Non-GAAP口径下,英伟达FY25Q2收入300.40亿美元,同比增长122%,环比增长15%;毛利率75.7%,同比增长4.5Pts,环比下降3.2pts;净利润169.52亿美元,同比增长152%,环比增长11%。

英伟达FY25Q2数据中心业务收入262.72亿美元,同比增长154%,环比增长16%。数据中心业务增长的关键来自于生成式AI 模型的训练和推理;视频、图像和文本数据的预处理和后处理;合成数据生成、基于 AI 的推荐系统、SQL 和向量数据库处理。

英伟达H200平台在2024Q2开始向大型CSP、消费级互联网客户和企业客户发货。Hopper 出货量预计在2024H2持续增长。Hopper供应/可用性已经大幅改善。
Blackwell系列芯片正在被广泛试用,生产爬坡计划在2024Q4开始,并持续到2025年;预计Blackwell将在2024Q4实现数十亿美元的收入。Blackwell的需求远超过供应,英伟达预计这种供不应求的情况将持续到2025年。
FY25Q2网络业务同比增长是由 InfiniBand 和用于 AI 的以太网推动的,其中包括 Spectrum-X 端到端以太网平台。
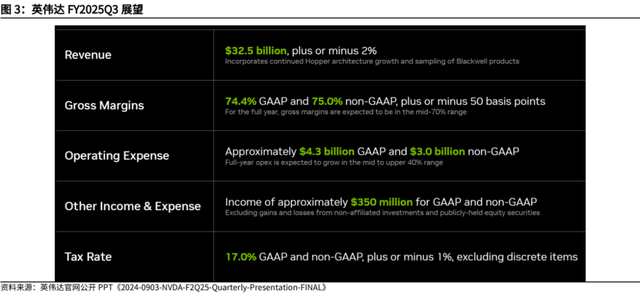
Non-GAAP口径下,英伟达预计FY2025Q3将实现收入325亿美元,毛利率75%。
 1.2、英伟达Blackwell和GB200 NVL36/72重磅发布
1.2、英伟达Blackwell和GB200 NVL36/72重磅发布2024年3月19日英伟达GTC大会上,黄仁勋在发布Blackwell产品。Blackwell架构拥有2080亿个晶体管。两块晶片之间通过一条细线贴合,组成B200 GPU(Largest Die Possible×2 = B200),也叫做Blackwell GPU。这是两块晶片首次以这样的方式进行贴合并组成一块晶片。晶片之间进行带宽互联,数据传输速率达每秒10TB。2080亿个晶体管几乎同时访问与芯片连接的内存,因此Blackwell芯片不存在内存局限和缓存的问题。
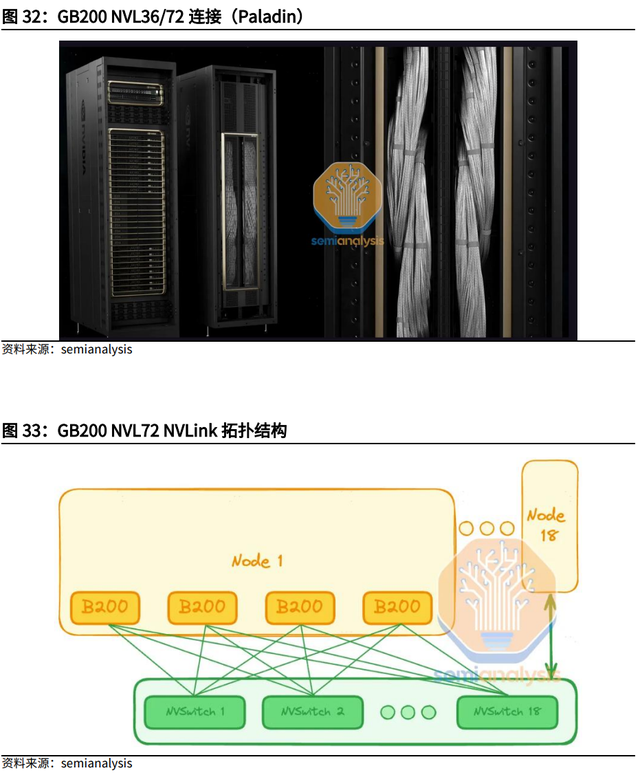
将两个B200 GPU与一个基于ARM的Grace CPU进行配对,再通过900GB/s的超低功耗NVLink连接在一起,可以组成GB200超级芯片。Blackwell的顶部有NVLink,底部有PCI Express。将两个GB200超级芯片合并安装到一块主板上,可以组成一个Blackwell计算节点。Blackwell Compute Node也叫Compute Tray。把18个Blackwell计算节点(Compute Tray)组合在一起,可以形成新一代计算单元:GB200 NVL72(Blackwell Node × 18 + NVLink Switch X 9 = GB200 NVL72)。GB200 NVL72中一共包含了9个NVLink交换节点(Switch Tray),每个交换节点中配置了2颗NVLink Switch芯片,向外提供14.4TB/s的聚合带宽。
如果要训练一个1.8万亿参数量的GPT模型,需要8000张Hopper GPU,消耗15兆瓦的电力,连续跑上90天。但如果使用Blackwell GPU,只需要2000张,同样跑90天只要消耗四分之一的电力。除了训练之外,生成Token的成本也会随之降低。GB200 NVL72训练和推理性能相比于等同数量的H100 GPU表现提升4倍和30倍。
Blackwell架构的GPU产品投产,将成为英伟达2024、2025年的重要营收驱动。得益于客户对AI/加速计算计划的持续支出,以及对其Hopper H100和新H200 GPU平台(Blackwell GB200/B200/B100)的强劲需求,Blackwell架构将成为英伟达2024、2025年的重要营收驱动。
Blackwell Ultra将于2025年发布,下一代平台名为Rubin。英伟达以每年一次的更新节奏,构建覆盖整个数据中心规模的解决方案,将这些解决方案分解为各个部件,以每年一次的频率向全球客户推出。英伟达采用最先进的工艺技术、封测技术、内存技术和光学技术,推动产品性能的不断提升。英伟达的计算机平台能够向后兼容,且架构上与已有软件完美契合时,产品的上市速度将显著提升。因此Blackwell平台能够充分利用已构建的软件生态基础,实现较高的市场响应速度。Blackwell Ultra将会确保所有产品都保持100%的架构兼容性。


