如今,全球大部分互联网应用,以及相当一部分企业服务都跑在云上。云服务一旦出现宕机、服务中断,将为整个经济社会带来巨大的经济损失。尤其是对于那些依赖实时数据处理和分析的行业,如金融交易、在线零售和社交媒体平台,宕机可能导致巨大的经济损失和客户信任度下降。
每年,全球范围内都会发生数起大规模云服务中断事故。这些事故无一不在警告业界:云服务的韧性至关重要。
韧性是指应用程序抵御中断或从中恢复的能力,包括与基础设施、依赖服务、错误配置、网络问题和负载激增相关的中断。
作为全球云计算行业的领头羊,亚马逊云科技如何构建云端韧性,保障云服务的高可靠高可用?
近日,亚马逊云科技大中华区解决方案架构总经理代闻向国内媒体分享了亚马逊云科技实现云端韧性的技术经验与方法论。
“亚马逊云科技2023年每天稳定启动的Amazon EC2实例超过1亿,每秒API请求数高达100万亿。正是因为做对了很多事情,才有今天全球数百万客户的选择和信任。”
具体来说,亚马逊云科技从基础设施、架构设计、运营机制三大维度构建云端韧性。

导致基础设施层面故障的原因有很多,主要包括:数据中心、主机、机架、网络故障或自然灾害导致的损坏等等。为了将故障概率降至最低,云服务商在做全球基础设施设计时就要提前规划很多因素。
目前,亚马逊云科技的基础设施遍及全球34个地理区域的108个可用区。每个地理区域由三个或更多个相互独立的可用区组成。
在可用区设计方面,亚马逊云科技的一大原则是独立、隔离。
每个可用区都有独立的电力、制冷和物理安全设施。同一区域内的可用区之间的物理距离也经过精心计算——通常是100公里以内。这样既能防止如供电、冷却等常见故障点,也能避免同时受到如地震、洪水等大规模灾害的影响。
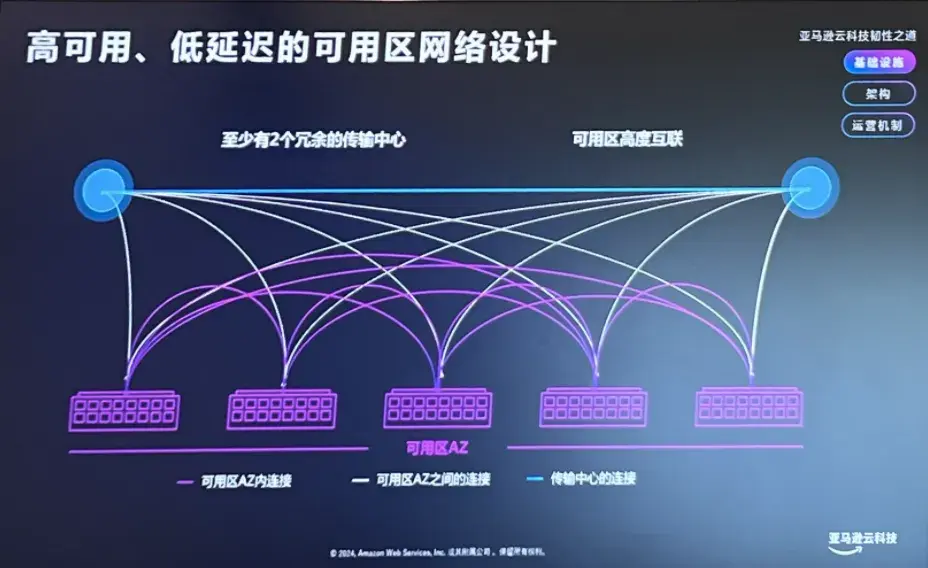
第二个原则是高可用、低延迟的网络设计。
在可用区内部,可用区之间,区域和区域之间,均铺设光纤线路两两互联,实现高速数据传输的同时,任一连接都是冗余的,保证可实现可用区间单位毫秒级延迟的数据同步复制。
以亚马逊云科技(北京)区域和(宁夏)区域两个区域为例,宁夏或北京的每个可用区间由至少两个传输中心互联,任一可用区的任一数据中心均有多条冗余链路与传输中心互联,跨可用区的任意一个数据中心可通过传输中心互联。
在服务/系统设计时,亚马逊云科技通过对服务的控制平面和数据平面进行隔离设计,并采用 “单元架构”设计模式,减少故障发生的可能,并尽可能降低故障发生时的影响范围。
第一,区域隔离,多可用区设计
基于明确的物理及逻辑故障边界设定,亚马逊云科技将服务分为三种类型:全局(Global)服务、区域级(Region)服务、可用区级(AZ)服务。
全局服务的数据平面是在每个区域中独立存在,比如身份识别与访问管理服务Amazon Identity and Access Management(Amazon IAM)。
区域级服务是建立在多个可用区域之上的服务,数据平面和控制平面都是区域级别,比如对象存储服务Amazon S3 。
可用区级服务可在一个区域内的每个可用区中独立运行,不依赖于其他可用区中的组件,可用区服务可以指定将资源部署到哪个可用区,比如Amazon EC2。
不同类型的服务有不同的故障隔离策略。以全局服务Amazon IAM为例,它的数据平面独立存在于每个区域(Region),该区域中的每个云服务都直接与Amazon IAM数据平面交互。当 IAM 控制平面故障的情况下,无需任何更改,每个区域的身份验证和授权(即IAM的数据平面)都可以继续正常运行。

