
最近有一篇题为《2美元的H100:GPU泡沫是如何破灭的?》的文章异常火热,甚至投资人都认为英伟达坚挺的股价就是被这一篇文章所摧毁。
这篇看似讨论英伟达基本面的分析文实际上代表的是华尔街对于人工智能的两种态度:
文章作者认为基建投资并非终端需求,而只是中间需求,如果没有终端需求的承接,任何基建投资都是不可持续的。
而反对者则表示,即便当下人工智能商业化模式尚未明确,但AI改变世界成为科技革命的趋势不变,公司们注定会不断加大资本开支,从而利好英伟达。
两派观点都各自拥有一批拥趸,可同时,这两派又存在一种共识:即人工智能非常烧钱,且暂时看不到利润。
而另一边,海外媒体Financial Times以及The information在今年10月各发了一篇文章,标题分别是《中国的人工智能初创企业竞相打入美国市场》、《中国应用在AI视频领域取得早期胜利》。
对AI泡沫的担忧和中国应用在海外攻城略地的现状形成了巨大的反差,在绝大多数公司还在焦虑如何获得足够的收入来支付高昂的模型训练计算成本的时候,国内已经有公司开始谈论较短时间内实现自负盈亏甚至盈利了。
在公认AI尚未有成熟商业化模式的当下,这些公司是怎么做到的?
给大模型算笔账对于OpenAI来说,去年的冬天着实是不堪回首。除去Ilya等科学家大战Sam Altman这场举世瞩目的宫斗大戏之外,还有一个当时外界很少关注的噩耗:
OpenAI背后最大的金主、Altman能够官复原职的靠山,微软,正在秘密打造一款OpenAI的替代品。
据海外媒体报道,微软正尝试将原本集成在Bing当中的GPT模型逐步替换成自研版本,而背后的原因也不是因为GPT能力不足或是提前预见到如今的大规模高管离职动荡,反倒是因为OpenAI的技术能力太强了。
大体来说使用大模型的成本分成两部分,一者是模型训练和数据中心建设,这部分通常是一次性的资本开支尚且不足为惧;二者是日常运行所需的推理成本,绝大多数科技公司的亏损都来自于此。
用户每一次调用都代表着一笔推理费用,而参数越大、能力越强的模型,单次调用成本也就越高,同时伴随着用户数量的提升,推理成本却并不存在规模效应。
与此同时,科技公司又无法让询问“今天天气适合穿什么衣服”和“火箭发动机建造原理”的两种用户进行差异化定价,在轻度用户为主的今天,使用顶级模型几乎和用复兴号拉煤无异。
在这种语境下,题为《How does OpenAI Survive》以及《AI's 600B$ Question》的分析文流传甚广。前者作者对于OpenAI这种盈利模式不清晰、但却需要大量烧钱的模式产生了质疑:
“OpenAI的营收在35亿至45亿美元之间,但其运营亏损可能高达50亿美元,其收入远远无法覆盖成本。而为了推出下一代的大模型GPT5,OpenAI需要更多的数据和算力,这又是一大笔花费。”“但在这些花费之下,我们暂时没有看到一个具有清晰模式的商业产品。”
后者则更为直白:当下AI公司6000亿美元的成本和收入之间,还存在5000亿美元的亏损。


半年过去,2000亿变成6000亿了
这两篇文章其实都在阐述一个相同的观点,即下游应用端尚未发现使用AI带来的收益能够覆盖其使用成本之前,大模型公司想要实现类似苹果芯片那样“技术领先-产品商业化-资金反哺技术”的商业化闭环极为困难。
相比于OpenAI们在技术领先的同时遇到的商业化困境,苹果的Apple Intelligence和Adobe的AI工具Firefly却呈现出另一种状态:即完全不担心用户付费,却由于技术问题导致AI并没能带来实质上的溢价。
即便隆重推出Apple Intelligence,最新款的iPhone 16并未涨价的同时仍然销量平平,分析师们异口同声的表示这就是由于“创新不足”。而Adobe在几乎垄断设计创意市场的前提下,并且在去年四季度加入AI工具之后,其营收在今年三季度不过同比增长12%。
这两家公司的共性在于,在AI浪潮出现之前,他们本就拥有庞大的信众群体和付费基数,这种先发优势显然不是创业公司所能够复制的。
因此OpenAI们和苹果们存在的问题,实际上是技术领先和应用侧提供充足需求之间的错位。
两条腿走路过去一个月,名厨戈登·拉姆齐(Gordon Ramsay)在厨房里“炼丹”的段子视频,在美国的TikTok、Instagram和X 上疯传。