 1.3、英伟达GB200 机架拥有4种不同形式
1.3、英伟达GB200 机架拥有4种不同形式GB200机架提供4种不同的主要外形尺寸(分别是GB200 NVL72、GB200 NVL36x2、GB200 NVL36x2(Ariel)、x86 B200 NVL72/NVL36x2),每种尺寸均可定制
1、GB200 NVL72 需要大约 120kW/机架。通用CPU机架支持高达12kW/机架,而更高密度的H100风冷机架通常仅支持大约40kW/机架。每机架超过40kW是 GB200需要液体冷却的主要原因。GB200 NVL72机架由18个1U计算托盘和 9 个NVSwitch托盘组成。每个计算托盘高1U,包含2个Bianca板。每个Bianca 板包含1个Grace CPU和2个Blackwell GPU。NVSwitch 托盘有两个 28.8Gb/s NVSwitch5 ASIC。
2、GB200 NVL36 * 2 是两个并排互连在一起的机架。大多数GB200机架将使用此外形尺寸。每个机架包含18个Grace CPU和36 个Blackwell GPU。每个计算托盘的高度为2U,包含2个Bianca板。每个NVSwitch托盘都有两个28.8Gb/s NVSwitch5 ASIC 芯片。每个芯片有14.4Gb/s指向背板,14.4Gb/s指向前板。每个NVswitch 托盘有18个1.6T双端口OSFP cages,水平连接到一对NVL36 机架。
3、带有定制“Ariel”板(而不是标准 Bianca)的特定机架,主要由 Meta 使用。由于 Meta 的推荐系统训练和推理工作负载,它们需要更高的 CPU 核心和每 GPU 更多的内存比率,以便存储大量嵌入表并在 CPU 上执行预处理/后处理。
该机架与标准GB200 NVL72类似,但 Bianca板被替换为具有1个Grace CPU 和1个Blackwell GPU的Ariel板。由于每个GPU的Grace CPU内容翻倍,因此与NVL36x2相比,此SKU的价格会更高。与NVL36x2类似,每个NVSwitch 托盘有18个1.6T双端口OSFP cages,水平连接到一对NVL36机架。
4、B200 NVL72和NVL36x2将使用x86 CPU而不是Nvidia内部的grace CPU。这种规格称为Miranda。每个计算托盘的CPU到GPU的比例将保持不变,即每个计算托盘2个CPU 和4个GPU。

 2、英伟达Blackwell芯片短期延迟小幅影响2024年出货节奏,不改2025年产业趋势2.1 英伟达B系列芯片小幅延期,未来将推出B102和B200A
2、英伟达Blackwell芯片短期延迟小幅影响2024年出货节奏,不改2025年产业趋势2.1 英伟达B系列芯片小幅延期,未来将推出B102和B200A根据Semi Analysis,英伟达Blackwell系列芯片量产遇到问题,导致原定2024Q3/Q4和2025H1的生产目标延后。预计英伟达Hopper系列芯片将弥补Blackwell系列芯片的出货缺口。

