2022 年, ChatGPT 的推出引发了人工智能 (AI) 和高性能计算 (HPC) 应用的指数级增长,使人工智能对日常生活越来越重要。大型人工智能模型擅长处理复杂任务,但它们需要大型训练数据集和大型计算系统。这些大型计算工作负载导致芯片尺寸更大、功率密度更高,使得设计节能架构变得更加困难。然而,即使传统的扩展速度减慢,对计算的需求仍在继续增长。
因此,芯片的异构集成 (HI) 对于实现高系统吞吐量(每秒万亿次操作或 TOPS)和能源效率(TOPS/W)以满足不断增长的计算需求至关重要。通过将片上系统 (SoC) 拆分为多个Chiplet并将它们集成到单个封装中,可以显著提高系统的设计灵活性、功能性、带宽、吞吐量和延迟。这可以通过横向、垂直甚至双向拉近Chiplet来实现,从而允许在单个封装中集成更多内存或逻辑。此外,减小die的尺寸并在封装前执行已知良好芯片 (KGD:known good die) 测试可以实现对芯片性能的更高水平的控制,从而提高良率并降低总体成本。
HI 是实现专用于训练大型生成式 AI 模型的高性能系统的潜在解决方案。通过将高带宽内存 (HBM)、中央处理器 (CPU) 和图形处理单元 (GPU) 等芯片集成到一个封装中,吞吐量、延迟和能效得到显著提高,并克服了传统 2D 单片芯片设计的局限性。
如今,Nvidia、Intel 和 AMD 等半导体公司已在自己的产品中利用 HI 技术来运行实时生成式 AI 模型并训练具有数十亿个参数的 LLM(大型语言模型)。在这篇评论中,我们首先介绍当前和新兴的 HI 技术,并讨论它们的优势和当前的局限性。然后,我们调查了 Cerebras、Nvidia、AMD、Intel 和 Tesla 等半导体公司最近为高计算 AI 工作负载设计的 HI 架构的商业部署。
最后,我们还总结了玻璃芯封装的最新进展,并评估了它们的优点和局限性。
异构集成技术的当前趋势将 SoC 划分为Chiplet的主要动机是提高系统功能并降低制造成本。为了提高这些基于Chiplet的系统的性能,多芯片 HI 架构出现了多项创新。我们根据 IEEE 电子封装协会 (EPS) 异构集成路线图的定义,将multi-die 架构分为 2D、2.5D 或 3D,并在图 1 中提供概述。表 1 总结了当前的异构集成技术。
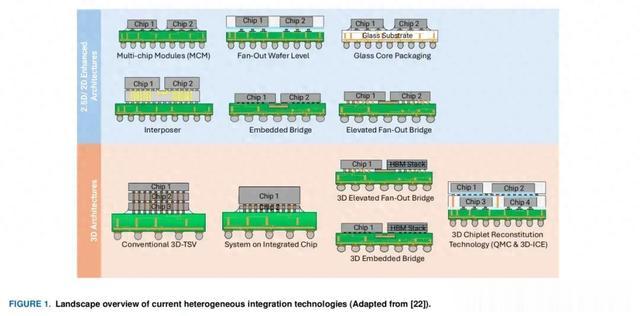
A.多芯片模块架构
多芯片模块 (MCM:Multi-chip-Modules) 是最早的多芯片 2D 架构之一,其中芯片横向放置在有机基板上,以减少导线长度并增加封装带宽,从而提高系统性能和设计灵活性。这是最简单的集成技术之一,但是,由于使用传统的有机基板和基于粗焊料的键合技术,MCM 的互连密度可能会受到限制。这些基于焊料的互连(例如 C4 凸块)很难缩小到更细的间距,因为相邻的互连在键合过程中会短路,从而限制了系统性能。对于大型 AI 系统,需要低延迟和高效的内存访问,但是,由于互连有限,将 MCM 扩展到更大的系统很困难,这可能会成为瓶颈。
B.中介层架构
这些挑战导致了 2.5D 架构的出现,这种架构利用玻璃、硅中介层或局部硅桥等基板来提高横向互连密度。细间距微凸块和硅通孔 (TSV) 技术可以提高堆叠在玻璃或硅中介层上的芯片的互连密度。
然而,随着计算需求的增长,将中介层扩展到大规模 AI 系统的成本可能很高。
