大家好,我是咔咔 不期速成,日拱一卒
项目中准备使用ElasticSearch,之前只是对ElasticSearch有过简单的了解没有系统的学习,本系列文章将从基础的学习再到深入的使用。
咔咔之前写了一份死磕MySQL文章,如今再入一个系列玩转ElasticSearch。
本期文章会带给大家学习ElasticSearch的基础入门,先把基础学会再深入学习更多的知识点。

文档(Document)
ElasticSearch是面向文档的,文档是所有可搜索数据的最小单位,例如MySQL的一条数据记录
文档会被序列化成为json格式,保存在ElasticSearch中
每个文档都有一个唯一ID,例如MySQL中的主键ID
JSON文档
一篇文档包括了一系列的字段,例如数据中的一条记录
json文档,格式灵活,不需要预先定义格式
在上期文章中把csv文件格式文件通过Logstash转化为json存储到ElasticSearch中
文档的元数据
index :文档所属的索引名
type:文档所属类型名
id:文档唯一ID
source:文档的原始JSON数据
version:文档的版本信息
score:相关性分数

索引
索引是文档的容器,是一类文档的结合,每个索引都有自己的mapping定义,用于定义包含的文档的字段和类型
每个索引都可以定义mapping,setting,mapping是定义字段类型,setting定义不同的数据分布
Type
7.0之前,一个Index可以设置多个type,所以当时大多数资料显示的都是type类型与数据库的表
7.0之后,一个索引只能创建一个type“_doc”
若不好理解,可以对比MySQL类比一下
DatabasesElasticSearchTableIndex(Type)RowDocumentColumnFiledSchemaMappingSqlDsl节点
节点是一个ElasticSearch的实例,本质上就是java的一个进程,一台机器可以运行多个ElasticSearch进程,但生产环境下还是建议一台服务器运行一个ElasticSearch实例
每个节点都有名字,通过配置文件配置,或者启动时 -E node.name=node1
每个节点在启动后,会分配一个UID,保存在data目录下
主节点:master
默认情况下任何一个集群中的节点都有可能被选为主节点,职责是创建索引、删除索引、跟踪集群中的节点、决定分片分配给相应的节点。索引数据和搜索查询操作会占用大量的内存、cpu、io资源。因此,为了保证一个集群的稳定性,应该主动分离主节点跟数据节点。
数据节点:data
看名字就知道是存储索引数据的节点,主要用来增删改查、聚合操作等。数据节点对内存、cpu、io要求比较高,在优化的时候需要注意监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
负载均衡节点:client
该节点只能处理路由请求,处理搜索,分发索引等操作,该节点类似于Nginx的负载均衡处理,独立的客户端节点在一个比较大的集群中是非常有用的,它会协调主节点、数据节点、客户端节点加入集群的状态,根据集群的状态可以直接路由请求。
预处理节点:ingest
在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持ingest操作的,也可以专门将某个节点配置为ingest节点。
分片
分片分为主分片,副本分片
主分片:用以解决数据水平扩展的问题,将数据分布到集群内的所有节点上,一个分片是一个运行的Lucene(搜索引擎)实例,主分片数在创建时指定,后续不允许修改,除非Reindex
副本:用以解决数据高可用的问题,可以理解为主分片的拷贝,增加副本数,还可以在一定程度上提高服务的可用性。
在生产环境中分片的设置有何影响
分片数设置过小会导致无法增加节点实现水平扩展,单个分片数据量太大,导致数据重新分配耗时。假设你给索引设置了三个主分片 ,这时你给集群加了几个实例,索引也只能在三台服务器上
分片数设置过大导致搜索结果相关性打分,影响统计结果的准确性,单个节点上过多的分片,会导致资源浪费,同时也会影响性能
从ElasticSearch7.0开始,默认的主分片设置为1,解决了over-sharding的问题
查看集群健康状态
执行接口
get _cluster/health
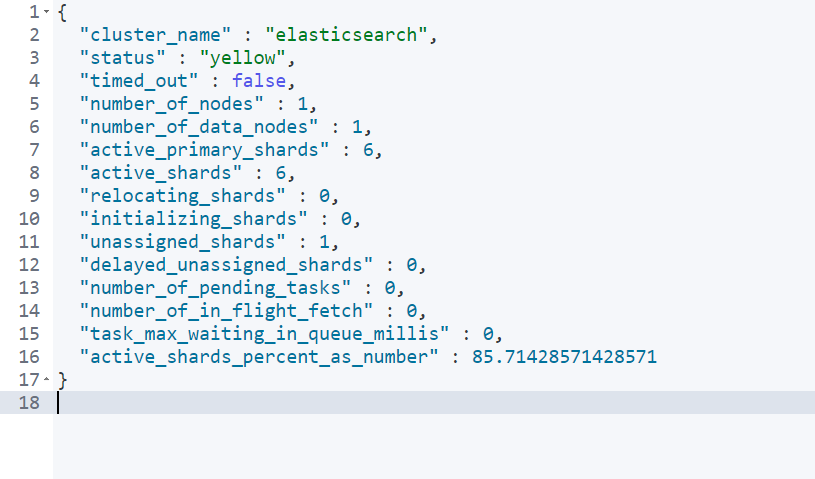
green:主分片与副本都正常分配
yellow:主分片全部正常分配,有副本分片未能正常分配
red:有主分片未能分配,当服务器的磁盘容量超过85%时创建了一个索引
