编辑:桃子 好困
【新智元导读】Meta首个理解图文的多模态Llama 3.2来了!这次,除了11B和90B两个基础版本,Meta还推出了仅有1B和3B轻量级版本,适配了Arm处理器,手机、AR眼镜边缘设备皆可用。
Llama 3.1超大杯405B刚过去两个月,全新升级后的Llama 3.2来了!
这次,最大的亮点在于,Llama 3.2成为羊驼家族中,首个支持多模态能力的模型。
Connect大会上,新出炉的Llama 3.2包含了小型(11B)和中型(90B)两种版本的主要视觉模型。
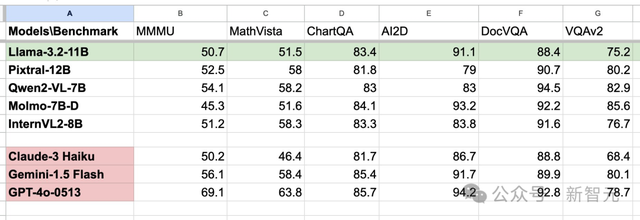
正如Meta所说,这两款模型能够直接替代,相对应的文本模型,而且在图像理解任务上击败了闭源Claude 3 Haiku。
甚至,90B版本击败了GPT-4o mini。

就连英伟达高级科学家Jim Fan都不禁夸赞,在轻量级模型中,开源社区整体上并不落后!

同时,为了适配边缘计算和终端设备,Meta还推出了1B和3B两个轻量级纯文本的版本,可支持128K上下文。

别看参数少,1B/3B在总结摘要、指令遵循、重写等任务上,表现非常出色,而且专为Arm处理器做了优化。
LeCun激动地表示,「可爱的大羊驼宝宝来了」!
Meta首席技术官对Llama 3.2的发布,做了两大亮点总结:
首个既能识别图像,又能理解文本的多模态模型。最重要的是,能够媲美闭源模型超轻量1B/3B模型,解锁更多终端设备可能性
有网友对此点评道,这可能是改变游戏规则的进步,边缘设备AI正在壮大。
能力一览
11B和90B这两款模型,不仅支持图像推理场景,包括图表和图形在内的文档级理解、图像描述以及视觉定位任务,而且还能基于现有图表进行推理并快速给出回答。
比如,你可以问「去年哪个月销售业绩最好?」,Llama 3.2就会根据现有图表进行推理,并迅速给出答案。
轻量级的1B和3B模型则可以帮助不仅在多语言文本生成和工具调用能力方面表现出色,而且具有强大的隐私保护,数据永远不会离开设备。
之所以在本地运行模型备受大家的青睐,主要在于以下两个主要优势:
提示词和响应能够给人瞬间完成的感觉应用程序可以清晰地控制哪些查询留在设备上,哪些可能需要由云端的更大模型处理
性能评估
结果显示,Llama 3.2视觉模型在图像识别等任务上,与Claude 3 Haiku和GPT-4o mini不相上下。
3B模型在遵循指令、总结、提示词重写和工具使用等任务上,表现优于Gemma 2 2B和Phi 3.5 mini;而1B模型则与Gemma旗鼓相当。


视觉模型
作为首批支持视觉任务的Llama模型,Meta为11B和90B型打造了一个全新的模型架构。
在图像输入方面,训练了一组适配器权重,将预训练的图像编码器集成到预训练的大语言模型中。
具体来说,该适配器:
由一系列交叉注意力层组成,负责将图像编码器的表示输入进大语言模型通过在文本-图像对上的训练,实现图像表示与语言表征的对齐在适配器训练期间,Meta会对图像编码器的参数进行更新,但不会更新大语言模型参数。
也就是说,模型的纯文本能力便不会受到任何影响,而开发者也可以将之前部署的Llama 3.1无缝替换成Llama 3.2。

具体的训练流程如下:
首先,为预训练的Llama 3.1文本模型添加图像适配器和编码器,并在大规模噪声图像-文本对数据上进行预训练。
然后,在中等规模的高质量领域内和知识增强的图像-文本对数据上,再次进行训练。
接着,在后训练阶段采用与文本模型类似的方法,通过监督微调、拒绝采样和直接偏好优化进行多轮对齐。并加入安全缓解数据,保障模型的输出既安全又实用。
这在期间,模型所使用的高质量微调数据,正是来自合成数据生成技术——使用Llama 3.1模型在领域内图像的基础上过滤和增强问题答案,并使用奖励模型对所有候选答案进行排序。
最终,我们就能得到一系列可以同时接受图像和文本提示词的模型,并能够深入理解和对其组合进行推理。
对此,Meta自豪地表示表示:「这是Llama模型向更丰富的AI智能体能力迈进的又一步」。
得到全新Llama 3.2加持的助手Meta AI,在视觉理解力上非常强。
比如,上传一张切开的生日蛋糕图片,并问它制作配方。
Meta AI便会给出手把手教程,从配料到加工方式,一应俱全。

