今天,AMD、亚马逊网络服务 (AWS)、Astera Labs、思科、谷歌、惠普企业 (HPE)、英特尔、Meta 和微软等九大董事会成员联合宣布,由其领导的超级加速器链接 (UALink ) 联盟正式成立,并向社区发出成员邀请。
资料显示,Ultra Accelerator Link(UALink) 是一种用于加速器到加速器通信的开放行业标准化互连。

UALink 联盟则是一个开放的行业标准组织,旨在制定互连技术规范,以促进 AI 加速器(即 GPU)之间的直接加载、存储和原子(atomic)操作。他们的重点是为一个 pod 中的数百个加速器实现低延迟/高带宽结构,并实现具有软件一致性的简单加载和存储语义。UALink 1.0 规范将利用开发和部署了各种加速器和交换机的推广者成员的经验。
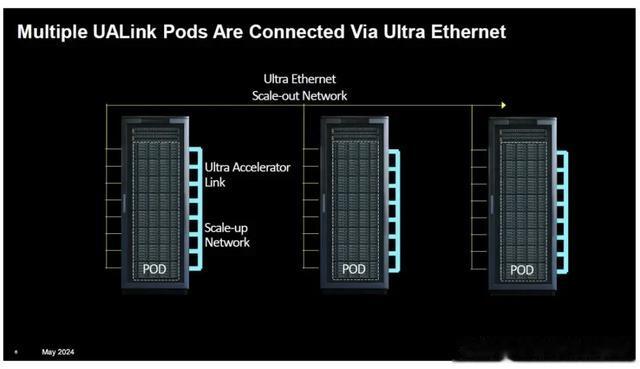
新闻稿指出,联盟公司代表着广泛的行业专业知识,包括云服务提供商、系统 OEM、加速器开发商、交换机开发商和 IP 提供商。目前正在开发用于数据中心 AI 连接的更多使用模型。
UALink 联盟总裁 Willie Nelson 表示:“UALink 标准定义了数据中心内扩展 AI 系统的高速、低延迟通信。我们鼓励有兴趣的公司以贡献者成员的身份加入,以支持我们的使命:为 AI 工作负载建立开放且高性能的加速器互连。”
一个早在五月就发起的协议
其实早在今年五月,AMD、博通、思科、谷歌、惠普企业、英特尔、Meta 和微软就携手成立了超级加速器链接 (UALink:Ultra Accelerator Link)小组,旨在推动数据中心 AI 连接。
这个初始小组名为“超级加速器链路”(UALink),将定义和建立一项开放的行业标准,使 AI 加速器能够更有效地通信。通过创建基于开放标准的互连,UALink 将使系统 OEM、IT 专业人员和系统集成商能够为其 AI 连接数据中心创建一条更轻松的集成、更大的灵活性和可扩展性的途径。
发起人集团公司在基于开放标准、效率和强大的生态系统支持创建大规模 AI 和 HPC 解决方案方面拥有丰富的经验。
据他们所说,随着对 AI 计算的需求不断增长,拥有一个强大、低延迟且高效的扩展网络至关重要,该网络可轻松将计算资源添加到单个实例中。为扩展功能创建开放的行业标准规范将有助于为 AI 工作负载建立一个开放的高性能环境,从而提供尽可能高的性能。
UALink 和行业规范对于标准化下一代 AI 数据中心和实现的 AI 和机器学习、HPC 和云应用程序接口至关重要。该小组将制定一项规范,定义 AI 计算舱中加速器和交换机之间扩展通信的高速、低延迟互连。
根据最初报道,UAlink1.0 规范将允许在 AI 计算Pod内连接多达 1024 个加速器,并允许在舱内连接到加速器(例如 GPU)的内存之间进行直接加载和存储。按照最初规划,UALink 1.0 规范预计将于 2024 年第三季度推出,并提供给加入 Ultra Accelerator Link (UALink) 联盟的公司。
但根据最新的报道,UALink 1.0 规范依然还将为 AI pod 内最多 1024 个加速器实现高达每通道 200Gbps 的扩展连接。而且该规范将于今年向贡献者成员提供,并于 2025 年第一季度提供一般审查。
不过,按照UALink 联盟主席 Kurtis Bowman 所说,UALink 1.0 规范要到2025 年第一季度发布,在他们看来,这是一个重要的里程碑,因为它将建立一个开放的行业标准,使 AI 加速器和交换机能够更有效地通信、扩展内存访问以满足大型 AI 模型要求,并展示行业协作的好处。
探索GPU连接的新方法
GPU 是当前的市场热点,它们可轻松完成矩阵数学运算。它最初设计用于在计算机显示器上快速绘制点,后来被 HPC 从业者发现在大量使用时非常有用。随着 GenAI 的出现,这些小型矩阵专家的需求量巨大,以至于我们称之为 GPU Squeeze。
著名且占主导地位的市场领导者 Nvidia 已经为 GPU 技术开辟了道路。对于 HPC、GenAI 和大量其他应用程序,连接 GPU 提供了一种解决更大问题并提高应用程序性能的方法。
据外媒HPC报道,具体而言,连接GPU有三种基本方法:
1. PCI 总线:标准服务器通常可以在 PCI 总线上支持 4-8 个 GPU。通过使用GigaIO FabreX 内存结构等技术,可以将这个数字增加到 32 个。CXL 也显示出希望,但是 Nvidia 的支持很少。对于许多应用程序来说,这些可组合的 GPU 域代表了下面提到的 GPU 到 GPU 扩展方法的替代方案。
2. 服务器到服务器互连:以太网或 InfiniBand 可以连接包含 GPU 的服务器。这种连接级别通常称为横向扩展,其中较快的多 GPU 域通过较慢的网络连接以形成大型计算网络。自从比特开始在机器之间移动以来,以太网一直是计算机网络的主力。最近,通过引入超级以太网联盟,该规范已被推动以提供高性能。事实上,英特尔已经在以太网上插上了互连旗帜,因为英特尔 Gaudi -2 AI 处理器在芯片上拥有 24 个 100 千兆以太网连接。
值得一提的是,Nvidia 没有加入超级以太网联盟,因为他们在 2019 年 3 月收购 Mellanox 后,基本上独占了高性能 InfiniBand 互连市场。超级以太网联盟旨在成为其他所有人的“InfiniBand”。此外,英特尔也曾经高举 InfiniBand 大旗。
3. GPU 到 GPU 互连:认识到快速且可扩展的 GPU 连接的需求,Nvidia 创建了 NVLink,这是一种 GPU 到 GPU 的连接,目前可在 GPU 之间以每秒 1.8 TB 的速度传输数据。此外,还有一个 NVLink 机架级交换机,能够在无阻塞计算结构中支持多达 576 个完全连接的 GPU。通过 NVLink 连接的 GPU 称为“pod”,表示它们有自己的数据和计算域。
对于其他人来说,除了用于连接 MI300A APU 的 AMD Infinity Fabric 之外,没有其他选择。与 InfiniBand/以太网的情况类似,需要某种“超级”竞争对手联盟来填补非 Nvidia 的“pod 空缺”。而这正是发生的事情。
于是,UALink横空出世。
能给英伟达带来压力吗?
