
编辑/壹览君
日前,火山引擎正式发布《云原生数据仓库ByteHouse性能白皮书》,白皮书通过使用 SSB 100G、TPC-H 100G、TPC-DS 100G 数据集进行性能测试,展示出 ByteHouse 在查询效率方面的显著成果,并详细介绍ByteHouse在实时数仓、复杂查询等八大应用场景的高性能应用表现。
在数据处理和分析的领域,提升查询效率始终是一项关键挑战。对于 OLAP 来说,性能的关键需求在于能支持实时分析,应对复杂查询,提供快速响应,并具备良好的可扩展性。这些方面,对于满足高效、准确的数据分析需求至关重要。
作为一款OLAP引擎,伴随字节跳动各业务的发展,ByteHouse已经过数百个应用场景和数万用户锤炼,部署规模已超过1万8000台,最大的集群规模在 2400 余个节点,管理总数据量超过700PB,并逐步在外部金融、泛互等场景应用和推广。为了更好支持字节内外部大规模数据和复杂场景应用,性能一直以来是ByteHouse重点打磨的产品基本功。
SSB、TPC-H 和 TPC-DS 是常用于测试分析型数据库/数据仓库的数据集。在白皮书中,通过使用以上三种数据集进行性能测试,并以性能著称的某开源OLAP为基准测试产品,ByteHouse在不同查询项上都有显著的性能提升。以TPC-H 数据集举例,在相同硬件和软件环境下, ByteHouse 查询效率高于本次基准测试产品几十倍。
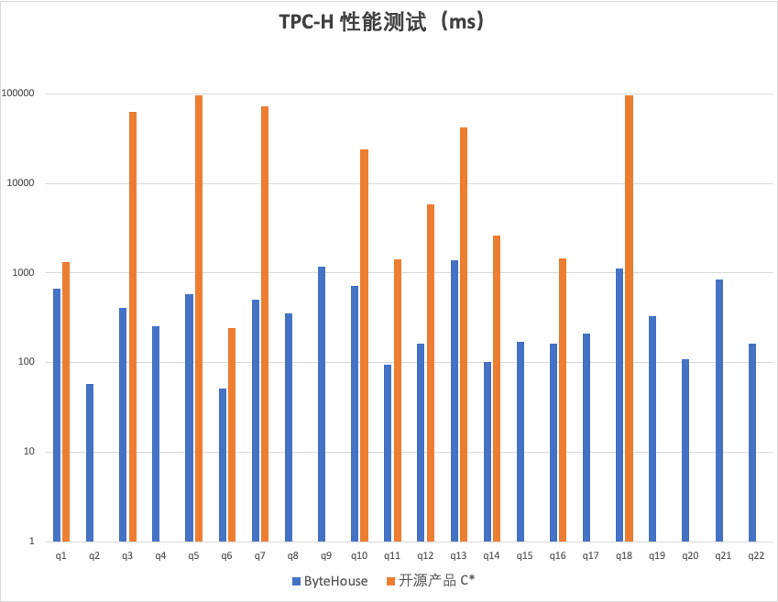
那么,ByteHouse高性能究竟是如何做到的?在白皮书发布会现场,ByteHouse技术专家从复杂查询和宽表查询两个方面,深度介绍ByteHouse性能提升的相关经验。在复杂查询上,ByteHouse解决了ClickHouse缺少优化器支持的问题,从RBO(基于规则的优化能力)、CBO(基于代价的优化能力)、分布式计划生成方面推出了自研优化器,能够准确的计算出效率最大化执行路径,大幅度降低用户查询时间。除此之外,ByteHouse还从Exchange、Runtime Filter以及并行化重构等方向进行了优化。以Runtime Filter举例,在 OLAP 场景中,Join 是制约查询性能进一步突破的瓶颈,ByteHouse 则支持根据不同的场景生成最优的 RuntimeFilter,优化了生成和 Apply 的流程,同时支持 Distributed 和 Local 的 RuntimeFilter,在较大规模集群上也自适应的支持 Shuffle-Aware 的 RuntimeFilter。
在宽表查询上,ByteHouse主要通过全局字典、Zero copy以及UncompressedCache 来进行性能提升。首先,全局字典主要通过编码方式将变长字符串转化为定长数值,针对 Agg、Function和Exchange算子可以直接进行编码值的计算,以此提升计算效率。其次,ByteHouse通过zero copy来优化内存墙,减少数据传输过程中引发的深拷贝开销,提升内存带宽在真正计算上的使用效率。最后,针对单节点上多线程并发引发的锁竞争现象,ByteHouse主要通过优化UncompressedCache确保性能效果。
高并发点查也是本次白皮书发布会介绍的重点能力。在某些企业的销售系统场景中,不同部门的员工可能同时发起多个查询请求,例如查询某个门店在特定时间段的销售额、某个商品在不同地区的销售情况等。如果OLAP系统的高并发点查能力不足,就会存在响应时间慢等情况,在技术层面则体现为索引计算繁重、点查读放大严重、执行链路冗长、锁竞争激烈等问题,ByteHouse通过采用短链路的执行方式、建立unique table 点查索引、提升读链路效率等方式进行优化,在某游戏公司的广告推荐业务上,仅仅 256 Core 的算力,即可支持 10万+QPS。
除此之外,白皮书还从实时数仓、复杂查询、宽表查询、人群圈选、行为分析等八大场景介绍了ByteHouse高性能的应用落地。其中,在人群圈选场景中,ByteHouse可以满足大规模数据的分析和查询需求,并具有一套用于解决集合的交并补计算的定制模型BitEngine,该模型能解决实时分析场景中的性能提升问题。相比于普通和Array或者用户表方式,BitEngine在查询速度上有10-50倍提升,解决了人群圈选中误差大、实时性不强以及存储成本高的痛点。
通过一系列技术优化手段,ByteHouse实现性能进一步提升,缩短查询执行时间、优化资源利用,能应对更复杂的查询场景,为用户提供更流程的数据分析体验。不仅仅是探索性能突破,ByteHouse也在持续拓展产品一体化、易用性、生态兼容性,为业务带来更多的价值,推动各行各业数字化转型。
关注字节跳动数据平台微信公众号,菜单栏「精选内容-白皮书」即可领取《云原生数据仓库ByteHouse性能白皮书》白皮书原文。
