
文|魏琳华 刘俊宏
编|王一粟
2024年3月,OpenAI关停仅运营两个月的GPT Store。
时隔仅7个月,同样是做Agent平台,OpenAI现任董事会主席Bret Taylor创立的新公司,融了45亿美元。整个AI界在前后发布的Claude的“Computer Use”和智谱的AutoGLM智能体下,开始了一场“丢下”OpenAI的狂欢。
10月26日,微软开源了基于纯视觉的GUI屏幕解析工具OmniParser,谷歌的同类产品“Project Jarvis”也有望在12月上线。
加入狂欢的不止是大模型厂商。和智谱宣布达成深度合作的一个月后,荣耀也交出了自己的答卷。10月30日,荣耀CEO赵明展示了AI智能体YOYO自主处理任务的能力,只需要对手机说一句“订2000杯咖啡”,YOYO就帮他在附近下单成功,忙坏了周围的咖啡店和外卖员。
无论是电脑端还是手机端,Agent开始真正实现了“自主性”:从点咖啡到买牙膏,无需人类操作,一句指令就能让AI完成所有任务。和前一代只能提建议的Agent相比,AutoGLM实现了从1.0到2.0的进阶。
二级市场的热度,也被智能体点燃。发布AutoGLM后,一众投资、参股智谱,或是和智谱合作密切的公司股价明显上涨,“智谱概念股”走强。上周开始,智谱概念股持续活跃,豆神教育、思美传媒、常山北明等相关概念股一度涨停。
当端侧大模型开始落地到手机端,苦于落地的大模型厂商,不仅仅只将目光放在了软件能力上,从智能体到做以大模型为能力中心的“AI OS”,大模型创企们找到了AI大模型商业化的新道路。
在OpenAI错过的7个月中间,Agent到底发生了什么变化?
AI Agent进入2.0时代为什么智能体突然点燃了二级市场的热情?
华泰证券指出,AI Agent已经解决了大模型从“言”到“行”的突破。