如很多分析人士所说,创建 UALink 的举措反映了业界对高性能计算中可扩展、开放架构需求的日益认识。随着人工智能和数据密集型应用的发展,对此类技术的需求可能会增加,这使得 UALink 成为下一代计算工具的关键组件。
通过提供 NVIDIA NVLink 和 NVSwitch 的可靠和开放替代方案,UALink 旨在打破 NVIDIA 在 GPU 互连市场的主导地位。这一点尤为重要,因为人工智能工作负载和模型不断增长,需要更具可扩展性和更高效的互连解决方案。
毫无疑问,UALink 的推出给 NVIDIA 带来了压力,这将迫使他们继续创新和改进自己的技术。为了保持竞争优势,NVIDIA 需要提高 NVLink 和 NVLink Switch 的性能、可扩展性和成本效益,从而有可能加快行业创新的步伐。
同时,UALink 的开源性质鼓励采用协作方式进行开发。摆脱专有系统可以促进创新,并允许快速采用和改进技术。
分析人士指出,UALink 的潜力不仅仅是提供 NVLink 的替代方案。它旨在创建一个生态系统,无论公司规模大小,公司都可以为先进的互连技术做出贡献并从中受益。对于超大规模企业和大型数据中心而言,采用 UALink 可能意味着显着的成本节约、硬件部署的更大灵活性以及增强的性能。
与此同时,UALink 还是一个技术公司联盟的重大举措,旨在限制 AI 加速器的专有互连,促进开放、竞争和创新。它对市场的影响可能是巨大的,为 AI 和基于加速器的系统营造一个更具活力和成本效益的生态系统。很难在这项使命中找到负面作用。
虽然牌面上说给英伟达带来了竞争。
但是,我们也必须认识到,NVIDIA 的 NVLink 为 UALink 设定了一个高标准和具有挑战性的目标,需要实现和超越。如今,其多代产品已投入生产,提供稳定的高性能解决方案,NVLink 不太可能停滞不前,预计将继续发展以满足预期的未来系统要求。UALink 不仅需要实现其解决方案的稳定性和支持供应商之间的互操作性,还需要超越 NVLink 目前所处的位置。
此外,虽然建立稳定、高性能、可互操作的物理互连(可从多家供应商处获得并支持)是保持竞争力的必要条件,但这还不够。NVIDIA 的 CUDA 软件开发环境也是一个难以克服的巨大障碍。用户不愿意将他们的应用程序代码移植到新硬件上,只为实现相同的性能和功能;他们宁愿将投资集中在解决方案上,为客户提供新的功能、能力和价值。
尽管存在上述挑战,UALink 仍朝着正确的方向前进。该组织由来自先进技术计算生态系统(系统、交换机、云、超大规模器、加速器、I/O、组件设计)的领先供应商组成,他们在合作定义新标准并将其推向市场方面有着良好的记录。
同时,与 UEC 结盟和合作也是一个明智之举,因为生态系统采用的范围越广,成功的可能性就越大。虽然这超出了 UALink 的范围,但与更高级别的软件工作建立联系并提供支持,以帮助用户从 CUDA 移植到标准加速器软件环境,将进一步提高 UALink 实现广泛采用目标的可能性。
为了支持 UALink 的努力,超级以太网联盟 (UEC) 主席 J Metz 博士在五月的小组成立新闻稿中直言:“在很短的时间内,技术行业已经接受了人工智能和 HPC 发现的挑战。在寻求提高效率和性能时,将 GPU 等加速器互连需要整体视角。在 UEC,我们相信 UALink 解决 pod 集群问题的扩展方法与我们自己的扩展协议相得益彰,我们期待在未来共同合作创建一个开放、生态系统友好、全行业的解决方案,以满足这两种需求。”
针对这个协议,英伟达CEO黄仁勋在早前曾直言不会太在意。他同时强调,目前NVLink已推出到第五代,而UALink还只是个提案,至少数年内都不会威胁到NVLink。当UALink第一代推出时,NVLink可能已到第七、八代了;甚至针对未来NVIDIA网络技术改进,内部也有许多不错的想法,不排除将有更进一步创新。
但,有竞争力总是好事。
