打造能够在非结构化环境中自主执行各种任务的人形机器人,一直以来都是机器人界的一个重要目标。
通过观察人类行为便能教授机器人技能的视觉模仿学习方法也因此备受业界关注。
在视觉模仿学习方法的助力下,人形机器人实现了自主执行复杂技能,但由于数据依赖、环境多变、模型复杂、任务多样等多重因素影响,视觉模仿学习方法的泛化能力往往有限,这些自主操控技能大多局限于一个特定场景。
▍提出改进策略,实现训练提升与泛化能力飞跃
为了提高视觉模仿学习方法的泛化能力,研究人员正在探索多种解决方案,包括使用更多样化的数据集、改进算法以提高模型的鲁棒性、以及开发能够更好地处理新环境和任务的模型。
其中,由清华大学交叉信息研究院许哲华研究组提出的新型视觉模仿学习算法——3D扩散策略(DP3),通过融合3D视觉表征和扩散模型实现了对复杂机器人操作的学习和执行,提高了学习效率和泛化能力,展现出复杂和多样化场景应用的潜力。

但与此同时,由于3D 视觉运动策略通常依赖于位置固定的精确相机校准和细粒度点云分割,不能直接部署在人形机器人,准确性也需要进一步提高才能在更复杂的任务中有效执行,这带来人形机器人在部署方面的挑战。
面对这一问题,来自斯坦福大学、西蒙弗雷泽大学、卡内基梅隆大学等院校的研究人员前不久携手对此进行深入研究,并提出了改进的3D扩散策略即 3D视觉运动策略iDP3。
对于使用3D扩散策略时人形机器人等通用机器人相机支架不固定,使得相机校准和点云分割不切实际这一问题。研究团队提出了直接使用来自相机框架的 3D 表示,并将这类 3D 表示称为自我中心 3D 视觉表示。这一新型 3D 视觉运动策略使全尺寸人形机器人能够将实际操作技能推广到各种现实世界环境,并使用仅在实验室中收集的数据进行训练。

此外,为了证明iDP3能让全尺寸人形机器人仅依靠实验室数据在多种现实场景中自主执行技能,研究团队还设计了一款现实世界模仿学习系统。该系统将人类关节映射到机器人上,结合腰部自由度和主动视觉,显著扩展了操作空间,特别是在处理不同高度任务时表现优异。通过大量实验和研究,团队验证了iDP3在现实世界中的超强泛化能力和高效性。
▍进行调整优化, 3D视觉运动策略四大改进
具体来说,相较3D扩散策略(DP3),研究团队提出的 3D视觉运动策略(iDP3)主要在以下几个方面进行了调整与优化:
视觉输入扩展。在利用以自我为中心的3D视觉表示时,消除无关点云(如背景或桌面)是一大挑战,尤其是在不依赖基础模型的情况下。为应对这一挑战,研究团队提出了一个既简单又有效的解决方案:扩展视觉输入范围。与以往系统采用的标准稀疏点采样不同,研究团队大幅增加了采样点的数量,以更全面地捕捉整个场景信息。尽管此方法看似简单,但在实际实验中已被验证其有效性。

DP3策略应用

iDP3策略应用
视觉编码器改进。研究团队将DP3中的MLP视觉编码器替换为了金字塔卷积编码器。他们发现,在从人类数据中学习时,卷积层相较于全连接层能够产生更为平滑的行为表现。同时,通过结合来自不同层的金字塔特征,可以进一步提升预测的准确性。

DP3策略应用

iDP3策略应用
预测范围延长。由于人类专家的操作存在抖动和传感器噪声,使得从人类演示中学习变得非常困难,这也导致DP3在进行短期预测时面临挑战。为此,研究团队通过延长预测范围,有效地缓解了这一问题。

DP3策略应用

iDP3策略应用
实施细节优化。为了进行优化,研究团队使用AdamW对iDP3及所有其他方法进行了300次训练。在扩散过程中,他们采用了50个训练步骤和10个推理步骤,并使用DDIM进行加速。对于点云采样部分,研究团队摒弃了DP3中的最远点采样(FPS),而是采用了体素采样与均匀采样的级联方式,确保采样点能够全面覆盖三维空间,并大大提高了推理速度。
▍测试系统效果,3D视觉运动策略有效性检验
为验证iDP3策略的有效性,研究团队依托全尺寸人形机器人Fourier GR1及数据收集系统,构建了真实世界的模仿学习系统,并在现实世界进行部署。

在部署中,团队启用了Fourier GR1上身25个自由度,展示机器人灵活性和多功能性,并采用推车移动以确保稳定性。为捕捉高质量3D点云数据,团队选用了固态LiDAR摄像头RealSense L515,安装在机器人头部。同时,考虑到真实环境场景多样性,团队采用高度可调的推车以简化操控。

为实现远程操作,团队还引入Apple Vision Pro(AVP),机器人通过Relaxed IK算法准确跟随姿势,实现精准操控,并将腰部纳入远程操作管道,扩大工作空间灵活性。然而,使用LiDAR传感器导致远程操作存在约0.5秒延迟,双LiDAR配置延迟过高不可行。在数据收集方面,团队收集了观察-动作对的轨迹数据,包括视觉数据和本体感受数据,但尝试使用末端执行器姿势作为本体感受/动作数据并未显著提升性能。
利用收集到的人类演示数据训练iDP3,研究团队成功实现了无需相机校准或手动点云分割的无缝场景转移。同时,为评估系统有效性,团队以Pick&Place任务为基准,进行了多种设置下的训练与测试。

结果显示,iDP3在准确性和平滑度上均表现优异,尤其在自我中心视角和较少演示次数下效果显著。尽管与微调R3M编码器的DP相比略有不足,但iDP3展现出了更强的泛化能力。

此外,研究团队对DP3的改进进行了消融研究,发现改进的视觉编码器、缩放的视觉输入和更长的预测范围均对提升策略性能至关重要。同时,iDP3的训练时间相比Diffusion Policy大幅减少,即使点云数量增加,效率依然保持。

根据收集到的人类演示训练 iDP3,研究团队不依赖前面提到的相机校准或手动点云分割。便可无缝转移到新场景,而无需进行校准/分割等额外工作。
为进一步验证iDP3的实用性,研究团队展示了其在人形机器人上的更多功能,并与DP进行了深入比较。

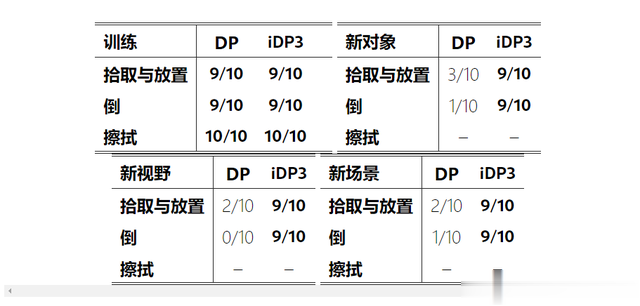
在Pick&Place、Pour和Wipe三个日常任务中,iDP3均表现出色,尤其在视角不变性、对象泛化和场景泛化方面展现出了显著优势。
即使在视角变化大、新物体或复杂场景下,iDP3也能保持稳健的性能,而DP则受到较大影响。这些结果表明,iDP3更适用于具有挑战性和复杂性的现实世界应用。
总的来说,iDP3通过其3D视觉运动策略,在人形机器人上实现了高效、准确且泛化能力强的操作表现,为机器人技术的进一步发展提供了有力支持。
