
作者:李宝珠,xixi 编辑:李宝珠 HyperAI官网 (hyper.ai) 现已上线「FLUX ComfyUI」,一键部署,速来体验!
长久以来,从艺术风格多样化的 Midjourney,到背靠 OpenAI 的 DALL-E,再到开源的 Stable Diffusion(简称 SD),文生图模型的生成质量与速度都在持续升级,prompt 理解与细节处理也成为了各大模型内卷的新方向。
进入 2024 年后,处于「双雄鼎立」阶段的 Midjourney 与 Stable Diffusion 接连发力,SD 3 率先发布,随后 Midjourney V6.1 也更新迭代。然而,当人们还沉浸在 SD 3 与 Midjourney 的对比时,新一代「魔王」悄然降生——FLUX 横空出世。
FLUX 在生成人物、尤其是真实人物的场景时,效果已经非常接近真人实拍了,人物表情、皮肤光泽、发型发色等细节都十分逼真。其也一度被誉为 Stable Diffusion 的继承者,有意思的是,二者确实颇具渊源。
FLUX 背后团队 Black Forest Labs 的创始人 Robin Rombach,正是 Stable Diffusion 的共同开发者之一 。Robin 在离开 Stability AI 后成立了 Black Forest Labs,并推出了 FLUX.1 模型。
目前,FLUX.1 提供了 3 个版本:Pro、Dev 和 Schnell。Pro 版是通过 API 提供的闭源版本,可用于商业,也是最强大的版本;Dev 版是直接从 Pro 版本「蒸馏」而来的开源版本,具有非商业许可;Schnell 版是速度最快的精简版本,据称运行速度最高可提高 10 倍,开放源代码,采用 Apache 2 许可,适用于本地开发和个人使用。
相信不少小伙伴都想实际上手体验一下这个新一代文生图顶流!HyperAI超神级官网 (hyper.ai) 的教程版块现已上线「FLUX ComfyUI(含黑神话悟空 LoRA 训练版)」,是 ComfyUI 版 FLUX[dev],还支持 LoRA 训练。
感兴趣的小伙伴速来体验吧!小编已经替大家试过了,效果完全不输 SD 3 与 Midjourney ↓

相同 prompt,分别由 3 个模型生成的效果 * prompt:a girl is holding a sign that says 「I am an AI」
此外,B 站热门 Up 主 Jack-Cui 也制作了详细的操作教程,手把手教会大家!
教程地址:
https://go.hyper.ai/trQhv
操作视频:
https://www.bilibili.com/video/BV1xSpKeVEeM
Demo 运行
FLUX ComfyUI 运行
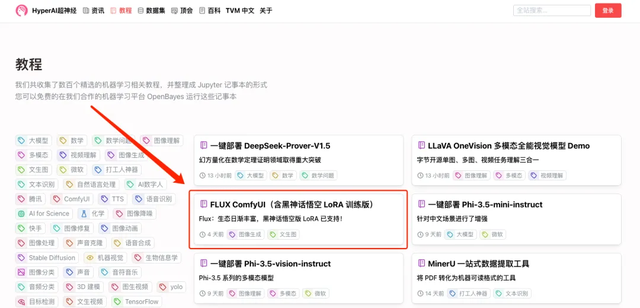
1. 登录 hyper.ai,在「教程」页面,点击「在线运行此教程」。「FLUX ComfyUI(含黑神话悟空 LoRA 训练版)」,点击「在线运行此教程」。
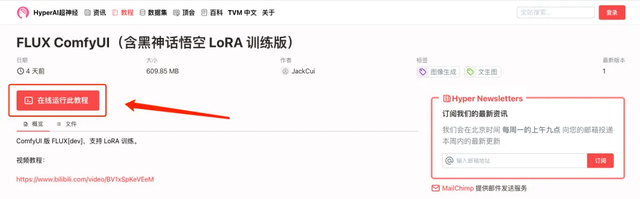
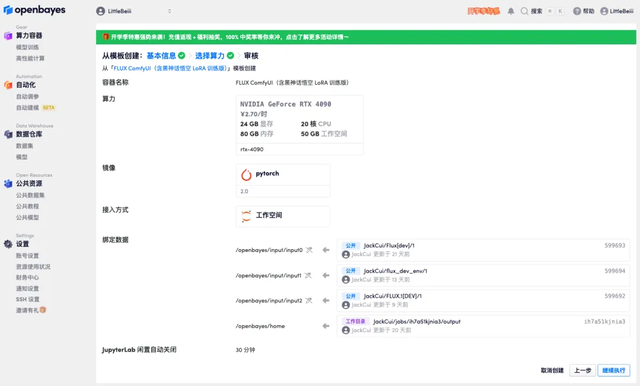
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
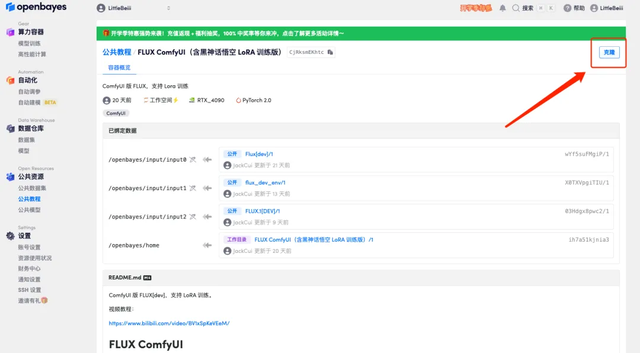
3. 点击右下角「下一步:选择算力」。