二、Result Api接口作用get movies查看索引相关信息get movies/_count查看索引的文档总数post movies/_search查看前10条文档get /_cat/indices/movies?v&s=index获取索引状态get /_cat/indices?v&health=green查看状态为绿色的索引get /_cat/indices?v&s=docs.count:desc根据文档数据倒序get /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs,count,mt查看索引具体字段get /_cat/indices?v&h=i,tm&s=tm:desc查看索引所占的内存get _cluster/health查看集群健康状态三、文档的基本CRUD操作create 一个文档
支持自动生成文档ID和指定文档ID两种方式
通过调用post /movies/_doc 系统会自动生成文档ID
使用http put movies/_create/1 创建时,url中显示指定_create ,如果该id的文档已经存在,操作失败

Index 文档
Index和Create区别在于,如果文档不存在,就索引新的文档。否则现有文档会被删除,新的文档被索引并且版本信息+1

update 文档
update方法不会删除原有文档,而是实现真正的数据更新

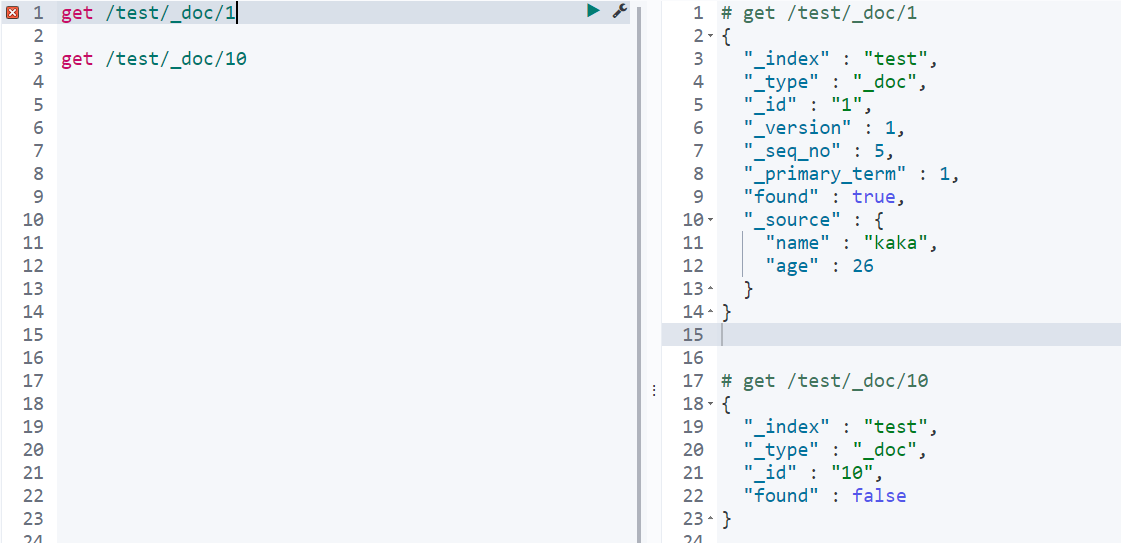
get 一个文档
检索文档找到,返回状态码200,文档元信息,这里需要注意一下版本信息,同一个id的文档,即被删除版本号也会不断增加
找不到文档,返回状态码404
Bulk Api
支持在一次Api调用中,对不同的索引进行操作,支持index、create、update、delete
可以在url中指定index,也可以在请求的payload中进行
操作中单条操作失败,不会影响其它继续操作,并且返回结果包括了每一条操作执行的结果
多索引bulk批量操作案例:

这里需要大家注意:bulk api 对json语法有严格的要求,每个json串不能换行,只能放一行,同时一个json和另一个json串之间必须有一个换行。
单索引bulk批量操作
如果操作的是同一个索引时,bulk语句还可以变化为以下方式

单条的返回结果可以自己尝试一下,可以看到单索引bulk跟多索引bulk之间的区别显而易见。
bulk size的最佳大小
bulk request 会加载到内存里,如果太大的话,性能反而会下降,因此需要不断尝试最佳的bulk size,大小最好控制在5~15MB即可,至于条数需要根据当下数据量再调整。
批量读取_mget
道理跟MySQL都一样,只要是批量在一定合理的范围内都会减少网络连接所产生的开销,从而提高性能
需要注意批量获取每个json之间是需要逗号隔开的,否则会报json解析异常
get /_mget{ "docs": [ {"_index":"test","_id":"1"}, {"_index":"movies","_id":"2"} ]}
批量搜索_msearch
post kibana_sample_data_ecommerce/_msearch{}{"query":{"match_all":{}},"size":1}{"index":"kibana_smaple_sample_data_flights"}{"query":{"match_all":{}},"size":1}
常见的错误状态
问题原因无法连接网络故障、集群异常连接无法关闭网络故障、节点出错429集群过于繁忙4xx请求体格式错误500集群内部错误四、倒排索引倒排索引是由单词词典、倒排列表两部分组成,单词词典记录的所有文档的单词,记录单词倒排列表的关联关系
倒排列表记录了单词对应的文档结合,由倒排索引项组成,分别为文档ID、词频TF、位置、偏移
案例:
文档ID文档内容1kaka ElasticSearch2ElasticSearch kaka3ElasticSearch niuniu倒排列表就为:
文档ID词频位置偏移量111<10,23>210<0,13>310<0,13>ElasticSearch可以为json文档中的每个字段设置自己的倒排索引,也可以指定某些字段不做倒排索引
若不做倒排索引,虽可以节省存储空间,但字段无法被搜索
五、使用Analyzer进行分词首先你得知道什么是分词:Analysis把全文本转换为一系列单词的过程叫做分词
Analysis通过Analyzer实现的,可以通过ElasticSearch内置的分析器、或使用定制分析器
分词器除了写入时转换此条,查询query时也需要用相同的分析器对查询语句进行分析
案例:ElasticSearch kaka
通过分词就转化为 elasticSearch和kaka,这里需要注意的是通过分词转化后把单词的首字母变为小写
Analyzer的组成
Character Fiters :针对原始文本处理,例如去除html
Tokenizer : 按照规则切分单词
Token Filter : 将切分的单词进行加工,转为小写,删除stopwords并增加同义词
ElasticSearch的内置分词器