GB200是英伟达最先进的Blackwell芯片,基于GB200芯片的NVL72机柜的功率密度约125kW/rack,但大部分数据中心部署的单机柜功率密度为12-20kW/rack。由于功率密度和计算能力的复杂程度,量产爬坡的挑战性巨大,配电、过热、液冷等问题均需要解决。
英伟达Blackwell是第一个使用台积电CoWoS-L封装工艺的芯片。

CoWoS-L使用RDL interposer(RDL中介层)去桥接各种计算芯片和存储芯片。CoWoS-L是CoWoS-S的下一代产品。随着AI芯片需要满足更多逻辑单元、存储单元和IO接口的需求,CoWoS-S的尺寸和性能面临更多的挑战。台积电已经将CoWoS-S的Interposer扩展到了AMD MI300芯片约3.5倍大小。随着Interposer尺寸变得更大,不仅价格更贵,而且生产这种Interposer将变得更难,因为silicon Interposer很脆且易碎。CoWoS-L是一项更复杂的技术,代表着CoWoS封装技术的未来。英伟达和台积电有非常激进的CoWoS-L爬坡计划,计划未来单季度量产100万颗以上CoWoS-L芯片。
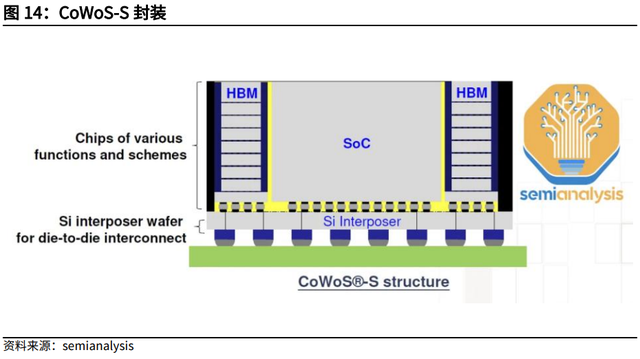
目前台积电没有足够的CoWoS-L产能。台积电过去几年建立了大量的CoWoS-S产能,其中英伟达占据最大份额。目前随着英伟达迅速将需求转向CoWoS-L,台积电一方面为CoWoS-L建造了一个新的工厂AP6,一方面在AP3工厂将CoWoS-S转向CoWoS-L。转产CoWoS-S将导致CoWoS-S产能利用率不足,且CoWoS-L爬坡进度较慢。

由于系统设计复杂和CoWoS-L良率较低这两个问题,台积电无法向英伟达提供足够的Blackwell芯片。因此,英伟达几乎完全将其产能集中在GB200NVL36x2和NVL72。B100和B200的HGX形态基本被取消了。
英伟达推出B102(单die)/B200A。为了满足需求,英伟达将推出一款基于B102的Blackwell GPU,称为B200A。这款B102芯片也将用于中国版Blackwell,称为B20。B102是一个带有4层HBM的单die计算芯片。这款芯片可以封装在CoWoS-S上,而不是封装CoWoS-L上。英伟达其他2.5D封装供应商,如Amkor、ASE SPIL和Samsung都可以提供相关的产品。B200A将取消C2C I/O,设计上更为简单。