这段由MiniMax旗下产品海螺AI制作的视频爆火并不是个例,在OpenAI的Sora依旧是“内部体验”状态的情况下,来自中国的可灵、PixVerse、Vido都在海外拥有海量用户。
这种现象在海外精英媒体的嘴里,已经被形容为“中国应用在AI视频领域取得早期胜利”,要知道在2022年末在ChatGPT引领文字大模型的时代,中国公司在全球市场几乎没有声音。

今天,以MiniMax为例,它拥有来⾃全球近200个国家的6000万用户,每日与全球用户进行30亿次交互,包括日均处理超3万亿Token,日均生成2000万张图片,日均合成7万小时语音,是国内日处理量、交互时长最高的大模型公司。
在今年8月31日发布旗下首个视频模型abab-video-1之后,海螺AI网页版9月访问量达497万,同比增加867.41%,位列AI产品榜(web)9月全球增速榜、国内增速榜双榜单榜首。今年10月再次迭代,新增图生视频功能。
视频模型在海外的火热甚至带动A股传媒板块,在同花顺等股吧热榜中都出现相关话题。

对于普通用户来说,选择使用一款大模型的理由其实很简单:模型效果足够好。
MiniMax视频模型在VBench(视频⽣成模型评测框架)的第三方独立测试结果中综合排名第一,在画面质量、连贯性、流畅性等多维度均处于领先地位。

衡量视频生成模型的使用效果,主要是从画面质量、连贯性、流畅性、指令响应这几个用户能够感知到的维度,MiniMax视频模型能够准确识别用户上传的图片,并确保所生成视频在形象保持上与原输入图像高度一致,且光影、色调完美嵌入新场景的设定,为创作者提供连贯、深度创作的空间。
指令响应方面,MiniMax视频模型可以理解超出图片内容之外的文本,解构指令框架和深层语义并在视频生成中整合,捕捉到创作者的每一个小心思,实现“所写即所见”。在海螺AI超强的图片信息控制能力加持下,每一位创作者都可以做最任性的导演。
对于绝大多数应用产品来说,用户缺乏付费意愿的本质是缺乏黏性,以尝鲜为目的的使用方式难以形成转化,今天用户获取到的信息中,文字、图片、视频,三种形式基本是等比例共存,也就意味着使用AI生产内容的用户同样会自发的涌入一个全能的产品。
而对MiniMax来说,他们认为提高用户覆盖度和使用深度的唯一办法,就是输出多模态内容。在推出视频模型后,MiniMax拥有了文本、图像、语音、音乐、视频五类模型布局。
在技术能力和应用侧的全方位布局下,MiniMax才能够实现两条腿走路,从而完成商业闭环。
如何实现商业闭环?在一次采访中,MiniMax国际业务总经理盛静远曾提及:“MiniMax现在是所有中国大模型公司里面,少数几个能讲商业化变现,能讲产品跟模型驱动,甚至很有可能能在比较短的时间内实现自负盈亏及盈利的公司”。
在融资不足的现状下,创业公司必须想办法创造收入,而在海外用户付费习惯更好且产品够好的情况下,相比竞争激烈且付费意愿不强的国内市场明显更有增收的空间。国内消费者对订阅制的低黏性有目共睹,最典型的就是中视频平台。
公开数据显示,MiniMax旗下的Talkie全球月活跃用户数已达1100万。
盛静远认为,MiniMax现在处在半山腰的状态,如果做得比较成功,很快就能达到一个正向的商业循环,希望通过技术突破,产品商业化,从而再反哺技术,而不是考虑还有哪些钱会来投。
在技术层面,MiniMax在尚未得到行业认可时就坚定要做MoE架构,到了今天其实已经很难找到说自己不用MoE的语言大模型了。

这种架构最大的意义就在于处理任务时,模型只有特定部分会被激活。例如当用户需要生成一段摘要时,模型会自动激活最适合该工作的部分,不必每次都调动整个大模型,简单来说,就是杀鸡无需用牛刀,从而极大降低前文所述的推理成本。
MiniMax是国内首个完成MoE算法技术路线突破,首个将Linear Attention架构与MoE结合并应用于模型研发的大模型企业。
如果说MoE架构是一种有效调用和分配算力的方式,Linear Attention则是通过降低计算复杂度,从而将每一份算力最大化利用起来的技术,说人话就是,在杀鸡的时候迅速找到角度从而精准下刀。