# Standard Analyzer - 默认分词器,按词切分,小写处理# 只做单词分割、并且把单词转为小写get _analyze{ "analyzer":"standard", "text":"If you don't expect quick success, you'll get a pawn every day"}# Simple Analyzer - 按照非字母切分(符号被过滤),小写处理# 按照非字母切分例如字母与字母之间的——,非字母的都被去除例如下边的 2get _analyze{ "analyzer" :"simple", "text":"3 If you don't expect quick success, you'll get a pawn every day kaka-niuniu"}# Whitespace Analyzer - 按照空格切分,不转小写# 仅仅是根据空格切分,再无其它get _analyze{ "analyzer":"whitespace", "text":"3 If you don't expect quick success, you'll get a pawn every day"}# Stop Analyzer - 小写处理,停用词过滤(the,a, is)# 按照非字母切分例如字母与字母之间的——,非字母的都被去除例如下边的 2# 相比Simple Analyze,会把the,a,is等修饰性词语去除get _analyze{ "analyzer":"stop", "text":"4 If you don't expect quick success, you'll get a pawn every day"}# Keyword Analyzer - 不分词,直接将输入当作输出# 不做任何分词,直接把输入的输出,假如你不想使用任何分词时就可以使用这个get _analyze{ "analyzer":"keyword", "text":"5 If you don't expect quick success, you'll get a pawn every day"}# Patter Analyzer - 正则表达式,默认\W+(非字符分隔)# 通过正则表达式进行分词,默认是\W+,非字符的符号进行分割get _analyze{ "analyzer":"pattern", "text":"6 If you don't expect quick success, you'll get a pawn every day"}# Language 一提供了30多种常见语言的分词器# 通过不同语言进行分词# 会把复数转为单数 ,会把单词的ing去除get _analyze{ "analyzer":"english", "text":"7 If you don't expect quick success, you'll get a pawn every day kakaing kakas"}# 中文分词器# 这个需要安装# 执行: ./bin/elasticsearch-plugin install analysis-icu# 重启:nohup ./bin/elasticsearch > /dev/null 2>&1 &get _analyze{ "analyzer":"icu_analyzer", "text":"你好,我是咔咔"}
其它中文分词
用的最多的IK分词,只是自定义词库,支持热更新分词字典
清华大学自然语言一套分词器Thulac
六、Search Api通过Url query 实现搜索例如:
get /movies/_search?q=2012&df=title&sort=year:desc
q:指定查询语句,使用Query String Syntax
df:查询字段,不指定时,会对所有字段进行查询
sort:排序、from和size用于分页
Profile:可以查看查询是如果被执行的
指定字段查询、泛查询指定字段查询就是加上df即可、泛查询什么都不加,看案例
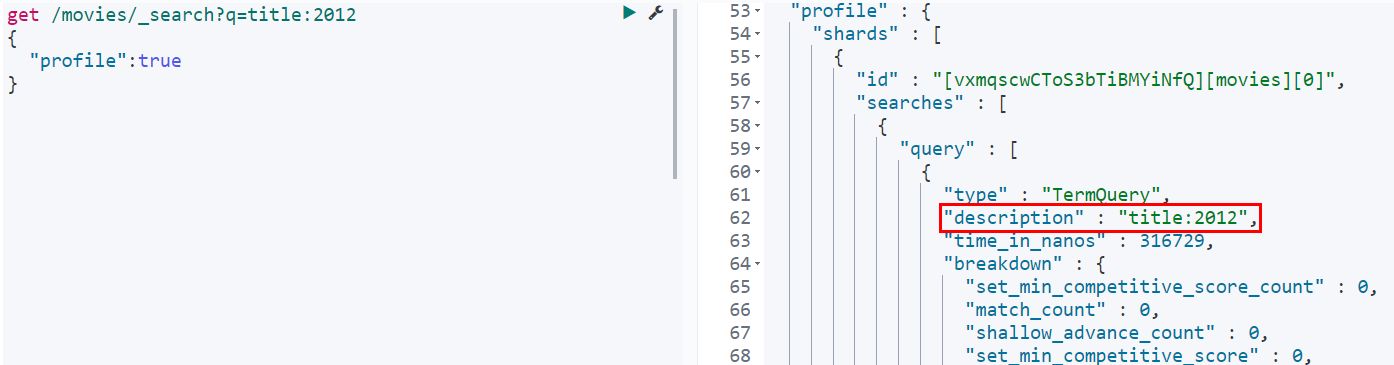
同样也可以这样来写指定字段查询
get /movies/_search?q=2012&df=title{ "profile":true}
通过下图右侧可得知,泛查询则是在所有字段中查找存在2012的数

若你查询值为Beautiful Mind 则等效于Beautiful OR Mind ,类似于MySQL中的or语句,意思为查询的字段中包含 Beautiful 或者 Mind 都会被查询出来
若你查询值为"Beautiful Mind" 则等效于Beautiful AND Mind ,类似于MySQL中的and语句,意思为查询的字段中不仅要包含Beautiful 而且还需要包含 Mind ,跟MySQL中不同的是顺序也不能变
注意:这里你乍一眼看过去没啥区别, 其实区别就在于有无引号