B200A将用于满足对中低端AI系统的需求,并将取代HGX 8-GPU外形尺寸的B100和B200芯片。B200A将采用700W和1000W的HGX外形尺寸,HBM3E达到144GB,内存带宽高达4TB/S。B200A也将有一个ultra版本。B200A ultra不会有内存升级,尽管芯片可能会重新设计以提升FLOPS。B200A Ultra还引入了全新的MGX NVL36外形。B200A Ultra也将像最初的B200A一样采用HGX配置。
Blackwell Ultra,Blackwell的中代增强产品,CoWoS-L封装的Blackwell Ultra将被称为B210或B200 Ultra。Blackwell Ultra包含高达288GB的12层HBM3E内存和性能增强50%的FLOPS算力。
对于超大规模市场的客户来说,GB200 NVL72/36x2将继续是最具吸引力的,因为它在推理过程中对超过2万亿参数的模型具有最高的性能/TCO。如果超大规模客户无法获得GB200 NVL72/36x2,他们可能仍然需要购买MGX GB200A NVL36。此外,在功率密度较低或非液冷数据中心,MGX NVL36看起来更有吸引力。HGX Blackwell服务器仍将被超大规模云计算客户购买,因为它是用于出租给外部客户的最小计算单位,但购买量将比以前低得多。对于小型模型,HGX的性能/TCO最优,因为这些模型不需要大量的内存,NVL8的内存可以满足这些小型模型的需求。
neocloud(新兴云市场)的大多数客户不会购买GB200 NVL72/36x2,因为难以寻找拥有液冷或高能耗指标的托管服务提供商。此外,对于有限的GB200NVL72/36x2来说,大多数neocloud客户通常比超大规模客户(hyperscalers)优先级更靠后。对于最大的neocloud客户来说,如Coreweave,有自建/改造数据中心的需求,将选择GB200 NVL72/36x2。对于neocloud市场的其余客户来说,大多数人将选择HGX Blackwell服务器和MGX NVL36,因为这些服务器只能使用风冷和较低能耗的机架进行部署。目前,大多数neocloud客户的部署都是使用功率密度为20kW/机柜的Hopper服务器;未来,这些neocloud客户有可能部署MGX GB200 NVL36,因为这只需要40kW/风冷机柜。
MGX GB200A NVL36 SKU是一款全风冷的40kW/机架服务器,36个GPU与NVLink完全互连。每个机架将有9个计算托盘和9个NVSwitch托盘。每个计算托盘是2U,包含一个Grace CPU和四个700W B200A Blackwell GPU,而GB200NVL72/36x2有两个Grace CPU和四个1200W BlackwellGPU。MGX NVL36设计的CPU与GPU的比例仅为1:4,而GB200NVL72/36x2的比例为2:4。此外,每个1U NVSwitch托盘只有一个交换芯片,每个交换芯片的带宽为28.8Tbit/s。
2.2 鸿海:GB200延迟出货对2025年基本无影响GB200由于设计缺陷导致短期延迟出货,在英伟达和供应链相关公司的业绩方面,2024年或有部分影响,2025年基本无影响。2024年8月14日鸿海法说会表示,由于GB200新产品规格和技术提升较大,设计难度较高,动态调整很常见,目前开发的AI服务器都按照进度进行,2024Q4开始小批量出货GB200服务器,2025Q1有望放量,后续产品周期有望持续加速。鸿海认为GB200由于设计缺陷导致延迟出货造成的影响已经基本消除。
3、光模块:AI供应链最核心受益赛道3.1 光模块产业趋势:AI驱动800G/1.6T/3.2T数通光模块快速成长AI驱动全球光模块行业快速成长。光模块是AI投资中网络端的重要环节,其与训练端GPU出货量强相关,同时推理段流量需求爆发也有望带动需求增长。在算力投资持续背景下,AI成为光模块数通市场的核心增长力。根据Lightcounting和Coherent预测,全球数通光模块市场23年-28年的CAGR为18%,其中,AI用数通光模块市场CAGR为47%。增长驱动力主要来自800G、1.6T、3.2T光模块需求,据Coherent数据,到2027年,整个数通市场800G及以上速率的光模块市场规模占比将超过50%。
更高的互联速率+更多的互联数增长奠定了光模块广阔的市场空间。AI已明确加快了光模块技术迭代,并且显著缩短了光模块周期,之前从100G过渡到400G用了超过3年,为了实现更高的传输速率以匹配日渐提高的计算速度需求,从800G到1.6T的代际替换有望缩短至不到两年。根据FiberMall数据预测,2021-2025年交换机密度预计大约每2年翻1倍,相对应光模块速率也将同步匹配。Marvell于在其投资者交流会提到,模型规模变大带来的多卡并行,越来越多的交换网络层数使得连接数的上升幅度比GPU的增幅更快。Scaling law下,大模型规模越来越大带来交换网络层数提升,光模块配比提升。GPT-3在1K个集群上训练,对应需要2500个光互连;GPT-4在25K个集群上训练,对应需要75000个光互连。未来的10万个超大计算集群,需要50万个光互联(5层架构,GPU与光模块的配比为1:5),随着Scailing law的演进,为了实现AGI,未来甚至可能会出现1:10光模块配比的网络架构。
总的来说,更多的GPU驱动更多的端口连接;同时,随着GPU算力愈来愈强,需要更多的带宽来保持它们处理数据,因此,更高算力的GPU需要更高速的端口。这两个因素导致了超大规模数据中心连接需求的指数级增长,这是一个庞大且迅速增长的市场。
根据Coherent对于行业未来的产品路线图预测,50Tb/s交换机时代,单通道100G的800G光模块于2023年开始大规模量产(已量产);单通道200G的800G光模块于2024年批量出货;LPO方案于2024H2批量出货。100Tb/s交换机时代,单通道200G的1.6T光模块将于2024年年底量产,LPO方案也于2024年年底开始量产;单通道200G的3.2T光模块将于2026年年初量产,可应用于100Tb/s交换机,也可用于下一代200 Tb/s交换机。