因此,基于桥的架构(例如英特尔的嵌入式多芯片互连桥 (EMIB))利用嵌入在封装基板中的局部硅和多个布线层来实现更细的布线间距。芯片间信号位于局部硅桥中,电源/接地互连和其他信号位于有机封装中,从而消除了对 TSV 的需求并简化了组装过程。
与 EMIB 类似,高架扇出桥 (EFB:elevated fanout bridge) 使用局部硅桥来增加芯片间互连密度,桥位于封装基板上方 。这种方法可以进一步降低组装成本和复杂性。与 3D HI 相比,基于桥的技术具有更高的设计功能性、更低的设计复杂性和更简单的热管理,因此有望用于大规模 AI 系统,然而,传统的互连技术(如微凸块)可能会限制其系统性能。这导致了新的键合技术(如铜对铜键合)成为克服这一限制的潜在解决方案。
C.晶圆级封装
晶圆级封装 (WLP:Wafer-Level Packaging) 技术对于基于先进芯片的架构具有重要意义,因为它们可以实现高互连密度、减少互连延迟和增加带宽。通过扇出芯片 I/O 信号,而不是使用传统互连(例如引线键合或 C4 凸块),可以实现高集成密度,从而使 WLP 适用于高性能系统。在传统的 WLP 中,KGD 被封装在环氧模塑料 (EMC:epoxy mold compound) 中以形成重构晶圆。
然而,由于 EMC 和芯片之间的热膨胀系数 (CTE) 不匹配,EMC 可能导致制造问题,从而导致翘曲和芯片移位/错位,并且材料的低热导率使高功率系统的功率耗散变得困难。因此,已经提出了替代材料来嵌入/封装芯片。
D.3D 架构
3D HI 技术是一种很有前途的方法,可以满足 AI 系统的计算需求。使用 TSV 和细间距互连技术(例如微凸块或混合键合),3D 堆叠可以实现高带宽和低延迟系统。许多半导体公司都开发了自己的 3D 架构,包括英特尔的 Foveros 、三星的 X-Cube和 AMD 的 3D V-Cache 产品,该产品使用台积电的集成芯片系统 (SoIC) 技术。SoIC 技术将 SoC 划分为多个芯片,这些芯片可以重新集成到各种 3D 配置中。这允许灵活地集成不同技术节点、
材料和芯片尺寸的无源和有源芯片(见图 2),以支持超过 20 Tbps 的内存带宽。
与传统的 3D IC 微凸块相比,混合键合的键合密度大幅提高了 16 倍,并降低了 IR 降等电寄生效应,降低了每位的能耗。除了更精细的互连间距外,SoIC 技术还具有更高的金属布线密度和更薄的键合层,可以提高热性能。然而,该技术面临着与传统 3D IC 类似的挑战。由于严格的表面清洁度和化学机械抛光 (CMP) 要求,缩小混合键合间距变得越来越困难。
值得注意的是,3D 系统带宽由堆栈总数和底部芯片的大小决定。虽然增加 3D 堆栈中的芯片数量对于增加内存带宽或计算能力是可取的,但组装复杂性和成本可能会显著增加。此外,散热和机械稳定性变得更加困难。液体冷却已被提议作为一种有助于散热的潜在解决方案 ,然而,这一领域超出了本文的讨论范围。
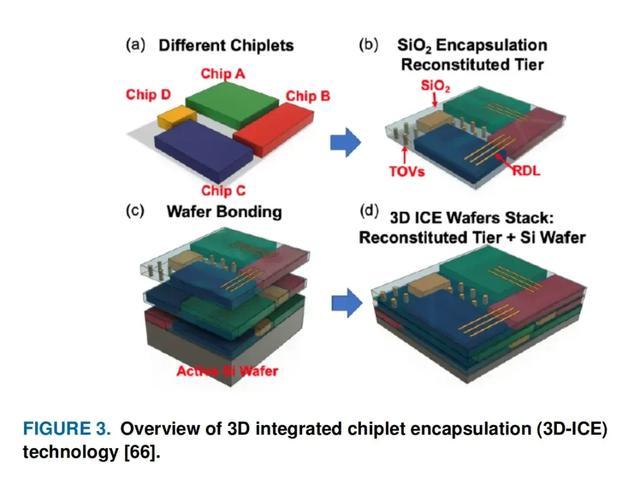
最近,使用 WLP 技术的其他 3D 架构也出现了。M.-J. Li 等人提出了一种晶圆级芯片重构技术,称为三维集成芯片封装 (3D-ICE),其中多个芯片封装在低温 SiO2中以形成重构 SiO2 层,如图 3 所示 。然后可以对该SiO2层进行后处理以实现高密度 3D HI。同样,英特尔提出了准单片芯片 (QMC:quasi-monolithic chip) 作为一种新的 3D HI 架构,其中芯片也封装在超厚二氧化硅层中。SiO作为封装材料具有多种优势。由于其低损耗特性,它可以促进高速信号传输,并且由于不需要固化,因此基本上不存在芯片移位或错位,并且它与现有的CMOS制造工艺兼容,从而模糊了封装处理和设备处理之间的界限。