# PhraseQuery# 需要字段title中存在beautiful 和 mind,并且两者的顺序不能乱# "description" : """title:"beautiful mind""""get /movies/_search?q=title:"Beautiful Mind"{ "profile":"true"}# TermQuery# 需要字段title中出现beautiful 或 mind 都可以# "type" : "BooleanQuery",# "description" : "title:beautiful title:mind",get /movies/_search?q=title:(Beautiful Mind){ "profile":"true"}
布尔操作可以使用AND / OR / NOT 或者 && / || / ! 这里你会发现使用的都是大写,+表示must(必须存在),-表示not mast(必须不存在)接下来看案例
# title 里边必须有beautiful 和 mind# "description" : "+title:beautiful +title:mind"get /movies/_search?q=title:(Beautiful AND Mind){ "profile":"true"}# title里边包含beautiful 必须没有mind# "description" : "title:beautiful -title:mind"get /movies/_search?q=title:(Beautiful NOT Mind){ "profile":"true"}# title里包含beautiful ,必须也包含mind# "description" : "title:beautiful +title:mind"get /movies/_search?q=title:(Beautiful %2BMind){ "profile":"true"}
范围查询、通配符查询、模糊匹配# year年份大于1996的电影# 注意一下[] 为闭区间 {}为开区间# "description" : "year:[1997 TO 9223372036854775807]"get /movies/_search?q=year:>1996{ "profile":"true"}# title 中存在b的数据# "description" : "title:b*"get /movies/_search?q=title:b*{ "profile":"true"}# 对于模糊匹配还是非常有必要的,因为会存在一起用户会输错单词,我们就可以给做近似度匹配# "description" : "(title:beautiful)^0.875"get /movies/_search?q=title:beautifl~1{ "profile":"true"}
七、Request Body Search在日常开发过程中,最经常用的还是在Request Body中做,接下来跟着咔咔的实例一点点走
正常查询sort :需要排序的字段
source:查那些字段
from:页数
size:每页数量
post movies/_search{ "profile":"true", "sort":[{"year":"desc"}], "_source":["year"], "from":0, "size":2, "query":{ "match_all": {} }}
脚本字段这个应用场景跟咔咔近期做的外币功能是非吻合,每笔合同都有自己不同的汇率,要算出这笔合同金额是多少
post /movies/_search{ "script_fields":{ "new_field":{ "script":{ "lang":"painless", "source":"doc['year'].value+'年'" } } }, "query":{ "match_all": {} }}
这个案例就是把当前数据的year 拼上 “年” 组成的新字段然后返回,返回结果如下
{ "_index" : "movies", "_type" : "_doc", "_id" : "3844", "_score" : 1.0, "fields" : { "new_field" : [ "1989年" ] } }
从上面的结果可以看到只返回了脚本字段,没有返回原始字段,那如何让原始字段也跟着一起返回呢?
只需要在request body中加上_source即可,当然也可以查询指定字段"_source":["id","title"]
post /movies/_search{ "_source":"*", "script_fields":{ "new_field":{ "script":{ "lang":"painless", "source":"doc['year'].value+'年'" } } }, "query":{ "match_all": {} }}
查看返回结果
{ "_index" : "movies", "_type" : "_doc", "_id" : "3843", "_score" : 1.0, "_source" : { "year" : 1983, "@version" : "1", "genre" : [ "Horror" ], "id" : "3843", "title" : "Sleepaway Camp" }, "fields" : { "new_field" : [ "1983年" ] } }
