Ars Technica——Sasha Luccioni博士是hug Face的研究员和气候负责人,在那里她研究人工智能模型和数据集的伦理和社会影响。她还是机器学习女性(WiML)的董事,气候变化AI (CCAI)的创始成员,以及NeurIPS道德准则委员会主席。
本文中的观点并不一定反映Ars Technica的观点。
产业前沿编译
过去几个月,人工智能领域发展迅速,Dall-E、GPT-4等一波又一波新模型层出不穷。每周都有新的令人兴奋的模型、产品和工具。人们很容易被大肆宣传的浪潮所淹没,但这些闪亮的功能却给社会和地球带来了实实在在的代价。
缺点包括开采稀有矿物的环境代价,数据注释的劳动密集型过程的人力成本,以及训练人工智能模型所需的不断升级的财务投资,因为它们包含了更多的参数。
让我们来看看推动最近几代这些模型的创新——以及提高其相关成本的创新。
更大的模型
近年来,人工智能模型越来越大,研究人员现在用数千亿个参数来衡量它们的大小。“参数”是模型中用于学习基于训练数据的模式的内部连接。
对于像ChatGPT这样的大型语言模型,通过谷歌的PaLM模型,我们已经从2018年的大约1亿个参数增加到2023年的5000亿个参数。这种增长背后的理论是,拥有更多参数的模型应该有更好的表现,即使是在最初没有训练过的任务上,尽管这一假设仍未得到证实。

多年来增长规模
更大的模型通常需要更长的时间来训练,这意味着它们也需要更多的GPU,这需要更多的钱,所以只有少数几个组织能够训练它们。据估计,GPT-3的训练成本为460万美元,这是大多数公司和组织无法承受的。GPT-3有1750亿个参数。(值得注意的是,在某些情况下,训练模型的成本正在下降,比如最近由Meta训练的模型LLaMA。)
这在人工智能社区中造成了数字鸿沟,在那些能够培训最先进的LLMs(主要是全球北方的大型科技公司和富有的机构)和那些不能(非营利组织,初创公司,以及任何无法获得超级计算机或数百万云积分的人)的人之间。构建和部署这些庞然大物需要大量的地球资源:制造GPU的稀有金属,冷却大型数据中心的水,保持这些数据中心在全球范围内全天候运行的能源……所有这些都经常被忽视,而人们更倾向于关注最终模型的未来潜力。
频次的影响
卡内基梅隆大学(Carnegie Melon University)教授艾玛·斯特鲁贝尔(Emma Strubell)在一项关于训练llm的碳足迹的研究中估计,训练一个名为BERT的2019年模型,该模型只有2.13亿个参数,排放280公吨碳排放,大致相当于五辆汽车一生中的排放量。从那时起,模型不断发展,硬件变得更加高效,那么我们现在在哪里呢?
在我最近写的一篇学术文章中,我研究了训练BLOOM(一个1760亿参数的语言模型)所产生的碳排放,我们比较了几个LLM的功耗和随之而来的碳排放,这些都是在过去几年里出现的。比较的目的是了解不同规模llm的排放规模及其影响。

根据用于培训的能源及其碳强度,如果使用可再生能源,培训2022时代的LLM至少会排放25公吨碳当量,就像我们对BLOOM模型所做的那样。如果你使用煤炭和天然气等碳密集型能源,就像GPT-3的情况一样,这个数字很快就会上升到500公吨碳排放,大致相当于一辆普通汽油动力汽车行驶100多万英里。
而且这个计算没有考虑用于训练模型的硬件的制造,也没有考虑在现实世界中部署LLM时产生的排放。例如,ChatGPT在一个月前的高峰期受到数千万用户的查询,该模型的数千个副本正在并行运行,实时响应用户的查询,同时使用兆瓦时的电力并产生公吨的碳排放。鉴于这些大型有限责任公司的保密和缺乏透明度,很难估计其造成的确切排放量。
封闭的专有模型
让我们回到上面的LLM大小图。您可能会注意到ChatGPT和GPT-4都不在其中。为什么?因为我们不知道它们有多大。虽然有一些关于它们的报道,但我们对它们的大小和工作原理几乎一无所知。访问是通过api提供的,这意味着它们本质上是用户可以查询的黑盒。
这些盒子可能包含单个模型(有一万亿个参数?)或多个模型,或者,正如我告诉彭博社的那样,“它可能是三只穿着风衣的浣熊。”我们真的不知道。
下面的图表展示了LLM最近发布的时间轴,以及每个模型创建者提供的访问类型。如你所见,最大的模型(如Megatron、PaLM、Gopher等)都是闭源的。如果你相信模型越大,它就越强大的理论(我不这么认为),这意味着最强大的人工智能技术只能被少数几个组织使用,这些组织垄断了它的使用权。