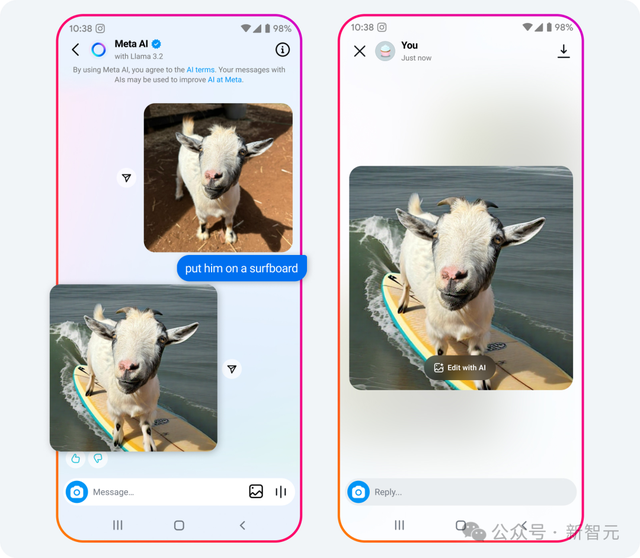
又或者你发给它一张小羊的照片,并要求将其放在冲浪板上。
不一会儿功夫,一只站在冲浪板上的山羊图画好了。
轻量模型
通过利用剪枝(pruning)和蒸馏(distillation)这两种方法,Meta让全新的1B和3B模型,成为了首批能够高效地适应设备的、具有高能力的轻量级Llama模型。
剪枝能够减小Llama的规模,并尽可能地保留知识和性能在此,Meta采用了从Llama 3.1 80亿参数模型进行单次结构化剪枝的方法。也就是,系统地移除网络的部分内容,并调整权重和梯度的幅度,从而创建一个更小、更高效的大语言模型,同时保留原始网络的性能。
完成剪枝之后,则需要使用知识蒸馏来恢复模型的性能。
知识蒸馏是让一个更大的网络给更小的网络传授知识也就是,较小的模型可以借助教师模型的指导,获得比从头开始训练更好的性能。为此,Meta在预训练阶段融入了来自Llama 3.1 8B和70B模型的logits(模型输出的原始预测值),并将这些较大模型的输出则用作token级的目标。

后训练阶段,Meta采用了与Llama 3.1类似的方法——通过在预训练大语言模型基础上进行多轮对齐来生成最终的聊天模型。
其中,每一轮都包括监督微调(SFT,Supervised Fine-Tuning)、拒绝采样(RS,Rejection Sampling)和直接偏好优化(DPO,Direct Preference Optimization)。
在这期间,Meta不仅将模型的上下文长度扩展到了128K token,而且还利用经过仔细筛选的合成数据和高质量的混合数据,对诸如总结、重写、指令跟随、语言推理和工具使用等多项能力进行了优化。
为了便于开源社区更好地基于Llama进行创新,Meta还与高通(Qualcomm)、联发科(Mediatek)和Arm展开了密切合作。
值得一提的是,Meta这次发布的权重为BFloat16格式。


Llama Stack发行版
Llama Stack API是一个标准化接口,用于规范工具链组件(如微调、合成数据生成等)以定制Llama大语言模型并构建AI智能体应用。
自从今年7月Meta提出了相关的意见征求之后,社区反响非常热烈。
如今,Meta正式推出Llama Stack发行版——可将多个能够良好协同工作的API提供者打包在一起,为开发者提供单一接入点。
这种简化且一致的使用体验,让开发者能够在多种环境中使用Llama大语言模型,包括本地环境、云端、单节点服务器和终端设备。

完整的发布内容包括:
Llama CLI:用于构建、配置和运行Llama Stack发行版多种语言的客户端代码:包括Python、Node.js、Kotlin和SwiftDocker容器:用于Llama Stack发行版服务器和AI智能体API供应商多种发行版:单节点Llama Stack发行版:通过Meta内部实现和Ollama提供云端Llama Stack发行版:通过AWS、Databricks、Fireworks和Together提供设备端Llama Stack发行版:通过PyTorch ExecuTorch在iOS上实现本地部署Llama Stack发行版:由Dell提供支持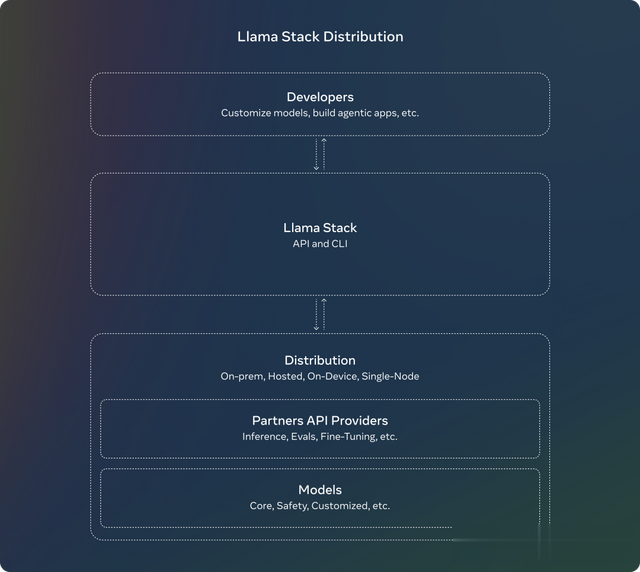
系统安全
这次,Meta在模型安全方面主要进行了两个更新:
1.Llama Guard 3 11B Vision
它支持Llama 3.2的全新图像理解能力,并能过滤文本+图像输入提示词或对这些提示词的文本输出响应。
2. Llama Guard 3 1B
它基于Llama 3.2 1B,并在剪枝和量化处理之后,将模型大小从2,858MB缩减至438MB,使部署效率达到前所未有的高度。

目前,这些新解决方案已经集成到了Meta的参考实现、演示和应用程序中,开源社区可以立即开始使用。

哇哦 nice[点赞] 刚看完v0
小扎奶爸的开源大模型,你们感觉怎么样?
比起open ai,呵呵,close ai,股份ai,把元老排挤开,自己单独吃,然后转手一卖?这是啥共享单车?
开不开源是自己公司发展理念坚定的。有的坚持闭源。有的坚持开源。是非常正常的事。