查询表达式Match# title中包含sleepaway 或者 camp 即可# 可以看到跟 url 的get /movies/_search?q=title:(Beautiful Mind) 分组查询返回结果是一致的# "description" : "title:sleepaway title:camp"get /movies/_doc/_search{ "query":{ "match":{ "title":"Sleepaway Camp" } }, "profile":"true"}# title中必须包含sleepaway 和 camp 并且顺序不能乱# 可以看到跟 url 的get /movies/_search?q=title:(Beautiful AND Mind)是一致的# "description" : "+title:sleepaway +title:camp"get /movies/_doc/_search{ "query":{ "match":{ "title":{ "query":"Sleepaway Camp", "operator":"AND" } } }, "profile":"true"}# title 中查询Sleepaway 和 Camp中间可以有一个任意值插入# get /movies/_search?q=title:beautifl~1# "description" : """title:"sleepaway camp"~1"""get /movies/_doc/_search{ "query":{ "match_phrase":{ "title":{ "query":"Sleepaway Camp", "slop":1 } } }, "profile":"true"}
八、 Query String 和 Simple Query String# Query String 中可以使用and跟url 的query string一样# title 中必须存在sleepaway 和 camp 即可# 跟url的 get /movies/_search?q=title:(Beautiful Mind) 一致# "description" : "+title:sleepaway +title:camp"post /movies/_search{ "query":{ "query_string":{ "default_field":"title", "query":"Sleepaway AND Camp" } }, "profile":"true"}# simple_query_string 不支持and的使用,可以看到是把and当做一个词来进行查询# title 中存在sleepaway 或 camp 即可# "description" : "title:sleepaway title:and title:camp"post /movies/_search{ "query":{ "simple_query_string": { "query": "Sleepaway AND Camp", "fields": ["title"] } }, "profile":"true"}# 如果想让simple_query_string 执行布尔操作,则需要给加上default_operator# title中必须存在sleepaway 和 camp 即可# "description" : "+title:sleepaway +title:camp"post /movies/_search{ "query":{ "simple_query_string": { "query": "Sleepaway Camp", "fields": ["title"], "default_operator": "AND" } }, "profile":"true"}
九、Mapping和常见字段类型什么是MappingMapping类似于数据库中的schema,主要包括定义索引的字段名称,定义字段的数据类型,配置倒排索引设置
什么是Dynamic MappingMapping有一个属性为dynamic,其定义了如何处理新增文档中包含的新增字段,其有三个值可选默认为true
true:一旦有新增字段的文档写入,Mapping也同时被更新
false:Mapping不会被更新并且新增的字段也不会被索引,但是信息会出现在_source中
strict:文档写入失败
常见类型Json类型ElasticSearch类型字符串日期格式为data、浮点数为float、整数为long、设置为text并且增加keyword子字段布尔值boolean浮点数float整数long对象object数组取第一个非空数值的类型所定控制忽略put kaka/_doc/1{ "text":"kaka", "int":10, "boole_text":"false", "boole":true, "float_text":"1.234", "float":1.234, "loginData":"2005-11-24T22:20"}# 获取索引kaka的mappingget kaka/_mapping