对比上一代“只动嘴皮子”的Agent,无论是Computer Use还是Phone Use,上述智能体产品均实现了AI端的自主操作:接收到指令后,AI将亲自接管设备,包括点击、输入等交互功能。
以Anthropic发布的“Computer Use”为例。演示中,无需人类操作,它完成了“填写公司表格数据”的任务。
接到上述任务后,AI将工作拆分为多个步骤:
1、首先,查找已有表格中是否有所需公司的相关数据;
2、在查询不到结果后,AI打开搜索界面,自行查找相关公司的数据信息;
3、最后,它对应着表格的空缺部分逐个完成数据的输入。
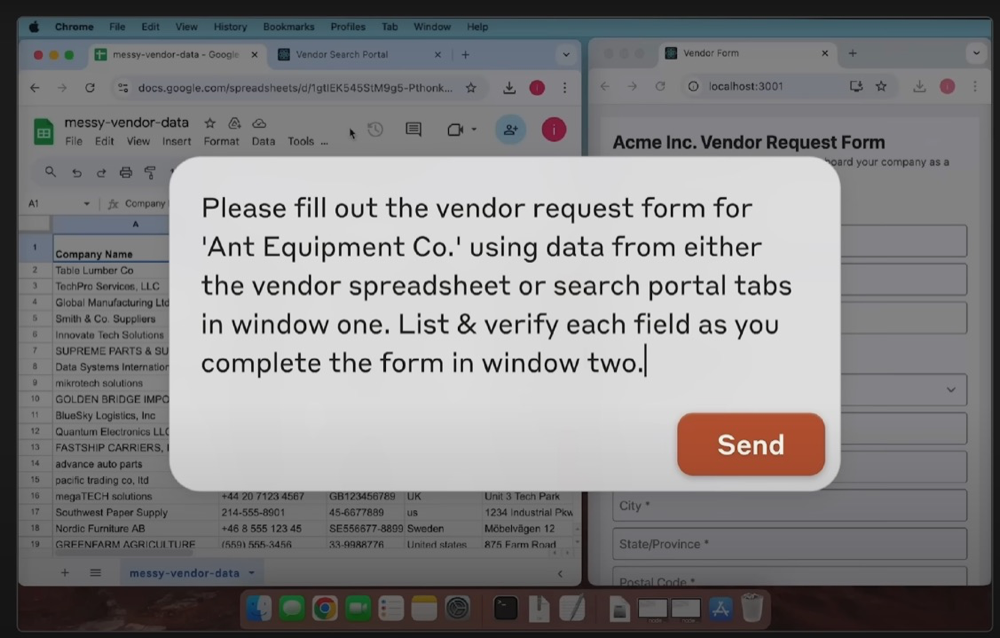
通过在对话栏输入指令,AI自主根据表格信息情况完成填写
在展示视频中,智谱发布的AutoGLM 调用手机上的多个App也很丝滑,当用户要求购买瑞幸的美式咖啡,AutoGLM打开美团搜索品牌,并把想要的商品自动加入购物车,并跳转至结算界面。交给用户的,只有选择“下单”按钮。
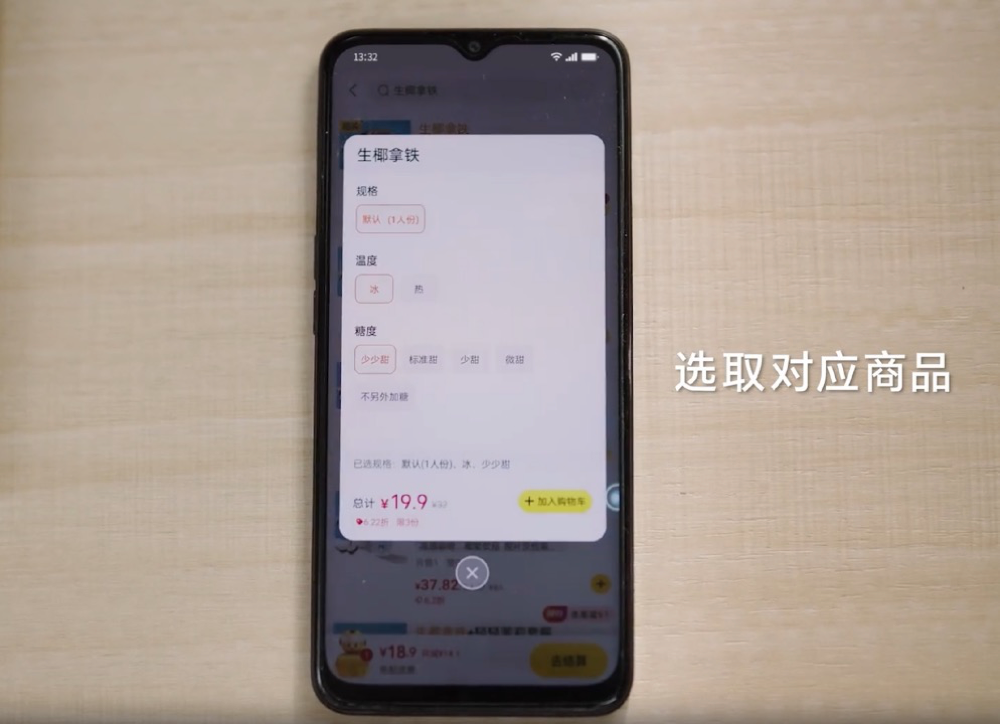
根据用户的需求,AI自主选定咖啡的口味
微软也在近日开源了一个用于识别Web端视觉界面的工具产品OmniParser。在Github展示页的示例视频中,OmniParser也做到了自主操作的能力:
当交付给它一个收集素食餐厅的任务时,OmniParser通过解析界面元素,在网页中定位到“餐厅”字样。检索不符合要求后,它再自动拉起搜索框,根据关键词定位到相关餐厅,并完成勾选。
这些对人类来说非常简单的操作,交给AI,需要克服的障碍不少:
首先,无论是电脑端还是手机端的交互,Agent均需要完成点击、划动、查找等步骤,如何让模型学会并做到精准操作,这是阻碍Agent进化的一大难题。
而这个难题的突破,得益于基础大模型发展带来的能力跃迁。
比如,如何让AI理解GUI(图形用户界面)并完成操作?
