度、耗电和成本方面相较于光缆具有显著优势,同时可靠性更高。这种设计有效降低了网络链路间歇性瘫痪和故障,是高速互连领域光学器件所面临的主要挑战的关键解决方案。
Quantum-2IB骨架交换机在采用DAC铜缆时,功耗为747瓦;若使用多模光纤收发器,功耗将升至1500瓦。
初始布线对数据中心技术人员来说耗时巨大,每条链路两端距离50米且不在同一机架,轨道优化设计助力提升效率。
在中间机架设计中,叶交换机与所有连接的GPU共享同一机架。甚至在设计完成前,就可以在集成工厂测试计算节点到叶交换机的链路,因为所有链路都在同一机架内。
组网举例如图所示,这是常见的三层Fat-Tree拓扑(SuperSpine-Spine-Leaf),其中两个Spine-Leaf组成一个Pod。
Spine Switch 和 SuperSpine Switch 需要连接,因此相应 Group 的数目要减半。一个 Pod 有 64 个 Spine Switch,对应 8 个 Group。因此,一个 Pod 有 64 个 Leaf Switch。有了多个 Pod,可以进一步构建 64 个 SuperSpine Fabric,每一个 Fabric 要与不同 Pod 中的 Spine Switch 实现全互联。这里以 8 个 Pod 为例,将 8 个 Pod 里的第 i 个 Spine Switch 与 Fabric i 中的 SuperSpine Switch 实现 Full Mesh,这里有 8 个 Pod,因此一个 Fabric 中只需要 4 个 128 Port 的 SuperSpine Switch 即可。以上配置 8 个 Pod 对应:总的 GPU:4096*8=32768SuperSpine Switch:64*4=256Spine Switch:64*8=512Leaf Switch:64*8=512总的 Switch:256+512+512=1280总的光模块数:1280*128+32768=196608实际上理论最多可以支持 128 个 Pod,对应的设备数为:GPU:4096*128=524288=2*(128/2)^3SuperSpine Switch:64*64=4096=(128/2)^2Spine Switch:64*128=8192=2*(128/2)^2Leaf Switch:64*128=8192=2*(128/2)^2优化后的文章:Switch性能分析:$4096+8192+8192$ =20480,相当于$5\times(128/2)^2$.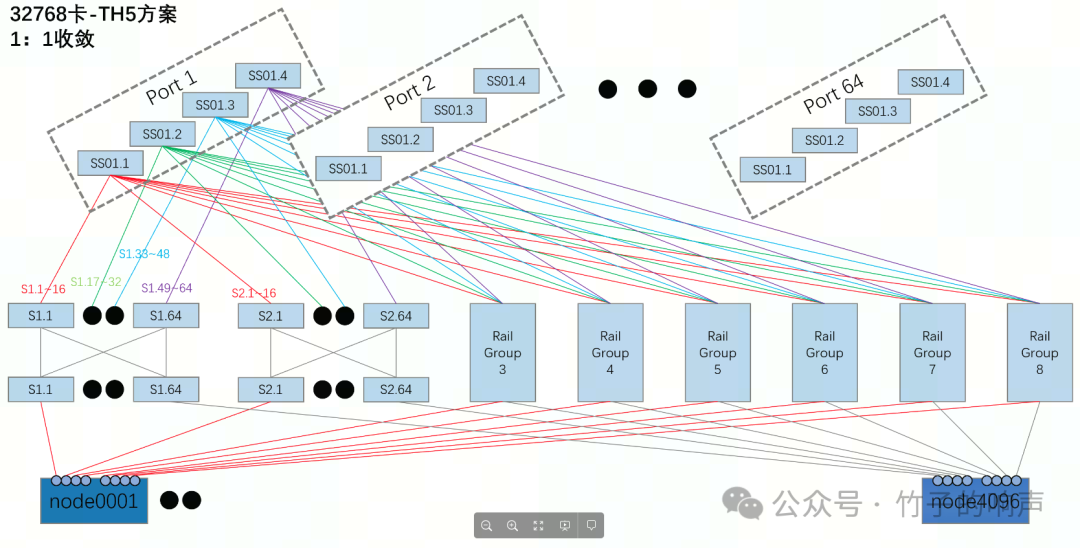