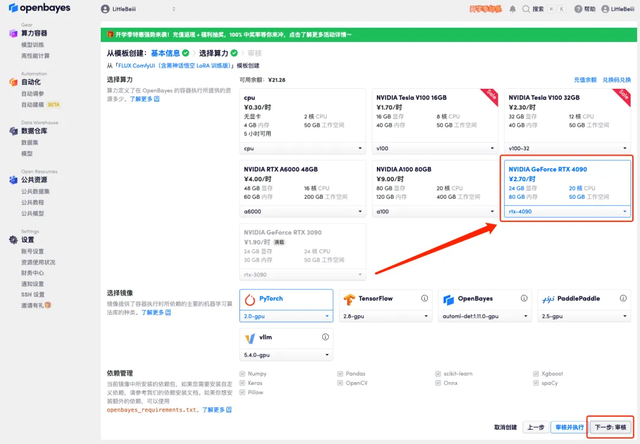
4. 页面跳转后,选择「NVIDIA RTX 4090」以及 「PyTorch」镜像,点击「下一步:审核」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
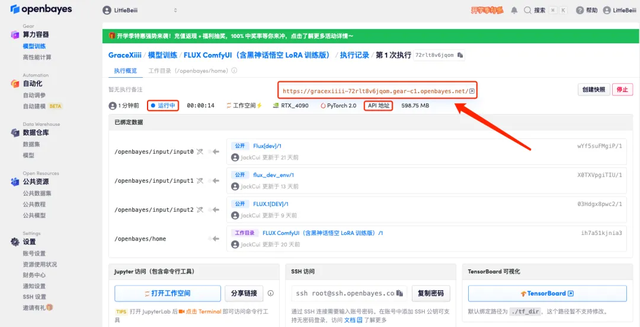
5. 确认无误后,点击「继续执行」,等待分配资源,首次克隆需等待 1-2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」边上的跳转箭头,即可跳转至 Demo 页面。请注意,用户需在实名认证后才能使用 API 地址访问功能。

6. 打开 Demo 后,点击「Switch Locale」将语言切换为中文。
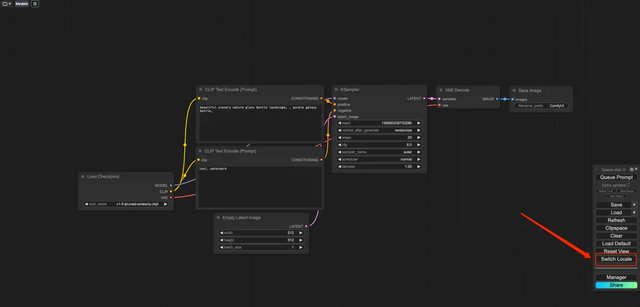
7. 切换语言后,点击左上角的文件夹图标选择所需工作流。
* wukong:黑神话悟空形象 Demo
* TED:TED 真人演讲 demo
* 3mm4w:图片上写文本 demo

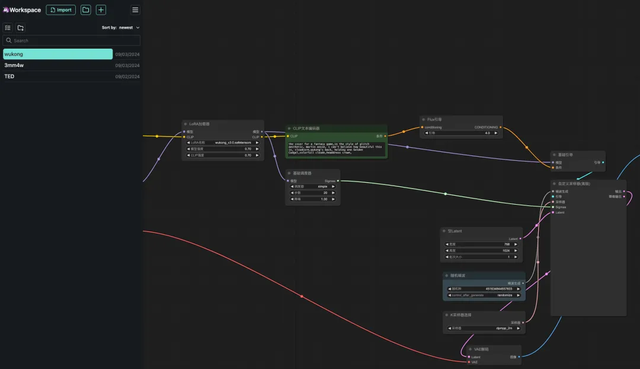
8. 选择「wukong」工作流,在 CLIP 文本生成器中输入 Prompt (例如:the back of wukong, holding one golden cudgel,colorfull clouds,headdress crown),点击「添加提示词队列就可以生成图片」,可以看到生成图片十分精美。