Agent的核心系统分为感知-规划-记忆-行动-工具五个部分,其中,感知系统负责捕捉外界的视觉、听觉、文本信息,并加以分析。通过对上述信息的完整认知,Agent会结合这些信息对接受到的任务进行规划,也就是用CoT(思维链)的方式拆解成多个步骤,依次执行。
但在2023年,大语言模型仍然停留在文本能力阶段,在视频、语音等多模态能力发展尚未突破的时候,Agent受底层基座能力的限制,尚且无法完整感知环境,从而在多个任务上的执行过程中犯错,自然也难以达到应用阶段的水准。
对此,微软的解决方案是,通过屏幕截图的方式,将屏幕中的所有可交互图标和按钮一一标注出来,将它们提取为信息,再根据识别的内容进行定义,让AI理解每个交互点的作用,从而实现自主操作。而智谱AutoGLM在手机端的操作应用,同样借助了多模态能力来完成对UI的识别解读。

而在上述基础上,针对数据不足、策略分布漂移等问题,智谱也找到了问题的解法。
比如,受制于轨迹数据获取成本高昂和数据不足的问题,无法对大模型智能体完成充分的动作执行能力训练。
为此,他们在AutoGLM中引入自研的“基础智能体解耦合中间界面”设计。以“提交订单”为例,把AutoGLM作为中间界面,将「任务规划」与「动作执行」两个阶段通过自然语言中间界面进行解耦合。
对比过往端到端智能体的直接处理,这种方式将AI的操作准确度提升了将近一倍。
除了实现精准交互操作的需求之外,面对种类繁多的复杂任务,智能体还需要具备即时规划和纠正能力,从而在遇到问题的时候及时给出有效的解决方法。
对此,AutoGLM上应用了“自进化在线课程强化学习框架”技术,让智能体在基于手机和电脑的环境中不断学习和提升应对能力。
“就像一个人,在成长过程中,不断获取新技能。”张鹏解释道。
在上述两种能力的加持下,AutoGLM 在 Phone Use 和 Web Browser Use 上都取得了大幅的性能提升。官方数据显示,在 WebArena-Lite 评测基准中,AutoGLM 更是相对 GPT-4o 取得了约 200% 的性能提升。
总体来看,在大语言模型和多模态模型进化一年之后,AI Agent终于实现了从单体智能,向使用工具方向迈进,完成了2.0的进阶。
学会使用工具人工智能进入L3阶段纵观人工智能的发展史,人工智能和人类的进化路径何其类似,正在经历从学会“语言”,到“解决问题”,再到“使用工具”。
3个多月前,OpenAI将通往AGI之路划分为五个阶段。AutoGLM上线当天,智谱也向外界公示了自己的技术路线图。

首先在L1阶段,AI的重点在于学会使用“语言”,包括语音、文字还有视觉。
回顾两年前,从ChatGPT诞生开始,人们对AI的注意力开始转移到生成式AI上。在短短半年的时间里,大语言模型频频涌现:GPT、Claude、GLM等系列大模型出现并持续更新换代,它们均围绕语言理解、逻辑能力等指标完成进化。
在大语言模型之外,AI厂商还把关注点放在了另一座高峰——多模态大模型上。围绕视觉、听觉等能力,实现了从无到有的突破:
从今年上半年开始,端到端语音模型开始先后发布,它让AI能够“听到”人的情绪,并完成有温度的交流。
今年4月,GPT-4o的发布会向人们展示了和AI实时对话的魅力。和以往模型相比,端到端语音模型将过往的多个大模型串联完成的任务压缩到一个模型中完成,降低时延的同时,还能完整保留人声的情绪、停顿等信息,可以随时打断它并继续交流。
