
毫无疑问,随着以ChatGPT为首的一大批生成式人工智能产品相继面世,我们正在经历新的一轮“工业革命”。
然而,生成式人工智能的爆发式增长背后,商业秘密泄露、个人信息泄露、网络安全攻击等问题也引发了各国监管机构的“冷思考”。如英国信息专员办公室在3月15日宣布更新了有关人工智能和信息保护的指南,旨在保障英国用户(含弱势群体)的利益;美国也正在就人工智能系统的潜在问责措施征求公众意见。
我国监管部门对此也采取了相应举措,在4月11日由国家互联网信息办公室发布了《生成式人工智能服务管理办法(征求意见稿)》(下称《管理办法》),明确提出了服务提供者所需承担的责任及义务。
在此背景下,ChatGPT作为一个先进的人工智能语言模型,自然也需要对自身的《隐私政策》1进行审视。
当然,如果直接问它如何看待自身《隐私政策》的法律风险,它会明确告诉你:



显然是问不出来什么内容的。
然而,若将《隐私政策》的核心要点“拆解”为下述10个问题,再一一进行询问后,还是能够从中发现隐藏的数据合规风险:
个人信息处理者——“我们”是谁?
个人信息收集符合“最小必要”原则吗?
个人信息使用合规吗?
个人信息共享合规吗?
个人信息存储及跨境传输合规吗?
个人信息权利如何行使?
儿童个人信息的收集合规吗?
个人信息处理行为的司法管辖权
API接入时,各方的角色分别是什么?
Open AI在数据安全方面的认证资质有哪些?
个人信息处理者:“我们”是谁?

《隐私政策》在开篇及第9部分(“International users”)中明确了自己作为数据控制者的身份及具体的主体信息,与ChatGPT的回答一致。

分析:合规
Open AI已在《隐私政策》中表明“我们”的身份,即Open AI, L.L.C,并未将相关的关联公司等主体一并列上,整体而言,个人信息处理者的角色主体清晰。(其中关于“我们”不清所涉的法律风险,详见《〈个人信息保护法〉实施1.5年,再看平台隐私政策中“我们”是谁?》)。
个人信息收集符合“最小必要”原则吗?

《隐私政策》第2部分(“How we use personal information”)中列出用户个人信息的主要用途,其中特别提到个人信息汇聚融合(Aggregated information)及去标识化(De-identified information)使用,以用于分析服务有效性、提升和增加服务特性、进行研究等目的。
对此,我们询问了ChatGPT收集该等信息是否符合最小必要原则,ChatGPT给出了肯定的答案。
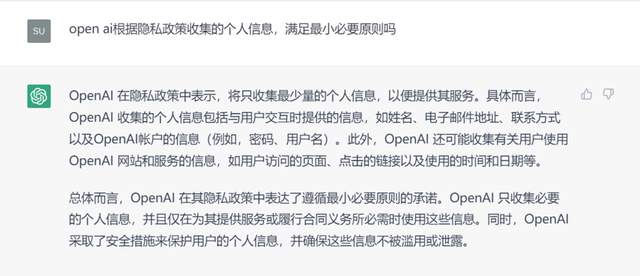
分析:合规性存疑
《隐私政策》中有关个人信息收集与使用是分开表述的,并未将收集与用途进行一一对应,因而无法直观地判断Open AI收集每一类信息是否均满足“最小必要”原则,整体合规性有待进一步论证。
个人信息使用合规吗?

《隐私政策》第2部分(“How we use personal information”)中列出用户个人信息的主要用途,其中特别提到个人信息汇聚融合(Aggregated information)及去标识化(De-identified information)使用,以用于分析服务有效性、提升和增加服务特性、进行研究等目的。
对此,我们针对这两块内容询问了ChatGPT的看法,ChatGPT整体而言还是将其限定是在“最小必要”的框架下进行,对于可能存在的法律风险(如“重识别”风险,具体详见我们撰写的文章《“个人信息”的判定绝非易事——IP属地遇到拦路虎“再识别技术”》)则已采取相应措施。


分析:不合规
《隐私政策》显然并没有就“汇聚融合”的合法正当性进行充分表述,尤其是在该等汇总或去标识化的个人信息还将与第三方进行共享的情形下。即使是“匿名”个人信息也面临着“重识别”的风险,更何谈只是“去标识化”的个人信息。
个人信息共享合规吗?

《隐私政策》第3部分(“Disclosure of personal information”)中明确了个人信息共享的4类情形,包括与第三方服务商共享、商业交易项下的共享、根据法律要求共享及在关联方之间的共享,但在与关联方之间的共享方面,并没有进行明确说明。
对此,ChatGPT认为虽然Open AI没有进行明确说明,但其仍然需要遵守共享相关法律规定,仅在必要情况下进行共享,且仅共享必要的信息。

分析:不合规
《隐私政策》在关联方共享情形的表述不够清晰,用户无法知晓在何种情形下其个人信息将在关联公司之间共享。虽然该等关联公司是受Open AI控制,但毕竟属于独立主体,其个人信息共享行为仍应受到约束。
个人信息存储及跨境传输合规吗?