AI用光模块中,预计硅光光模块市场规模增速最快。
1、VCSEL激光器用在多模光模块中,适用于短距离传输且成本收益比较高,由于AI训练集群中GPU间互联需求大幅提升,预计其会快速增长。Coherent预计AI用VCSEL光模块市场规模将从2023年的3亿美金增长至2028年的16亿美金,占比从6%提升至14%。
2、EML激光器应用在单模光模块中,适用于长距离互联,多用于上层交换机互联以实现大规模AI集群, Coherent预计AI用EML光模块市场规模将从2023年的6亿美金增长至2028年的20亿美金,占比从12%提升至18%。
硅光由于在硅基衬底上集成光子和电子器件,实现了光模块的高集成度、小型化和低功耗,预计1.6T及以上速率硅光光模块占比会越来越高,Coherent预测AI用硅光光模块市场规模将从2023年的2亿美金增长至2028年的34亿美金,占比从3%提升至29%。
受到AI拉动,中国光模块出口额2024年以来高速增长。根据海关总署数据,2024年8月全国光模块出口金额为37.46亿元,同比+72.3%;1-8月累计出口290.89亿元,同比+78%。国内光模块前两大龙头(海外市场)中际旭创和新易盛总部分别位于江苏省和四川省,所以观察这两个省份光模块的出口数据可以一定程度表征AI用光模块的景气度:2024年8月江苏省光模块出口金额为18.75亿元,同比+80.9%;1-8月累计出口166.08亿元,同比+115.2%。2024年8月四川省光模块出口金额为7.66亿元,同比+237.4%;1-8月累计出口45.23亿元,同比+160.7%。
 3.2、英伟达推出B系列GPU,提振高速率光模块需求
3.2、英伟达推出B系列GPU,提振高速率光模块需求英伟达于2024年3月发布了新一代人工智能芯片Blackwell GPU,新的 B200 GPU拥有2080亿个晶体管,可提供高达20petaflops的FP4算力,而GB200将两个GPU和一个Grace CPU结合在一起,可为 LLM 推理工作负载提供30倍的性能,同时还可能大大提高效率,与 H100 相比,它的成本和能耗最多可降低 25 倍。英伟达声称,训练一个1.8万亿个参数的模型以前需要8000个Hopper GPU和15兆瓦的电力。如今,2000个Blackwell GPU就能完成这项工作,耗电量仅为4兆瓦。在具有1750亿个参数的GPT-3 LLM基准测试中,GB200的性能是H100的7倍,而英伟达称其训练速度是H100的4倍。
Blackwell系列GPU,提振高速率光模块需求。不同英伟达GPU产品以及不同互联方式下,光模块和GPU的比例关系如下表格。即使新一代B200和GB200产品在ConnectX-7网卡规格下,跟上一代光模块用量相同,但未来搭配ConnectX-8的GB200产品将大幅提升对于1.6T光模块的需求,且在B系列GPU的生命周期中,搭配ConnectX-8的NVL72将会是主力产品。此外,随着大模型的不断迭代,未来向通用型人工智能迈进,NVL576这种大规模高速互联的组网方式需求也将不断攀升,从而拉动1.6T光模块需求( GPU与1.6T光模块的比例为1:9)。
 4、铜连接:GB200 NVL引领创新,AI服务器将驱动铜缆持续高景气4.1、铜缆是短距离互联的最佳路径
4、铜连接:GB200 NVL引领创新,AI服务器将驱动铜缆持续高景气4.1、铜缆是短距离互联的最佳路径直连铜缆(Direct Attach Cable,DAC),或称Twinax铜缆、高速线缆,是一种固定长度、两端有固定连接器的线缆组件。

DAC铜缆包含有源(active)和无源(passive)两种,有源DAC铜缆内置了放大器和均衡器,可以提升信号质量,但相对成本较高。大多数情况下,当传输距离小于5米时,可以选择使用无源DAC铜缆,而当传输距离大于5米时,可以选择有源DAC铜缆。
DAC铜缆上的连接器与光模块相比,接口类型相同,但缺少了昂贵的光学激光器和其他电子元件,因此可以大大节省成本和功耗,广泛应用于数据中心网络中的短距离连接。
在TOR场景下,DAC铜缆是进行机柜内短距离布线的最佳选择。在EOR场景下,如果传输距离小于10米,也可以选择使用DAC铜缆。