尽管SiO2具有出色的电气性能,但该材料的热导率较低,这可能导致热性能不佳。因此,A. Victor 等人提出了一种带有集成散热器的芯片重组工艺。30 µm 厚的无源芯片被封装在 15 µm 厚的 ICP-PECVD SiO2中 。蚀刻掉沉积在芯片顶部的氧化物,然后在芯片上电镀 36 µm 的铜。单片铜散热器有助于降低芯片层的最高结温,从而解决了大多数 FOWLP 解决方案所面临的电气和热性能权衡问题。
人工智能的异构集成趋势A.HI 产品的当前格局
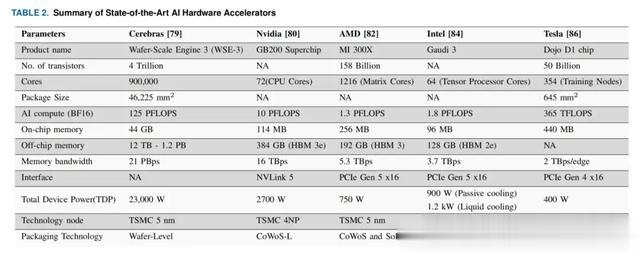
人工智能的快速发展推动了 HI 架构的多种商业部署,这些架构专门用于加速最大的人工智能工作负载。在本节中,我们调查了最近报告的行业产品,并在表 2 中总结了它们的规格。
2024 年,Cerebras 推出了 WSE-3,这是一款晶圆级人工智能加速器,速度是 WSE-2 的两倍,旨在训练比 GPT-4 和 Claude 大 10 倍的模型。有趣的是,Cerebras 使用传统的设备缩放和晶圆级集成来超越摩尔定律。借助台积电的 5 纳米技术,在单个晶圆上制造了四万亿个晶体管,芯片尺寸约为 GPU 的 57 倍。然而,计算和内存组件是分离的,以实现内存容量扩展,因此单个 WSE-3 系统能够比由 10,000 个 GPU 组成的集群更高效地存储和训练具有 24 万亿个参数的模型。
相比 Cerebras,其他半导体公司正在使用先进的封装技术来设计大规模 AI 系统。Nvidia 宣布推出 GB200 Grace Blackwell 芯片,该芯片由两个 Blackwell GPU 和一个 Grace CPU 组成。该芯片专为具有超过 10 万亿个参数和 384 GB 片外内存的大型语言模型而设计,设备总功率为 2700 W。为实现这一目标,Nvidia 使用了台积电的晶圆上芯片基板 (CoWoS)-L 封装技术。该封装技术使用局部硅互连 (LSI) 芯片和重构中介层来实现大集成面积、带宽和低延迟的高性能系统。
AMD 在其 MI300X 封装中采用了小芯片方法,并结合了中介层技术和 3D 堆叠,以实现高性能和内存带宽。MI300X 由多个 GPU 小芯片、I/O 芯片和 192 GB 高带宽内存 (HBM) 组成,总设备功率为 750 W。CPU 复合芯片 (CCD) 和加速器复合芯片 (XCD) 以 3D 方式堆叠在 I/O 芯片 (IOD) 上,以实现低信号延迟。最后,使用大型硅中介层集成 3D 堆栈和高带宽内存 (HBM) 芯片,以实现高性能系统 。
英特尔的 Gaudi-3 加速器产品利用其嵌入式桥接芯片技术将两个英特尔计算芯片与 128 GB HBM 集成在一起,以增强大规模 AI 系统。与其他基于桥接的中介层技术类似,EMIB 允许英特尔提高设计功能并降低组装成本。虽然 Gaudi-3 加速器不如 Nvidia 的 H100 强大,但它是一款经济高效的高性能系统。
最后,特斯拉凭借 Dojo 进入了 AI 市场,这是一款针对大型神经网络训练进行了优化的芯片。
Dojo 的总设备功率为 400 W,比竞争对手低得多,专为驾驶情况的实时数据处理而设计。特斯拉正在使用台积电的集成扇出晶圆系统 (InFo-SoW) 技术实现高密度、低延迟系统。
