导读
Grok-1是马斯克旗下的xAI公司开源的大语言模型,参数量达到了3140亿,远超OpenAI GPT-3.5的1750亿,是迄今为止参数量最大的开源大模型。Grok-1还是一个混合专家大模型,可以将不同领域的“专家”集中到一起,以此来提升效率。
由于模型参数量庞大,运行Grok-1需要充足的GPU内存,最低配置要求约为630GB显存。 除此之外,GGUF格式可用于快速加载和保存Grok-1模型文件,提高模型加载和推理速度。
DCU,大语言模型应用的解决方案
海光DCU (Deep Computing Unit)是一款面向人工智能、科学计算的高性能全功能GPGPU加速卡。它以GPGPU架构为基础,兼容通用的“类CUDA”环境。
海光DCU凭借其丰富的软件栈DTK(DCU ToolKit),全面兼容ROCm GPU计算生态,以及CUDA生态、工具链和开发者环境等。它能助力大语言模型的训练、推理、部署等应用,已适配众多模型,达到国内领先水平。

Grok-1基于Transformer模型架构,拥有3140亿参数,共包含64个Transformer层,每层都包含一个解码器层,由多头注意力块和密集块组成。多头注意力块有48个头用于查询,8个头用于键/值(KV),KV大小为128。密集块(密集前馈块)的加宽因子为8,隐藏层大小为32,768。采用MoE混合专家系统设计,每个token从8个专家中选择2个进行处理。Grok-1的激活参数数量为860亿,表明其在处理语言任务时的潜在能力强大,同时使用旋转嵌入位置编码,这是一种处理序列数据的方法,可以提高模型处理长文本的能力,上下文长度最大支持8192个tokens。
混合专家模型(MoE)
xAI能在较短时间内训练出Grok-1,得益于其模型结构采用了MoE设计。MoE具有以下特点:1.与稠密模型相比, 预训练速度更快。2.与具有相同参数数量的模型相比,具有更快的推理速度。3.需要大量显存,因为所有专家系统都需要加载到内存中。混合专家模型 (MoE) 的理念起源于1991年的论文 Adaptive Mixture of Local Experts。
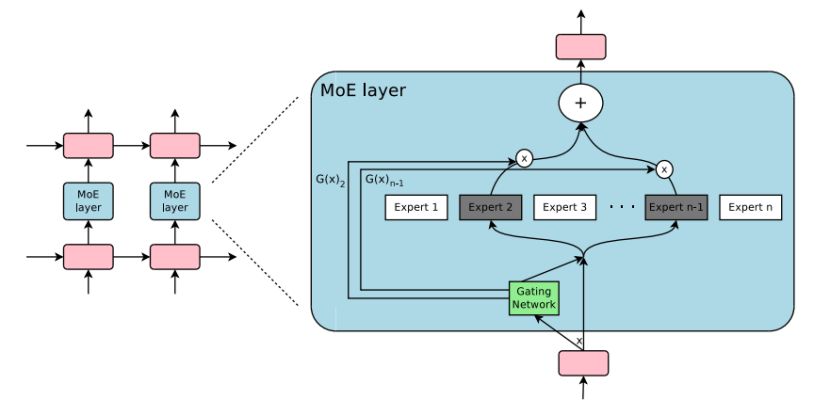

MoE并行计算
在正确安装DCU环境后,搭建docker容器环境
1# 1.拉取docker镜像
请优化以下文章内容,保留原文数据,不超过109字:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/jax:0.4.23-ubuntu20.04-dtk24.04-py310
```
4 # 2.创建容器
5 docker run -it --name your_container_name --privileged --shm-size=1024G -v /opt/hyhal:/opt/hyhal --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v path_to_your_directory:path_to_your_directory imageID /bin/bash
7# 3.拉取grok仓库代码
10 # 4.安装所需库
11 # 需注意将jax库注释,已在镜像容器中采用DCU编译后的jax库。
12 cd grok-1
13 pip install -r requirements.txt
14
15# 5.推理


在海光DCU上运行Grok-1模型,不仅展示了其卓越的计算性能,还证明了国产GPU在大语言模型领域的巨大潜力。通过DCU的高效计算能力,推理过程更加流畅。DTK工具包的丰富功能和兼容性,使开发者能够轻松迁移和优化现有模型,从而减少开发时间和成本。此外,海光DCU的出色性能使得Grok-1能够处理更大规模的数据集和更复杂的模型结构。这为研究人员和企业提供了更高效的开发和部署环境,促进了AI技术在各个领域的应用。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-