DAC电缆可分为两种类型:无源铜电缆(PCC)和有源DAC。有源DAC可以进一步分为有源铜线(ACC)和有源电缆(AEC)。无源和有源DAC电缆都可以通过铜线直接传输电信号。前者可以在没有信号调节的情况下进行传输,后者在收发器内部配备了电子设备以增强信号。
ACC有源铜线作为一种有源铜线,利用Redriver芯片架构,并采用CTLE均衡来调整Rx端的增益。本质上,ACC的作用是作为一根有源电缆放大模拟信号。
AEC有源电缆代表了有源铜线电缆的一种更具创新性的方法,AEC利用Retimer芯片架构放大和均衡Tx和Rx端子,而且重塑Rx端子处的信号。
 4.2、英伟达GB200 NVL使用铜缆连接Switch Tray和Compute Tray
4.2、英伟达GB200 NVL使用铜缆连接Switch Tray和Compute TrayGB200的前端、后端和带外网络基本相同,但NVLink 扩展到机箱外部则会产生差异,每一代超大规模定制都会有所不同。
HGX H100中8个GPU和4个NVSwitch4 ASIC使用PCB走线连接在一起,它们位于同一PCB(即HGX基板)。在HGX Blackwell上,NVSwitch ASIC 位于中间,以减少PCB走线的长度, 同时224G SerDes进行了升级。

但是在GB200上,NVSwitches与GPU位于不同的托盘上,因此需要使用光学或ACC 在它们之间进行连接。
NVL72中保留了与HGX Hopper/Blackwell 相同的扁平1层NVLink拓扑,因此只需通过NVSwitch进行1跳(hop)即可与同一机架内的任何GPU通信。
而在NVL36x2 中,只需1跳即可到达同一机架中36个GPU的任何一个,但为了与旁边机架中的其他36个GPU通信,需要2个NVSwitch才能跨机架。直观地看,一个额外的NVSwitch连接会增加延迟,但对于训练模型来说这个延迟并不明显。一个额外的NVSwitch连接会对推理运算产生轻微影响。
 4.3、铜连接用量有望大幅提升
4.3、铜连接用量有望大幅提升Nvidia表示,如果使用光模块,则需要为每个NVL72机架增加 20kW的功耗。Semianalysis表示,如果需要使用648个1.6T双端口光模块,每个光模块的功耗约为30W,则功耗为19.4kW/机架,与Nvidia的说法基本相同。每个1.6T光模块的价格约为850美元,仅光模块成本一项就高达每机架550,800美元。如果按Nvidia 75%的毛利率计算,则意味着最终客户需要为每机架NVLink收发器支付2,203,200美元。这是DGX H100 NVL256 因光模块成本过高而从未发货的主要原因之一。此外,与铜缆甚至上一代光纤相比,1.6T NVLink光模块等前沿光模块的可靠性要差得多。
因此,有源铜缆 (ACC)铜缆更便宜、省电且可靠。每个GPU都有900GB/s的单向带宽。每个差分对 (DP) 能够在一个方向上传输 200Gb/s,因此每个GPU需要72个DP才能实现双向传输。由于每个NVL72机架有72个GPU,这意味着有 5184个差分对。每条NVLink电缆包含1个差分对,因此有5184 条电缆。

每个Blackwell GPU都连接到Amphenol Paladin HD 224G/s连接器,每个连接器有72个差分对,连接器连接到背板Paladin连接器。使用 SkewClear EXD Gen 2电缆连接到NVSwitch托盘Paladin HD连接器,则每个连接器有144 个差分对。从NVSwitch Paladin连接器到NVSwitch ASIC芯片,需要OverPass跨接电缆,因为每个交换机托盘有4个144 DP 连接器(576 DP)。PCB走线会产生串扰,且PCB上的损耗比跨接电缆上的损耗更严重。
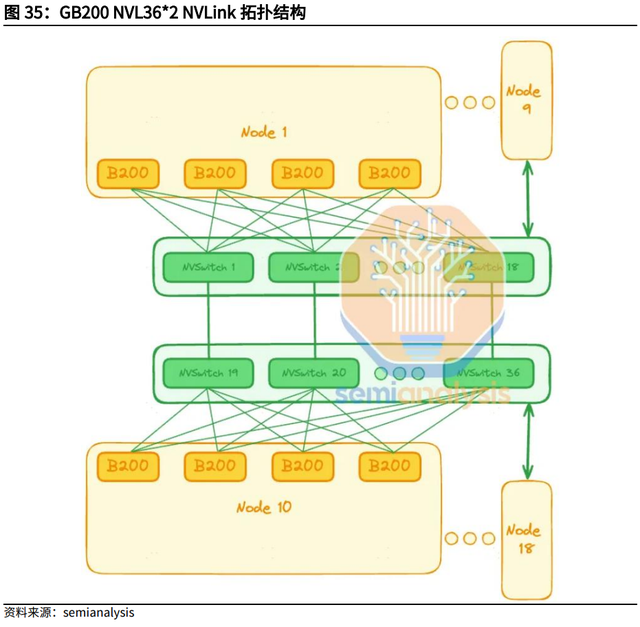

