模型表现好,金牌少不了。刚刚,中文大模型测评基准SuperCLUE发布《中文大模型基准测评2024年10月报告》:商汤日日新·商量大模型(SenseChat5.5)凭借出色的能力表现,总得分位列国内大模型第一梯队,获得金牌。
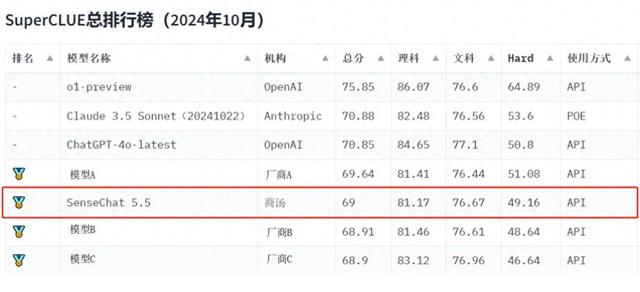
本次SuperCLUE10月报告覆盖23个国内模型,聚焦语言大模型的通用能力评估,分为三大维度:除了考察“文科”、“理科”基础能力外,还有考察模型更高阶能力的“Hard”附加任务,总共2900+道题:
【理科任务】分为计算、逻辑推理、代码、工具使用测评集;
【文科任务】分为知识百科、语言理解、长文本、角色扮演、生成与创作、安全六大测评集;
【Hard任务】分为精确指令遵循测评集,复杂任务高阶推理测评集。

商汤SenseChat5.5在多项评测任务中均位列第一梯队,文科中语言理解、安全等维度表现突出,也是理科中逻辑推理、代码学科的“尖子生”。
值得注意的是,在【Hard】的两项任务——精准指令遵循和高阶推理中,商汤SenseChat5.5是唯一两项任务均位于国内第一梯队的大模型,体现了模型优秀的复杂推理智能。
SuperCLUE本次报告显示,国内大模型的能力与ChatGPT-4o-latest表现接近,o1-preview则在复杂任务中更为突出。未来,商汤将继续坚持基础大模型的持续研发与投入,不断提升真正高阶推理及“慢思考”能力。
记者 王成礼报道