多模态模型则让大模型装上了“眼睛”,看到并理解现实世界环境的变化。
以智谱的GLM-4V-Plus为例,它不仅能够完成大语言模型的对话能力,同时,在视频、图像的理解能力上提升明显。智谱还推出了视频通话API接口GLM-4-Plus-VideoCall,让大模型能够和人类打“视频通话”,识别周边物品并对答如流。
“大脑是一个非常复杂的系统,包括听觉、视觉、味觉、语言等多模态的感知与理解能力,有短期和长期记忆能力,深度思考和推理能力,以及情感和想象力。”张鹏说。
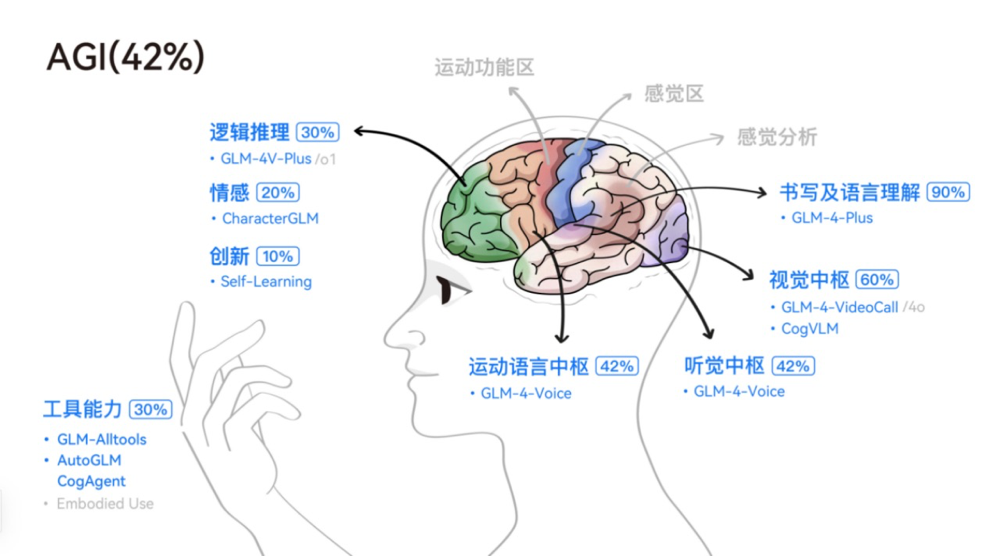
可以看到,当前阶段下,大模型能力开始能够模拟人脑的一些功能,包括视觉、听觉、语言理解等能力。
智谱方面透露,在他们规划的五个阶段中,L1能力“已经达到了80-90%”。
在听说读写等基本能力的进化过程中,代表L2的逻辑思维能力,也在快速进化。
L2的一个里程碑就是OpenAI发布的o1模型,跳脱出过往的GPT大家族,专注于CoT(思维链)能力上精进,它学会了慢思考:在应用思维链,将指令拆分为多个简单步骤完成的同时,o1用强化学习的能力,用于识别和纠正错误。
OpenAI表示,随着强化学习的增加和思考时间的增加,o1的性能会持续提高。官方数据显示,在Codeforces主办的编程竞赛上,o1取得了超越93%参赛者的成绩,并在物理、化学、生物等基础学科的能力指标上取得了超过博士生的水准。
因此,o1也被视为人类在L2逻辑思维能力上取得的新进化,开始展现和人类旗鼓相当的推理能力。
当L1语言和多模态能力基本打通后,基于上述底层能力,才能涌现出达到L2逻辑思维能力和L3工具能力级别的新产品。
而这次升级的智能体操控智能终端的能力,实际上在L3阶段。
正如哲学家恩格斯所言,人类和动物,最本质的区别就是——能否制造和使用工具。
智能体2.0的升级,也代表着人类在通往AGI的路线上,又拿下了一城。
“AutoGLM 可以看作是智谱在 L3 工具能力方面的探索和尝试”,张鹏表示。
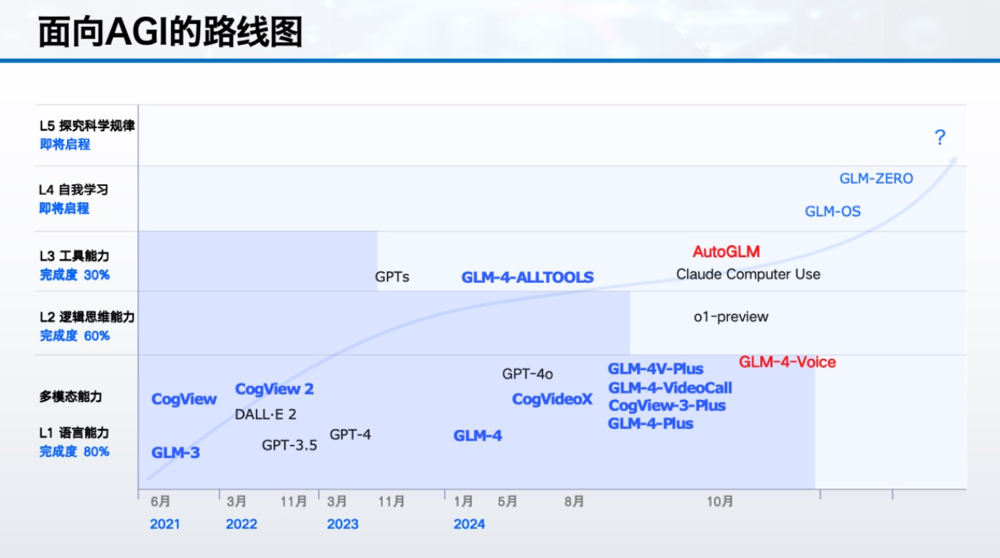
展望L4和L5,OpenAI认为,L4阶段,AI能够自我完成创新;L5阶段,AI则具备融入或自成组织的能力。
而智谱也对L4和L5阶段给出了新的定义,相对于OpenAI,智谱对AGI的期待更加激进。
“我们认为 L4 级人工智能意味着 AI 可以实现自我学习、自我反思和自我改进。L5 则意味着人工智能全面超越人类,具备探究科学规律、世界起源等终极问题的能力。”张鹏表示。
端侧大模型AI落地的新高地当AI进阶至L3阶段,大模型厂商们在商业化的进程上也按下了“加速键”。
事实上,终端硬件和大模型厂商们正在双向奔赴。观察今年发布的AI硬件,是否搭载Agent,对应着产品AI能力的“天差地别”。
最显著的对比,是10月30日发布的,搭载YOYO智能体的荣耀Magic7。
基于智能体可直接执行任务的特性,赵明一句2000杯饮料的需求,爆单了附近所有咖啡店。从“一步步”交互,到智能体“脱手自动执行”,赵明自豪地宣布道,“手机进入自动驾驶时代”。
为了挖掘硬件端和AI能力结合的潜力,智能终端厂商和大模型公司的联姻早已见怪不怪。
其中,智谱是当前国内大模型创企中和手机厂商联动最多的一家。此前,智谱已经和荣耀官宣战略合作,而在最近半年的时间中,其先后和三星、英特尔、高通联手,通过提供底层AI能力支持终端智能化升级。