总之,随着人工智能模型的规模和复杂性不断增长,技术已经转向 HI 和新兴 HI 技术。
B.芯片间接口和通信协议
随着单个系统中芯片数量的增加,芯片间 (D2D) 接口对于各个组件之间的数据移动变得越来越重要。AMD 的 Infinity Fabric和英特尔的高级接口总线 (AIB) 是 D2D 接口,用于其 AI 加速器产品中,以最大限度地减少延迟并最大化带宽。
然而,随着系统变得越来越多样化,芯片由不同的供应商提供,通用芯片互连 Express (UCIe) 协议已开始成为通用行业标准 。标准 D2D 协议对于设计灵活性和可扩展性至关重要,尤其是对于大规模 AI 和 HPC 系统以及网络系统。图 4 显示了异构计算的不同标准协议的摘要。
玻璃封装A.玻璃芯基板封装的出现
AI 应用通常需要更大的中介层和非常高密度的互连以实现高带宽。这些严格的要求加上可靠性和性能,要求开发和实施先进的封装技术来构建大型封装。
随着对适用于 AI 和 HPC 应用的更先进封装技术的需求,利用玻璃作为核心基板因其众多优势而最近引起了极大关注 。英特尔最近展示了他们的第一款玻璃基板测试芯片,并宣布了他们朝着玻璃封装发展的轨迹,以满足对更强大计算的需求。(图 5(a))韩国 SKC 的子公司 Absolics Inc. 也已开始准备小批量制造(SVM)其玻璃基板(图 5(b)),旨在以亚马逊、Meta 和微软等超大规模企业为潜在客户。

B.玻璃芯封装的优势
基于玻璃的中介层通过提高信号完整性、支持高密度互连、集成光通信、优化热管理以及确保可靠性和可扩展性,增强了用于 AI 应用的半导体封装的带宽能力。这些特性使玻璃中介层成为实现高性能计算和实现高级 AI 功能的重要组件。玻璃表面光滑/表面粗糙度极低,可以实现细线和空间的缩放,这对于实现非常高密度的互连至关重要。
此外,玻璃由 Si-O 键组成的表面结构有助于粘附各种聚合物材料,用作介电树脂和感光树脂。将玻璃的低介电常数与多层中介层结构的低介电常数累积层相结合,可以显着降低系统的延迟。这一特性在最小化信号传播延迟和减少相邻互连之间的串扰方面起着至关重要的作用,尤其有利于高速电子设备和共封装光学器件。
此外,玻璃基板降低了互连之间的电容,从而实现了更快的信号传输并提高了整体系统性能。在数据中心、电信和高性能计算等速度至关重要的关键应用中,采用玻璃基板可以大大提高系统效率并增加数据吞吐量。
此外,玻璃的低介电常数还支持卓越的阻抗控制,这对于保持整个电路的信号完整性至关重要。这一特性在射频应用中尤其有利,因为精确的阻抗匹配对于优化功率传输和最大限度地减少信号损失至关重要。玻璃基板确保整个基板表面的电气特性一致,从而能够设计和生产具有更高可靠性和性能的高频电路。
此外,与有机封装相比,玻璃具有出色的尺寸稳定性,有助于提高层间精度,这是在多层玻璃中介层中实现非常高的互连密度的关键。这不仅有助于减小焊盘尺寸,还有助于将细线和走线缩小到<1μm,从而增加多层中介层中每个再分布层中的IO数量。此外,玻璃基板的热膨胀系数(CTE)在3-12 ppm /◦C范围内。这可以减轻玻璃与硅(CTE=3 ppm/◦C)芯片以及玻璃与印刷线路板(CTE=17 ppm/◦C)之间的 CTE 不匹配问题。
能够构造玻璃是封装和中介层应用玻璃芯基板的另一个优势。