返回结果,从结果中可得知如果是false或者true在引号里边就是text类型需要注意这一点就行
自定义Mapping设置字段不被索引
设置字段不被索引使用index,只需要给字段在加一个index:false即可,同时注意一下mapping的设置格式
按照咔咔给的步骤走,你会得到一个这样的错误Cannot search on field [mobile] since it is not indexed,意思就是不能搜索没有索引的字段
put kaka{ "mappings":{ "properties":{ "firstName":{ "type":"text" }, "lastName":{ "type":"text" }, "mobile":{ "type":"text", "index":false } } }}post /kaka/_doc/1{ "firstName":"kaka", "lastName":"Niu", "mobile":"123456"}get /kaka/_search{ "query":{ "match": { "mobile":"123456" } }}
设置copy_to
设置方式如下,copy_to设置后再搜索时可以直接使用你定义的字段进行搜索
put kaka{ "mappings":{ "properties":{ "firstName":{ "type":"text", "copy_to":"allSearch" }, "lastName":{ "type":"text", "copy_to":"allSearch" } } }}
为了方便查看,这里咔咔再插入两条数据
post /kaka/_doc/1{ "fitstName":"kaka", "lastName":"niuniu"}post /kaka/_doc/2{ "fitstName":"kaka", "lastName":"kaka niuniu"}
进行查询,返回的只有id为2的这条数据,所以说使用copy_to后,代表着所有字段中都包含搜索的词
post /kaka/_search{ "query":{ "match":{ "allSearch":"kaka" } }, "profile":"true"}
十、自定义分词器分词器是由Character Fiters、Tokenizer、Token Filter组成的
Character Filters 主要是对文本的替换、增加、删除,可以配置多个Character Filters ,需要注意的是设置后会影响Tokenizer的position、offset信息
Character Filters 自带的有 HTMl strip 去除html标签、Mapping 字符串的替换、Pattern replace 正则匹配替换
Tokenizer 处理的就是分词,内置了非常多的分词详细可以在第二期文章中查看
Token Filters 是将Tokenizer 分词后的单词进行增加、修改、删除,例如进行转为lowercase小写字母、stop去除修饰词、synonym近义词等
自定义Character Filters# Character Fiters之html的替换# 会把text中的html标签都会去除掉post /_analyze{ "tokenizer":"keyword", "char_filter":["html_strip"], "text":"<span>咔咔闲谈</span>"}# Character Fiters之替换值# 会把text中的 i 替换为 kaka、hope 替换为 wishpost /_analyze{ "tokenizer":"keyword", "char_filter":[ { "type":"mapping", "mappings":["i => kaka","hope => wish"] } ], "text":"I hope,if you don't expect quick success, you'll get a pawn every day."}# Character Fiters之正则表达式# 使用正则表达式来获取域名信息post /_analyze{ "tokenizer":"keyword", "char_filter":[ { "type":"pattern_replace", "pattern":"http://(.*)", "replacement":"$1" } ], "text":"http://www.kakaxiantan.com"}
自定义Token Filters现在用的分词器是whitespace,这个分词器是把词使用空格 隔开,但是现在还想让词变小写并过滤修饰词,应该怎么做呢?