万卡集群依次扩展3个类似的pod即可。
(3)可靠性与恢复同步模型训练导致巨型集群的可靠性成问题。常见问题包括GPU HBM ECC错误、GPU驱动卡死、光纤收发器故障和网卡过热等。
为了缩短故障恢复时间,数据中心需配置热备与冷备设备。在发生问题时,最佳策略是利用备用节点继续训练,而非直接中断。
数据中心技术人员可在数小时内修复受损GPU服务器,但在某些情况下,节点可能需数日方可重新投入使用。
在训练模型过程中,为了避免HBM ECC等错误,我们需要定期将检查点存储到CPU内存或SSD持久化存储。一旦出现错误,重新加载模型和优化器权重并继续训练是必不可少的。
容错训练技术可用于提供用户级应用驱动方法,以处理GPU和网络故障。
遗憾的是,频繁备份检查点和容错训练技术可能导致系统整体MFU受损。集群需不断暂停以保存权重至持久存储或CPU内存。
每100次迭代仅保存一次检查点,可能导致重大损失。以一个拥有10万卡的集群为例,若每次迭代耗时2秒,那么在第99次迭代失败时,可能损失高达229个GPU日的工作。
另一种故障恢复策略是利用备用节点通过后端结构从其他GPU进行RDMA复制。这种方法具有高效性,后端GPU的速度高达400Gbps,每个GPU还配备了80GB的HBM内存,因此复制过程仅需约1.6秒。
通过此策略,最多损失1个步骤(因为更多GPU HBM将获得权重更新),从而在2.3个GPU日的计算时间内完成,再加上从其他GPU HBM内存RDMA复制权重所需的1.85个GPU日。
众多顶尖AI实验室已采纳此技术,然许多小型公司仍坚守繁琐、缓慢且低效的方式——重启处理以复原故障。借助内存重构实现故障恢复,可大幅提升大型训练运行的MFU效率,节省数个百分点的时间。
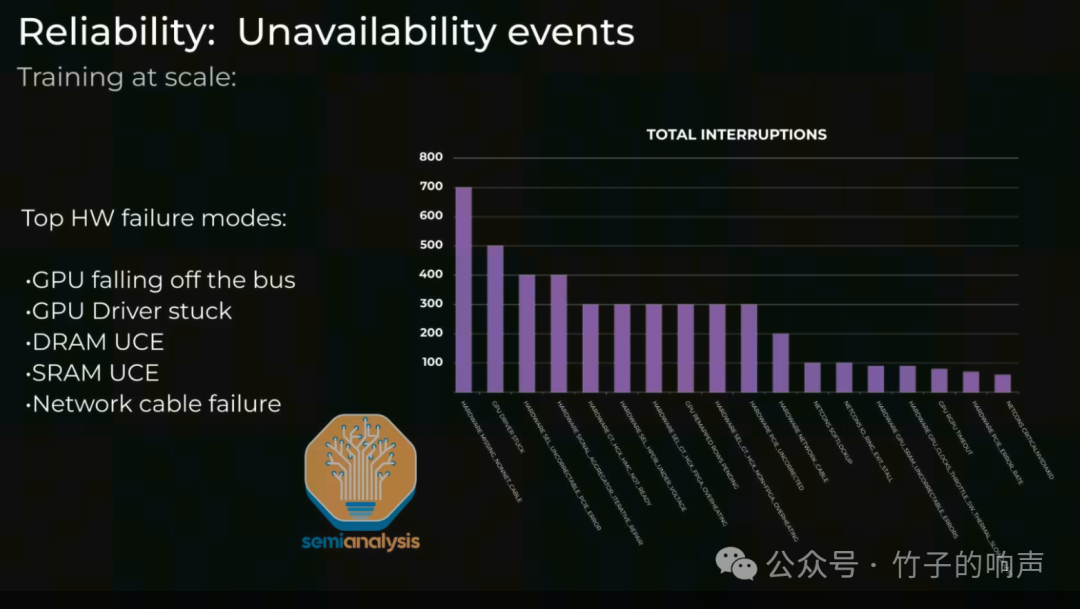
在网络故障领域,Infiniband/RoCE链路故障是最常见的问题。尽管收发器数量较多,但在全新且正常运行的集群中,第一次作业故障仅需26.28分钟,即使每个网卡到最底层交换机链路的平均故障率为5年。
在10万卡GPU集群中,光纤故障导致重新启动运行所需时间远超模型计算,未经内存重建的故障恢复策略将影响效率。
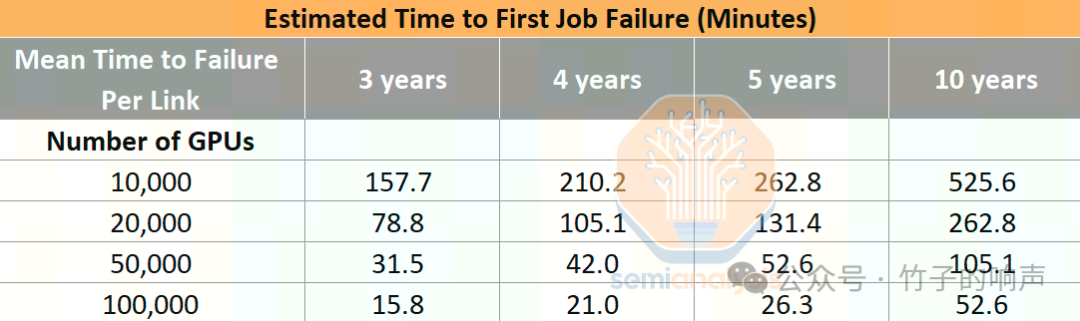
由于GPU与ConnectX-7网卡直接相连,网络架构无容错设计,导致故障需在用户训练代码中解决,从而增加代码库复杂性。