FLUX LoRA 训练
1. 想要定制工作流,我们需要先训练 LoRA 模型,回到刚刚的容器界面,点击「打开工作空间」,新建一个终端。


2. 在终端输入「sh train.sh」,敲回车运行,待「Running on public URL」出现后,点击该链接。

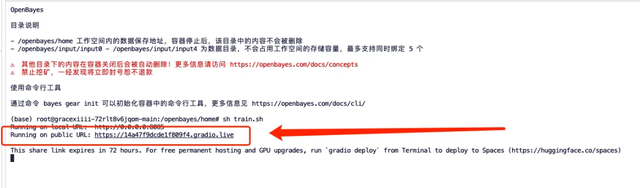
3. 页面跳转后,输入模型的模型,并上传图片,这里上传 5 张霉霉的照片,请注意,图像需要是高分辨率正脸照片,人脸的比例大一些。图像的质量越好训练出来的效果越好,
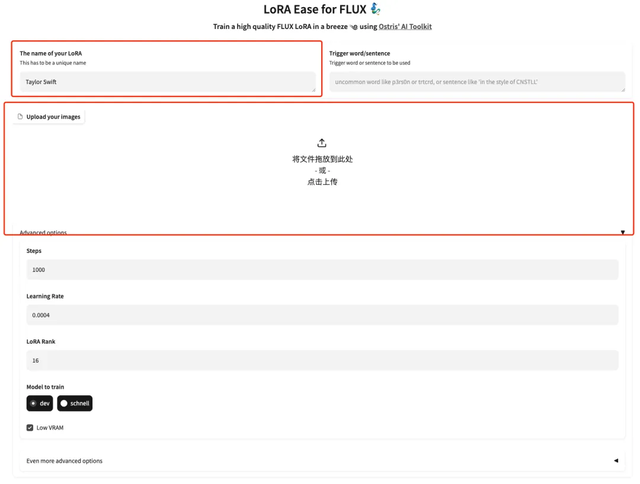
4. 上传成功后,在每一个图像的后面手动添加英文文本描述,也可以点击「Add AI captions with Florence-2」自动生成文本描述。


5. 下拉至页面底部,输入一个 Test prompt(例如:A person is drinking coffee)后,点击「Start training」。

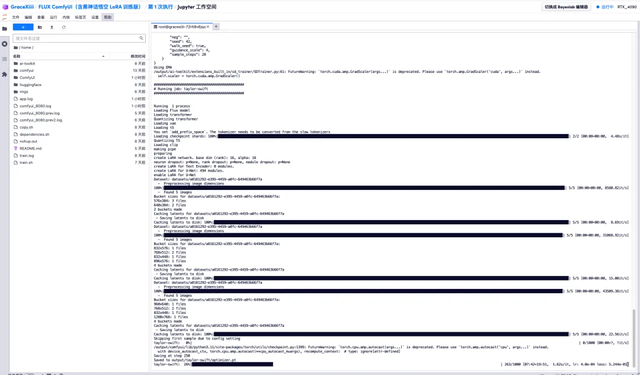
6. 等待几分钟后,我们回到刚刚的终端界面,可以看到训练的进度条,大概 40 分钟即可训练完成。待「Saved to output/taylor-swift/optimizer.pt」出现,表示训练已完成。

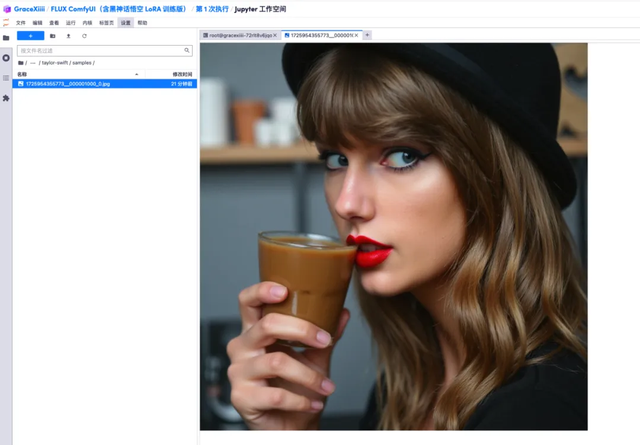
7. 在左侧「ai-toolkit」-「output」-「taylor swift」-「sample」文件里,可以看到我们刚刚 Test Prompt 的效果,如果效果还不错,就证明我们的模型已经训练成功了。

8. 模型训练好后,我们需要关掉训练服务,释放 GPU 资源,回到刚刚的重点界面,按「Ctrl+C」终止训练。
9. 运行「sh copy.sh」,再运行「sh dependencies.sh」启动 ComfyUI,等待 2 分钟后,打开右侧 API 地址。

10. 页面跳转后,在「LoRA 加载器」中选择刚刚训练好的模型,在「CLIP」中输入 Prompt(例如:a person is drinking coffee),点击「添加提示词队列」即可生成图像。