第二,将服务分为控制平面和数据平面,并对他们进行分离设计。
这样当控制平面发生故障的情况下数据平面仍能继续正常运行。
控制平面提供用于创建、读取/描述、更新、删除和列出(CRUDL)资源的管理 API,例如启动新的 Amazon EC2 实例、创建 Amazon S3 存储桶以及描述 Amazon SQS 队列等。
数据平面是提供服务的主要功能,例如正在运行的Amazon EC2 实例本身、读取和写入Amazon EBS 卷、在 Amazon S3 存储桶中获取和放置对象等。
如果拿火车运输做比喻,控制平面相当于指挥中心,数据平面则是铁路线路,当指挥中心如通讯系统出现临时故障时,火车仍然能按照既定线路运行。
第三,通过单元架构设计降低“爆炸半径”(故障发生时的影响范围)。
单元架构将服务切分为多个部署堆栈,每个部署堆栈称为“单元” ,每个单元之间都是互相独立的,不共享任何内容,包括数据库,每个单元服务于一个或多个客户。
采用了单元架构后,以可用区级别的服务为例,服务发生故障的影响范围就限制在单元内,而不是整个可用区。
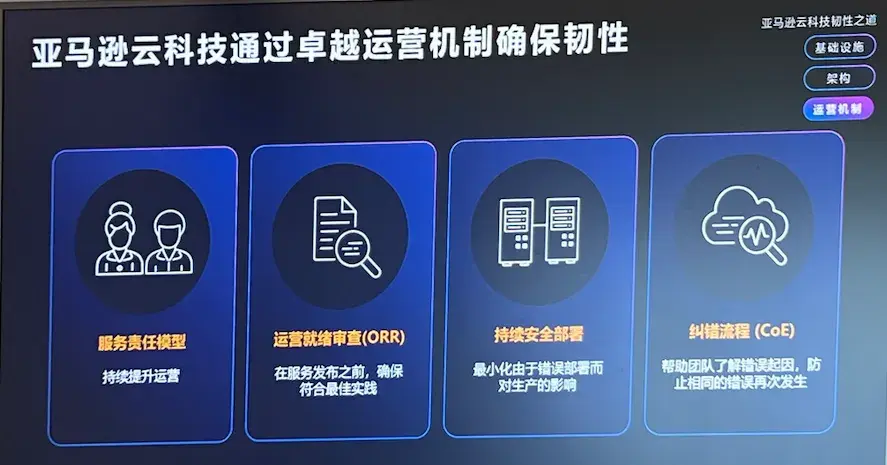
运营机制:四大机制确保云服务韧性亚马逊云科技通过四大运营机制模块:服务责任模型、运营就绪审查、持续安全部署、纠错流程,来确保云服务的韧性。
在服务责任模型下,技术人员不仅要负责设计和启动服务,还要在生产期间运营它,并在出现问题时随叫随到。
运营就绪性审查是指在发布和更新亚马逊云科技服务之前,还需要使用运营就绪性审查(ORR)流程对所有新服务进行审查。
在服务更新或推出新服务时,通过使用广泛的生产前测试、自动回滚和交错生产部署,将自动化部署安全性构建到发布过程中,能够最大限度地减少错误部署对生产造成的潜在影响。比如,服务更新首先推出到AZ内的单个服务器,验证没有出现问题后更新部署到整个AZ的其余部分,然后部署到其他AZ,然后部署到单个区域,最后部署到其余区域。
同时,出现任何问题会利用纠错(CoE)流程等事件管理机制来帮助团队了解根本原因。
系统化的云端韧性是全球百万客户最看重亚马逊云科技的优势之一。目前,借助高可靠的云服务,帮助各行各业客户打造自身业务可靠性方面,亚马逊云科技已经积累了众多成功案例。
2022 年,奇瑞捷豹路虎选择将关键的 SAP 系统迁移至亚马逊云科技云上。借助高可用和同城灾备融合方案,亚马逊云科技帮助奇瑞捷豹路虎使用云上三个可用区及引入仲裁方案使集群可靠性、稳定性得到增强,最大限度地减少了停机时间和保障零数据丢失,将故障切换时间从半小时缩短至 3 分钟。
亚马逊云科技帮助跨境电商服务商紫讯构建了多区域容灾架构,对核心组件如Amazon Aurora数据库进行高可用改造,实现主备设置与故障转移。最终实现核心产品SLA提升至99.995%,RTO在10分钟内、RPO小于1分钟等目标。
亚马逊首席信息官 Werner Vogels曾说过“Everything fails all the time”(故障总在情理之中、意料之外)。云端韧性能力是应对不可避免的故障的一大利器。
未来,亚马逊云科技将持续为客户提供广泛、深入的架构及运营最佳实践的服务、工具和指导,帮助客户在云中构建和运行韧性的应用程序。
END
本文为「智能进化论」原创作品。