关于个人信息存储地点、存储期限及跨境传输的约定散落在《隐私政策》第8部分(“Security and Retention”)及第9部分(“International users”)的内容之内,但其中有关存储期限的表述较为笼统。对此ChatGPT表示Open AI所收集的个人信息将存储于美国,可能会涉及跨境传输的情形,届时会依法采取适当的数据转移机制来确保跨境传输安全;同时也承认《隐私政策》在存储期限维度没有进行明确约定。


分析:合规性存疑
《隐私政策》对于个人信息存储期限没有进行明确约定,而是采用了一般性的表述;同时提到对于匿名化或去标识化的个人信息将永久性存储,其存储合规性有待商榷。
个人信息权利如何行使?

《隐私政策》中第4部分(“Your Rights”)和第5部分(“California privacy rights”)以专章形式列明了用户享有的个人信息权利,包括访问、删除、更正或更新、转移个人信息及撤回处理个人信息的同意及反对或限制处理个人信息的同意等权益;同时说明了两种行使路径(账户设置或邮件申请),但表述不够清晰。通过询问ChatGPT,给到的回答也基本是邮件申请路径。下图是以行使访问权为例得到的回复:

分析:不合规
总体而言,《隐私政策》中有关个人数据权利具体行使路径的表述不够清晰,未说明哪些权利可以通过账户设置行使,哪些权利需要通过邮件方式申请;同时反馈时限也没有予以明确。
儿童个人信息的收集合规吗?

《隐私政策》中第6部分(“Children”)明确其并不旨在为13岁以下的儿童提供服务,也不知晓收集了儿童个人信息。对此,ChatGPT也明确回答Open AI不会有意地收集儿童个人信息;当进一步询问Open AI是否应当在事前判断用户是否属于儿童时,ChatGPT也给出了否定的回答。

分析:合规性存疑
根据美国《Children’s Online Privacy Protection Act》(下称《COPPA》)的规定,该法主要规制的对象包括旨在服务儿童的网站或在线服务的经营者(“a website or online service directed to children”),或任何实际了解其正在收集儿童个人信息的经营者(“any operator that has actual knowledge that it is collecting personal information from a child”)。
基于ChatGPT所面向用户的庞大基数,即使其服务并不旨在服务儿童,但是否完全“不实际了解”其正在收集儿童个人信息,是有待进一步论证的。
个人信息处理行为的司法管辖权
作为Open AI用户使用协议(“Term of Use”)的一部分,《隐私政策》受美国加州法律管辖,同时也提及到针对欧洲经济区、英国和瑞士用户,GDPR相关规则也一并适用。但对于除前述国家和地区以外的国际用户个人信息处理的合规性基础,《隐私政策》中并未予以明确。
对此,ChatGPT表示,基于Open AI在全球范围内收集用户的个人信息,其不仅需要遵守美国相关法律规定,还需要遵守其他国家和地区的个人信息保护相关规定。

分析:不合规
正如ChatGPT所回复的,既然Open AI是面向全球提供服务,仅遵守美国及欧盟有关数据合规的法律显然是不足够的。
API接入时,各方的角色分别是什么?
根据Open AI在其官网公示的《数据处理附录》(Data Processor Addendum)及ChatGPT的回答,当以API接入的方式封装ChatGPT以对外提供人工智能服务时,接入方通常属于数据控制者(即对应我国个人信息处理者),Open AI通常属于数据处理者(即对应我国受托人)。

分析:合规性存疑
这个回复与最近刚出台的《管理规定》一脉相承,即在封装ChatGPT对外提供服务时,接入方是个人信息处理者,需要对外承担个人信息处理者的责任及义务。不过正如ChatGPT所提到的,个人信息处理者与受托人的角色可能因实践操作而有所不同,当Open AI决定了个人信息处理的主要目的和方式时,则有可能成为共同个人信息处理者。
Open AI在数据安全方面的认证资质有哪些?
《隐私政策》第8部分(“Security and Retention”)就Open AI的数据安全措施做了一般性的表述。对此,我们额外询问了ChatGPT,Open AI在数据方面是否具备相关认证资质(如ISO27001信息安全管理体系认证等),但ChatGPT显然已经“招架不住”,甚至开始自行“编造”(如列出引用文章和链接,但查无此事)。



结语
综上,我们总结ChatGPT《隐私政策》的合规性分析如下表所示:

基于对《隐私政策》自身文本的分析,结合ChatGPT的回复,我们凝练为下述六大核心数据合规问题:

对于上述合规问题的具体分析,将于后续系列文章中展开。
未经允许不得转载