最近发布的LLM的时间表以及每个模型创建者提供的访问类型。
为什么这是有问题的?这意味着很难对这些模型进行外部评估和审计,因为您甚至不能确保每次查询时底层模型都是相同的。这也意味着你不能对它们进行科学研究,因为研究必须是可重复的。
唯一能够不断改进这些模型的人是最初培训这些模型的组织,随着时间的推移,他们会不断改进模型并提供新功能。
人力成本
训练一个人工智能模型需要多少人?你可能认为答案是零,但制造最近几代LLM所需的人力数量正在稳步上升。
几年前,当变形金刚模型问世时,研究人员将其誉为人工智能的新时代,因为它们可以用“原始数据”进行训练。在这种情况下,原始数据意味着“未标记的数据”——书籍、百科全书文章和被大量抓取和收集的网站。
像BERT和GPT-2这样的模型就是如此,在数据收集和过滤方面,它们需要相对较少的人为干预。虽然这对模型创造者来说很方便,但这也意味着在模型训练过程中,各种不受欢迎的内容,如仇恨言论和色情内容,都会被吸收,然后通常会被模型自己重复。
这种数据收集方法随着RLHF(带有人类反馈的强化学习)的出现而改变,这种技术被ChatGPT等新一代LLM所使用。顾名思义,RLHF为LLM培训过程添加了额外的步骤,这些步骤需要更多的人为干预。
从本质上讲,一旦一个模型接受了大量未标记的数据(来自网络、书籍等)的训练,人类就会被要求与模型交互,提出提示(例如,“给我写一个巧克力蛋糕的食谱”),并提供他们自己的答案或评估模型提供的答案。这些数据被用来继续训练模型,然后再由人类反复测试,直到模型被认为足够好,可以发布到世界上。
正是这种RLHF训练使ChatGPT能够广泛发布,因为它可以拒绝回答许多类型的潜在有害问题。
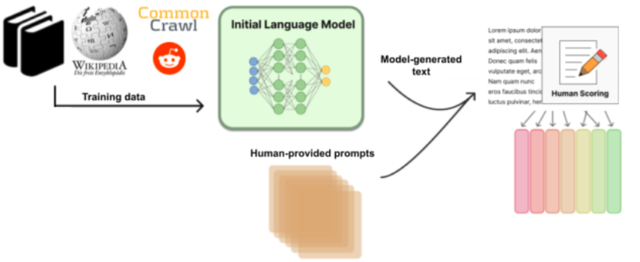
RLHF训练说明。
但这种成功背后有一个肮脏的秘密:为了保持人工智能的低成本,提供这种“人类反馈”的人是工资过低、被过度剥削的工人。今年1月,《时代》杂志(Time)写了一篇报道,报道了肯尼亚工人为OpenAI检查数千条信息,每小时报酬不到2美元。这类工作可能会产生长期的心理影响,就像我们在内容审核工作者身上看到的那样。
更糟糕的是,这些无名工作者的努力在人工智能模型的报告中没有得到认可。他们的劳动仍然是无形的。
我们该怎么办呢?
对于这些模型的创建者来说,与其专注于规模和大小,并仅针对性能进行优化,还可以训练更小、更高效的模型,并使模型可访问,以便AI社区的成员可以重用和微调(阅读:改编),他们不需要从头开始训练模型。致力于提高这些模型的安全性——为机器生成的内容开发水印、更可靠的安全过滤器以及在生成问题答案时引用来源的能力——也有助于使llm更易于访问和更健壮。

生成式AI有许多隐藏成本。
作为这些模型的用户(有时包括我们自己),我们有能力要求透明度,并反对在高风险场景中部署人工智能模型,例如提供心理帮助治疗或生成法医草图的服务。这些模型还太新,记录不足,难以预测,无法在可能产生如此重大影响的情况下部署。
下次有人告诉你,最新的人工智能模型将造福全人类,或者它展示了人工智能的证据,我希望你能思考一下它对人类和地球的隐性成本,其中一些我已经在上面的章节中讨论过了。这些只是这些系统更广泛的社会影响和成本的一小部分(你可以在下面的图片中看到其中一些,通过Twitter众包),比如工作影响,虚假信息和宣传的传播,以及版权侵权问题。
目前的趋势是创建更大、更封闭、更不透明的模型。但我们仍有时间进行反击,要求透明度,并更好地了解LMM的成本和影响,同时限制它们在整个社会中的部署方式。美国的《算法问责法》(Algorithmic Accountability Act)以及欧盟和加拿大的人工智能治理法律框架等立法正在定义我们的人工智能未来,并制定保障措施,以确保未来几代人工智能系统部署在社会中的安全和问责制。作为社会的成员和这些系统的用户,我们应该让它们的创造者听到我们的声音。
Sasha Luccioni博士是hug Face的研究员和气候负责人,在那里她研究人工智能模型和数据集的伦理和社会影响。她还是机器学习女性(WiML)的董事,气候变化AI (CCAI)的创始成员,以及NeurIPS道德准则委员会主席。
