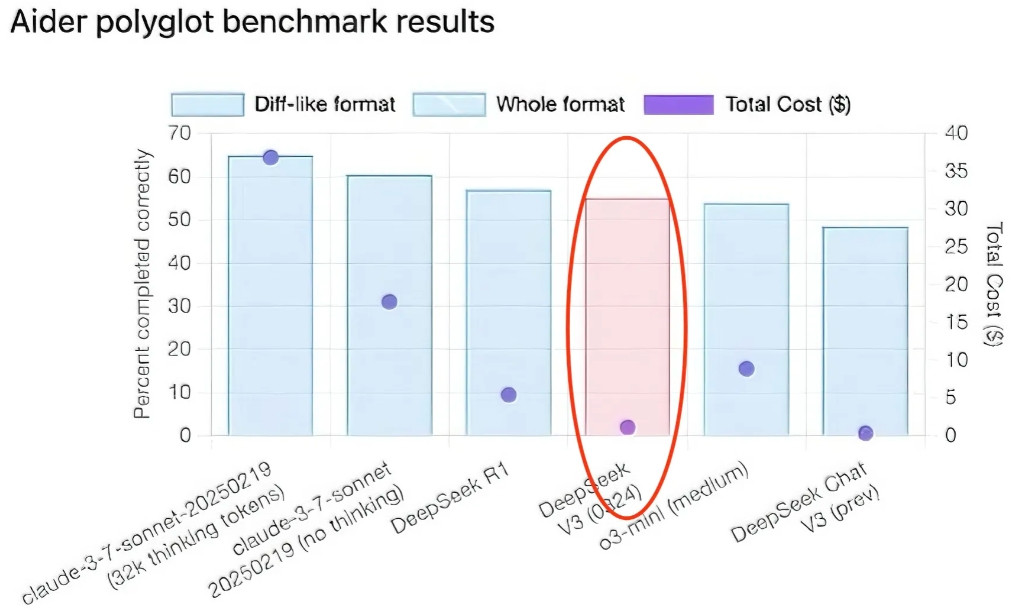
【[44星] Awesome MLLM Reasoning Benchmarks:全面评测多模态模型的项目,旨在构建和评估多模态大型语言模型的推理能力。核心价值:提供了一系列基准测试,用于评和提升多模态大型语言模型的逻辑推理能力,涵盖数个领域,如数学推理、图表理解、科学推理等。亮点:1. 包含 43 个基准测试,覆盖广泛的推理类型;2. 提供了详细的代码、数据集和项目链接,方便研究和应用;3. 支持跨语言的基准测试,包括中英文内容,增强了通用性和包容性】'Awesome MLLM Reasoning Benchmarks: A Comprehensive Survey on Evaluating Reasoning Capabilities in Multimodal Large Language Models' GitHub: github.com/Wild-Cooperation-Hub/Awesome-MLLM-Reasoning-Benchmarks 多模态推理 大型语言模型 人工智能 AI 创造营