玻璃构造可以是以下任何一种类型:(a) 玻璃通孔 (TGV:Through Glass Vias),(b) 盲玻璃腔 (BGC:Blind Glass Cavities),或 (c) 玻璃腔 (TGC:Through Glass Cavities)。TGV 可以通过激光诱导深蚀刻 (LIDE:Laser Induced Deep Etching) 形成,首先对玻璃进行局部激光修改,然后进行湿化学蚀刻工艺,以最大限度地减少制造过程中微裂纹的积累。BGC 和 TGC 可以通过激光加工轻松形成,必要时可以进行湿蚀刻工艺。BGC 和 TGC 对于将芯片嵌入 BGC 和 TGC 非常重要,这被称为玻璃面板嵌入 (GPE)。制造所需尺寸的腔体,并使用精度为几微米的自动芯片拾取和放置工具将芯片放入这些腔体中。GPE 工艺非常适合异构集成,其中不同尺寸和功能的芯片(包括电容器和磁电感器等无源元件)内置在封装中。在这种方法中,电容器和电感器保持在靠近电力输送/IVR 等应用所需的位置。图 6 显示了 GPE 中使用的典型工艺流程。
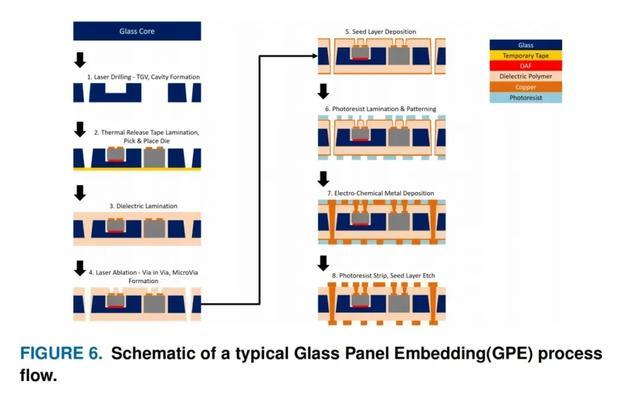
利用先进的 GPE 工艺,可以轻松地将热解决方案集成到封装中以消除热量。例如,对于带有 TGC 的 GPE,可以将隔热材料和散热器附着到玻璃基板的背面。对于 BGC,可以在减薄/研磨基板后加入散热器来消除热量。GPE 架构可以轻松地从 2.5D 架构调整为包括 3D 集成,其中可以使用以下方法之一:
(a)例如,可以将逻辑芯片与玻璃芯顶部和底部的 RDL 一起嵌入玻璃腔中,然后在顶部组装存储器芯片以生成具有短互连距离和小得多的外形尺寸的 3D 结构,从而显着降低封装的高度;
(b)无源芯片可以嵌入结构化玻璃中,并且可以通过倒装芯片工艺在玻璃封装结构上组装多个芯片 ;
(c) 此外,GPE 实现了共封装光学器件等先进封装概念,其中可以将电子芯片嵌入玻璃腔体(芯片背面采用上述散热解决方案),并在封装顶部组装光子芯片 (PIC)。通过将 PIC 安装在顶部,可以轻松地从顶部安装光纤耦合器以及任何所需的散热解决方案。
最后,除了各种优越的性能外,玻璃对封装中基板格式的限制更少。虽然硅只能在圆形晶圆中加工,但玻璃可以实现面板工艺,从而降低成本。例如,300 毫米晶圆可容纳 2,500 个 6 毫米 x 6 毫米尺寸的封装,而 600 毫米 x 600 毫米面板可容纳 12,000 个封装。
C.目前玻璃的限制
玻璃基板固有的易碎性带来了重大挑战,尤其是当行业采用更薄的基板来满足对更高设备集成度和性能的需求时。薄玻璃板有时薄至 100µm 或更薄,在处理和制造过程中特别容易损坏。这种在压力下开裂或破碎的风险凸显了专门设备和定制工艺的必要性,这些工艺旨在安全地处理这种材料。
除了处理困难之外,玻璃还表现出相对较低的散热性。尽管玻璃比有机层压板导热性更好,但与硅相比,玻璃的导热性较差。为了克服与玻璃导热性低相关的限制,已经证明了将铜结构(例如通孔封装通孔 (TPV)、铜块和重分布层 (RDL) 中的铜迹线)结合到玻璃基板中的方法 [107]。此外,用于嵌入式和基于基板的封装的下一代热界面材料 (TIM) 也正在积极开发中,重点是降低热界面电阻,以实现芯片的最大热传递。
致谢:
本文作者包括来自佐治亚理工学院的MADISON MANLEY, ASHITA VICTOR, HYUNGGYU PARK, ANKIT KAUL,MOHANALINGAM KATHAPERUMAL, AND MUHANNAD S. BAKIR,特此感谢。