使用NVL36x2,则每个系统将需要额外的162 条1.6T双端口水平ACC电缆,这些电缆对于连接机架A和机架B之间的NVSwitch托盘来说非常昂贵。此外,OSFP还需要额外的324条DensiLink跨接电缆。仅这些DensiLink 跨接电缆就需要每台NVL36x2增加10,000多美元的成本。
此外,NVL36*2需要两倍的NVSwitch5 ASIC来实现机架A和机架B之间的连接,这将使NVLink铜缆总成本比NVL72增加一倍以上。尽管NVL36x2的NVLink 背板比NVL72贵两倍多,但因为功率和冷却限制,大多数购买者仍会选择 NVL36x2设计。由于NVL36x2的普及,电缆供应商销量有望大幅增加。

 4.4 铜连接产业链持续高景气:精达股份子公司恒丰特导镀银高速铜线业务快速发展
4.4 铜连接产业链持续高景气:精达股份子公司恒丰特导镀银高速铜线业务快速发展精达股份是一家从事铜基电磁线、铝基电磁线、特种导体研发、制造、销售和服务于一体的国家级高新技术企业,产品广泛应用于新能源汽车、光伏逆变器、人工智能、军工、航空航天、家电、特种电机、5G通讯及电子产品等领域,畅销全国并远销欧洲、南美、东南亚、中东、日本等全球市场。公司在长三角、珠三角和环渤海地区拥有三大生产基地,直接或间接控股公司26家,现已成为全球电磁线行业领军企业。
精达股份发布2024年半年报。公司2024年上半年实现营收103.74亿元,同比增长19.89%,主要是产销量增长所致;实现归母净利润2.89亿元,同比增长38.62%;实现归母扣非净利润2.72亿元,同比增长37.37%。2024H1公司产品生产和销售总量分别为168,776吨和167,660吨,同比增长12.48%、11.51%。其中特种电磁线产品产量134,705吨、销量133,379吨,同比增长15.10%、14.12%。

精达股份控股子公司恒丰特导产品主要应用于AI服务器、数据中心、军工、航空航天、高速通信、消费电子及医疗器械等领域。恒丰特导的终端用户有国内外知名数据中心、AI消费电子产品、各大研究院所等。
恒丰特导与高校合作研发的“高性能铜及贵金属丝线材关键制备加工技术与应用”项目荣获2024年国家科学技术进步奖二等奖,该项目经过多年协同攻关,突破了高性能铜基丝线材制备加工核心技术瓶颈,开发出具有自主知识产权的成套制备加工技术,成功应用于铜及贵金属丝线材等系列产品,项目推动了我国铜及贵金属丝线材制造水平迈向“超微细”先进水平。
特种导体是在普通导体基础上发展起来的一系列具有独特性能和特殊结构的产品。相对于量大面广的中低端普通导体产品,特种导体采用新材料、新结构、新工艺或新设计,具有技术含量高、适用条件严格、附加值高等特点,最初主要应用于军事工业领域。随着现代社会向电气化、自动化、信息化和网络化方向发展,算力服务器、数据中心、航空航天、通信、医疗、消费电子等领域对应用材料提出了更高的性能要求,特种导体也由早期的军工用途,迅速拓展到上述领域。特种导体市场逐渐向更细的专业化方向发展,相应的研究和开发也随着下游产品的销售的快速增长和更新迭代得到了迅猛发展。特种导体中的代表产品近年来保持市场规模增长,根据QYResearch数据,全球镀银导体市场规模由2017年的19.85亿元增长至2022年的34.69亿元,增长率达到74.80%。