post /_analyze{ "tokenizer":"whitespace", "filter":["stop","lowercase"], "text":"If on you don't expect quick success, you'll get a pawn every day"}
为了不占地方,只复制出了代表性的返回结果
{ "tokens" : [ { "token" : "if", "start_offset" : 0, "end_offset" : 2, "type" : "word", "position" : 0 }, { "token" : "you", "start_offset" : 6, "end_offset" : 9, "type" : "word", "position" : 2 } ]}
实战自定义分词本节开篇就知道analyze是通过Character Fiters、Tokenizer、Token Filter组成的,那么在自定义时这三个都是可以自定义的
自定义分词必存在analyzer、tokenizer、char_filter、filter
这部分的定义都是需要在下面定义好规则,否则无法使用,详细定义代码往下拉看完整版本即可
对这个配置不要死记硬背使用的多了自然就会记住

# 实战自定义analyzeput kaka{ "settings":{ "analysis":{ "analyzer":{ "my_custom_analyzer":{ "type":"custom", "char_filter":[ "emoticons" ], "tokenizer":"punctuation", "filter":[ "lowercase", "englist_stop" ] } }, "tokenizer":{ "punctuation":{ "type":"keyword" } }, "char_filter":{ "emoticons":{ "type":"mapping", "mappings":[ "123 => Kaka", "456 => xian tan" ] } }, "filter":{ "englist_stop":{ "type":"stop", "stopwords":"_english_" } } } }}# 执行自定义的分词post /kaka/_analyze{ "analyzer":"my_custom_analyzer", "text":" 123 456"}# 返回结果,把字母大写转为小写不做分词{ "tokens" : [ { "token" : " kaka xian tan", "start_offset" : 0, "end_offset" : 8, "type" : "word", "position" : 0 } ]}
十一、Index Template在一个新索引新建并插入文档后,会使用默认的setting、mapping,如果你有设定settings、mappings会覆盖默认的settings、mappings配置
# 创建索引并插入文档post /kaka/_doc/1{ "gongzhonghao":"123"}# 获取settings、mappingsget /kaka
以下这个配置,就是默认配置
# 返回的settings、mappings{ "kaka" : { "aliases" : { }, "mappings" : { "properties" : { "gongzhonghao" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } }, "settings" : { "index" : { "creation_date" : "1642080577305", "number_of_shards" : "1", "number_of_replicas" : "1", "uuid" : "JJWsGYcrTam0foEQxuZqGQ", "version" : { "created" : "7010099" }, "provided_name" : "kaka" } } }}
接下来创建一个自己的模板
# 设置一个只要是test开头的索引都能使用的模板,在这个模板中我们将字符串中得数字也转为了long类型,而非textput /_template/kaka_tmp{ "index_patterns":["test*"], "order":1, "settings":{ "number_of_shards":1, "number_of_replicas":2 }, "mappings":{ # 让时间不解析为date类型,返回是text类型 "date_detection":false, # 让双引号下的数字解析为long类型,而非text类型 "numeric_detection":true }}
创建索引
post /test_kaka/_doc/1{ "name":"123", "date":"2022/01/13"}get /test_kaka
返回结果
{ "test_kaka" : { "aliases" : { }, "mappings" : { "date_detection" : false, "numeric_detection" : true, "properties" : { "date" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "name" : { "type" : "long" } } }, "settings" : { "index" : { "creation_date" : "1642081053006", "number_of_shards" : "1", "number_of_replicas" : "2", "uuid" : "iCcaa_8-TXuymhfzQi31yA", "version" : { "created" : "7010099" }, "provided_name" : "test_kaka" } } }}
坚持学习、坚持写作、坚持分享是咔咔从业以来所秉持的信念。愿文章在偌大的互联网上能给你带来一点帮助,我是咔咔,下期见。