同样,苹果就认为,Apple Intelligence的智能体将直接改善苹果手机的销量。在刚刚结束的苹果2024年四季度财报电话会中,CEO库克称,“iPhone 16系列卖得比iPhone 15系列更好,Apple Intelligence上线后,用户升级iOS18.1版本的积极性都是去年同期的两倍。”
加持AI,将是手机厂商未来多年的重要战略。根据IDC预测,预计2024年AI手机出货量将同比增长363.6%,达到2.3亿部。IDC手机研究总监Anthony Scarsella表示,在2024年实现三位数增长之后,AI手机将连续四年实现两位数增长。
为何硬件终端厂商如此热衷于智能体的落地?背后是智能体从底层颠覆了硬件厂商与消费平台之间的权力地位。
以“赵明点咖啡”为例,在没有智能体之前,用户点咖啡大多依赖渠道惯性。用户需要根据习惯、优惠券、积分等因素,在美团、星巴克小程序、饿了么等平台之间选择下单。而有了替用户下单的智能体之后,由于平台不再直接对接客户,智能体有了为平台直接分配订单的权利。换句话说,通过搭载智能体,AI终端厂商有了向软件平台“征税”的权利。
如同苹果当前被无数厂商“痛”,又无可奈何的“苹果税”。正是因为掌握了App Store的分发和流水,苹果才能依靠几乎“躺赚”的商业模式,才能以平均高达70%以上毛利率的软件服务收入,拉高整个公司的营收质量。
据2024年四季报显示,苹果本季度软件服务业务的营收占比为26%,业务毛利率为74%,公司整体毛利率为44%。
看到如此优质的营收,也难怪AI硬件厂商“大干快上”智能体。而看到了这场全新变现模式的大模型公司,也纷纷与AI硬件厂商展开了合作。
除了加码修图、文本总结等AI软件功能、植入智能体之外,打造端侧大模型,并将其深度融入硬件系统,成为原生能力,是手机厂商加码AI能力的下一步。
基于端侧大模型提供的核心能力,AI手机正在做到更多之前无法完成的事情,用智能体做事还是第一步。
相比之下,智谱还有更加宏大的野心,他们更希望将AI能力深度植入终端,用大模型重塑操作系统。
“希望我们的努力能够推动人机交互范式实现新转变,为构建 GLM-OS ,即以大模型为中心的通用计算系统打好基础。”在发布AutoGLM时,张鹏如是说。
不仅智能手机关注AI能力的加码,芯片端也在加速和AI能力的融合。上个月,高通宣布将智谱GLM-4V端侧视觉大模型搭载到芯片骁龙8至尊版,进行深度适配和推理优化。其推出的应用ChatGLM支持用相机进行实时语音对话,也支持上传照片和视频进行对话。
在AI完美落地具身智能之前,手机、电脑等终端将是AI大模型落地的更佳场景。通过L3工具能力的展现,AutoGLM们将有机会撕开新的商业模式。
不过,智谱的AutoGLM目前还是通过调用手机的无障碍权限实现跨应用调用,未来如果想要完成更加复杂的指令,还需要和智能终端厂商以及应用开发商达成深度合作,从而获取更多操作权限。
大模型的“软”实力,最终还得“硬”实现。
目前,大模型的商业化仍然是以软件付费为主,包括面向C端的订阅制和面向B端的API接口或者项目制。但在未来,要想真正实现AGI,以及释放更强大的能力,还得是通过硬件来和物理世界交互。
智能体在端侧的落地,就像一个机遇,帮助大模型公司在硬件上积累了众多的工程化能力,甚至还能获得一些不错的边缘数据。这给未来,无论是通过XR设备还是具身智能机器人,来完成物理世界的交互,都打下了一个好的基础。
未来,在智能终端上的落地,将是大模型技术和商业化的新高地。