大语言模型(LLM)在节点内使用张量并行,如果一个网卡、一个收发器或一个GPU故障,整个服务器就会宕机。 由于该策略涉及的网络通信量较大,需要利用服务器内部的不同计算设备之间进行高速通信带宽。
目前,有很多工作正在进行,以使网络可重配置,减少节点的脆弱性。这项工作至关重要,因为现状意味着整个GB200 NVL72仅因一个GPU或光学故障就会宕机。
RAS引擎通过深入分析诸如温度、ECC重试次数、时钟速度和电压等关键芯片级数据,准确预测潜在故障并及时通知数据中心工程师,确保系统稳定运行。
"此举使技术团队能主动维护,如提升风扇速度以保稳定,并在维护窗口期将服务器撤离运行队列进行深入检查。"
在训练任务开始前,每颗芯片的RAS引擎将进行全面自检,例如执行已知结果的矩阵乘法以侦测静默数据损坏(SDC)。
(4)物料清单具体来说,可以分为四种(原文中是7:1,实际上应该是8:1?):
"强大的4层InfiniBand网络,拥有32,768个GPU集群,轨道优化技术,实现7:1收敛速度提升。"
Spectrum X网络是一种以太网平台,由NVIDIA开发。它是一种专为提高Ethernet-based AI云的性能和效率而设计的以太网平台。该网络平台提供了3层架构,其中包括32,768个GPU集群,轨道优化设计,7:1收敛比。
3. 3层InfiniBand网络,包含24,576个GPU集群,非轨道优化设计,用于前端网络的集群间连接。
"搭载3层Broadcom Tomahawk 5以太网网络,拥有32,768个GPU集群,实现轨道优化,7:1收敛比。"
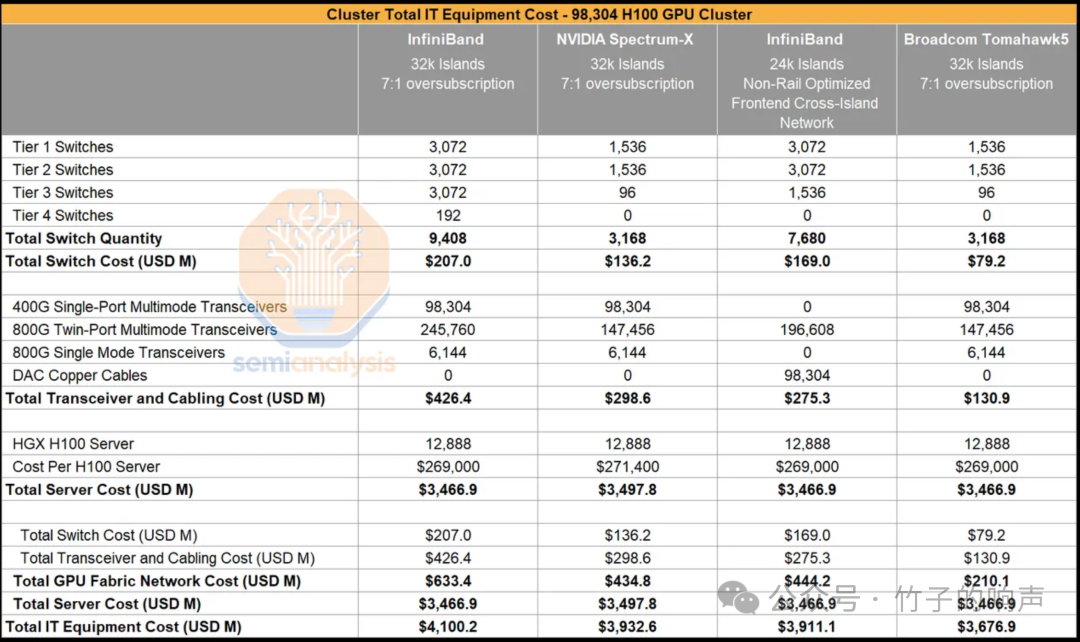
经比较,选项1价格较其他选项高1.3至1.6倍;选项2提供更大集群、更高带宽和相近成本,但耗电更多;选项3可能导致并行方案灵活性大幅降低。
基于Broadcom Tomahawk 5的32k集群,搭配7:1的收敛比,是最具成本效益的选项。这也是多家公司选择构建类似网络的原因。
(5)平面布局
最后,在集群的设计上,还需要优化机架布局。
因为如果将多模收发器放在行的末端,中间的主干交换机将超出距离范围。
Spectrum-X/Tomahawk 5的32k集群平面图,采用轨道优化设计,预计至少需80*60m平面空间。

目前,这个庞大的集群拥有10万+节点,其中3栋建筑已经完工(共3个计算岛)。每个计算岛容纳约1000~1100个机柜,总功耗约为50MW。

-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