特种导体下游应用领域广泛,随着下游产业的不断升级迭代,终端应用产品向集成化、功能化、微型化等方向发展,特种导体应用市场发展提速,有望带动公司产品需求的进一步增长。在数据通信领域,特种导体主要用于5G 基站和数据中心内部交换机、服务器等网络设备之间的高速互联,实现高速数据传输。随着人工智能(AI)、云计算、大数据等技术的快速发展,数据中心、服务器和高性能计算设备对高速数据传输的需求急剧增加,铜高速连接器由于其在短距离信号传输中的绝对优势,市场规模有望显著提升。LightCounting 数据显示,2023年至2027年高速铜缆市场以年复合增长率25%的速度持续扩张。当前国内高速线缆市场规模已经超过百亿元,预计未来高速铜缆增量市场空间将约千亿元。
恒丰特导2024H1实现营收5.49亿元,同比增长42.32%,主要原因是镀银导体销量增加、主要原材料价格上涨双重叠加;其中镀银导体业务实现营收2.72亿元,同比增长63.57%,主要是因为高速镀银特种导体销量有较大幅度增加,叠加主要原材料价格上涨,联动销售价格上升所致。公司24H1实现归母净利润0.34亿元,同比增长23.71%。恒丰特导生产的镀银高速铜线产品在提高导电性、耐腐蚀性和抗氧化性等方面起到重要作用,主要外资客户有安费诺、Molex、百通、泰科等,国内客户有乐庭、立讯精密、新亚电子、神宇通信、兆龙互联等。公司镀银导体业务营收大幅度增长充分论证了下游铜缆市场的高景气。随着算力需求的不断增长,未来有望快速发展。
 5、PCB:英伟达持续引领AI服务器PCB创新5.1 子行业HDI、高多层板和封装基板将保持较快增速
5、PCB:英伟达持续引领AI服务器PCB创新5.1 子行业HDI、高多层板和封装基板将保持较快增速PCB是电子信息技术产业的核心基础组件,在全球电子元件细分产业中产值占比最大。根据Prismark报告,受复杂多变的国际环境和美元升值带来的汇率变化等问题的影响,2023年全球PCB市场产值同比下降15%,为695亿美元。
在低碳化、智能化等因素的驱动下,数字经济、人工智能、云计算及数据中心、智能汽车、绿色能源、AR/VR、卫星通讯等PCB下游应用领域将蓬勃发展,相关领域的市场需求扩大将进一步带动PCB需求的持续增长。Prismark的最新预测数据显示,2028年全球PCB市场规模将超过900亿美元,2023-2028年年均复合增长率为5.4%。

2024年以来,全球PCB行业呈现结构分化的弱复苏态势。根据Prismark报告,2024年一季度PCB行业产值为167亿美元,环比下降7.1%、同比下降0.1%,预期2024年产值为730.26亿美元、同比增长约5%。受益于人工智能、高速网络和智能汽车产业的发展,相关产品领域延续较高景气度,尤其18层及以上PCB板、高阶HDI板等细分市场迎来强劲的增长,传统多层PCB、封装基板的复苏进展略慢,整个PCB产业朝着高性能、高层数、高精密度、高可靠性升级的趋势愈加明确。根据Prismark报告,预期2028年全球PCB行业市场规模将达到904.13亿美元,2023-2028年复合增长率为5.4%。其中,高多层高速板(18层及以上)、高阶HDI板和封装基板领域有望实现优于行业的增长速度,预期2028年市场规模分别为27.80、148.26、190.65亿美元,2023-2028年复合增长率分别为10.0%、7.1%、8.8%。
 5.2 AI是HDI、高多层板和封装基板等子行业重要的成长驱动力
5.2 AI是HDI、高多层板和封装基板等子行业重要的成长驱动力PCB作为电子产业的一种核心基础组件,广泛应用于AI服务器及周边产品,如GPU载板、Switch载板、OAM(加速模块)、UBB(GPU母板)以及电源、硬盘等配件。相较于传统服务器, AI服务器所需的PCB具有高密度及多层设计、高性能材料、精细制造工艺、优质的信号传输及散热等特性,对PCB供应商的生产工艺以及供应链提出了更高的要求。

 6、投资建议6.1 AI产业链季度收入和净利润梳理
6、投资建议6.1 AI产业链季度收入和净利润梳理
 6.2 AI行业投资建议
6.2 AI行业投资建议AI行业投资建议:
1、英伟达产业链有望持续高景气,重点关注铜连接、光模块和PCB方向,建议关注:(1)光模块领域:中际旭创、新易盛、天孚通信;(2)铜连接领域:精达股份、沃尔核材、立讯精密;(3)PCB领域:胜宏科技、沪电股份、景旺电子、方正科技、生益科技、世运电路;(4)服务器领域:工业富联、浪潮信息等。
2、国产算力供应链有望持续高速成长,国产算力龙头华为昇腾未来成长可期,建议关注:(1)AI芯片领域:寒武纪、海光信息;(2)服务器领域:浪潮信息、神州数码、烽火通信、高新发展、拓维信息、紫光股份等;(3)铜连接领域:华丰科技、意华股份等。
 7、风险分析
7、风险分析下游需求不及预期
AI需求存在波动的可能性,如果下游需求不及预期则可能对产业链相关公司经营及业绩产生影响。
AI技术发展不及预期
科技行业发展与AI等新技术发展关联度较高,如果AI技术发展不及预期,则可能对科技行业产生影响。
中美贸易摩擦反复风险
部分产品技术依然需要依靠海外进口,如果中美贸易摩擦加剧,对行业公司经营及业绩产生影响。