相比于通用Transformer架构,在128K的序列长度下,新架构成本减少90%以上,且序列长度越长,优势越明显,也就是我们常说的超长文本阅读能力上表现更佳。
新架构的原⽣线性计算复杂度⼤幅减少了⼤模型的训练和推理成本,利用国内有限的算力,达到了一个真正可以比肩GPT-4o的效果。
在产品方面,AI产品活在新闻稿和爆料中着实不少见,隔壁OpenAI画饼都成习惯性操作了,从Sora迟迟未上线,到SearchGPT的测试名额只有10000个,再到前两天又透露说计划12月前推出下一代模型“猎户座(Orion)”,但又是计划首先向与其密切合作的公司授予访问权限...以至于网友都给OpenAI的产品发布做了个非常形象的流程图。
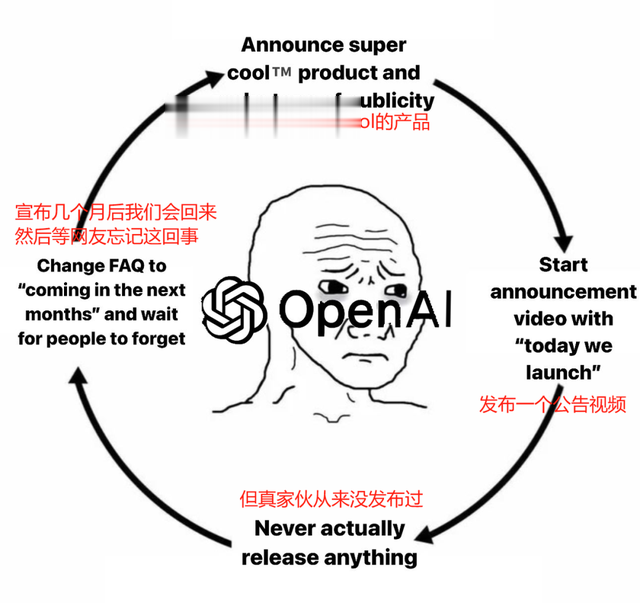
为了让用户满意,MiniMax坚持做到“可见即可用”,拒绝期货产品。这种交付能力也为它赢得了海量用户的青睐。声网(旗下海外公司Agora是OpenAI的合作伙伴)与MiniMax正在合作国内第一个Realtime API,将带来更低延时、更自然、更沉浸的实时语音对话,为企业协作、社交、直播、游戏等多种场景提供新玩法、新机会。
除去海螺AI、星野、Talkie(海外)等多款直接面对用户的APP产品外,MiniMax推出的开放平台产品,接入的2B客户企业和开发者已超3万个。
 尾声
尾声在算力、算法、数据三大核心要素的比拼上,美国巨头拥有先天性的优势,国内无论是互联网大厂还是创业公司,这种客观条件下的差距是无法回避的。
在客观差距存在的前提下,借鉴互联网行业得以领先的事实,MiniMax提出了第四大要素——
用户。
我国最具备竞争力的要素,很可能就是用户规模。用户规模并不是单纯意味着更大的商业化潜力或者市场规模可以用千亿万亿来衡量的概念,更重要的是大量用户带来的“交互频次”。
绝大多数AI产品是由技术极客开发的,但用户却以普通人为主,前者在MoE算法和Linear Attention架构的世界里自由探索,但普通人很可能只关注语音交互是否卡顿。
在每天30亿次的交互下,MiniMax更认为是这些用户在帮助他们做更强大的、以解决问题为导向的应用,甚至是底层技术的提升,用MiniMax CEO闫俊杰的话来说:
“每当我们的模型有重大提升,处理速度有显著提升的时候,就可以看到用户使用的场景和用户使用的深度显著地变高。反过来,这里还有一个曾经发生的真实案例:一个bug导致对话重复错误率变高,当天对话量掉了40%。这也解释了我们坚持技术创新的最底层原因。”
这最终也构成了MiniMax所坚持的一个原则性的目标——
Intelligence with Everyone。
这时我们不妨再回到文章开头的那个问题:人工智能的钱是不是都被英伟达赚走了?
诚然,谈起AI我们总会说国内环境不好、融资情绪差、技术存在差距、商业化不尽人意零零总总,我们也不能否认与美国存在差距的事实。
可回过头来看这一轮AGI革命,曾在电子产业领先的日韩杳无音讯、欧洲只余Mistral一家独苗,还是从硅谷返乡创业,中国的AI人才规模在全球却已经仅次于美国,在一些特定领域的模型甚至出现了反超,对于全球科技的追赶者来说,这已经殊为不易。
如果只盯着英伟达的百亿利润,全球的AI公司都难免黯淡无光。

参考资料:
[1] Chinese Apps Notch Early Wins in AI Video,The information
[2] China’s AI start-ups race to crack US market,Financial Times
[3] 硅谷深思:GPT应用迟未爆发,大模型泡沫根源初探,硅星人Pro
[4] 闫俊杰对话黄明明:AGI,只有一条最难但唯一的道路,暗涌
作者:张泽一
编辑:戴老板
视觉设计:疏睿
责任编辑:张泽一
