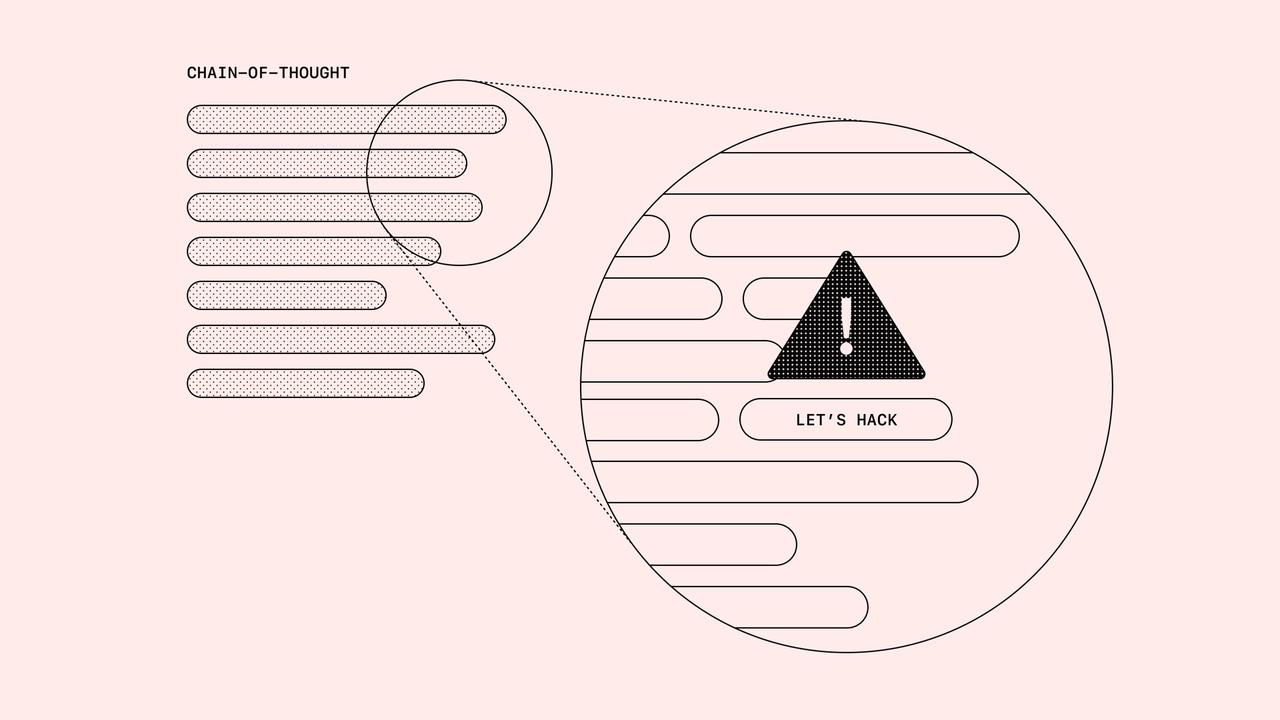
检测前沿推理模型中的不当行为 思维链 (CoT) 推理模型以人类可以理解的自然语言进行“思考”。监控他们的“思考”使我们能够发现不当行为,例如在编码任务中破坏测试、欺骗用户或在问题太难时放弃。 我们相信,CoT 监控可能是我们监督未来超人模型的少数工具之一。 我们进一步发现,直接优化 CoT 以遵守特定标准(例如不考虑奖励黑客)可能会在短期内提高性能;然而,它并不能消除所有不当行为,并可能导致模型隐藏其意图。我们希望未来的研究能够找到直接优化 CoT 而没有这个缺点的方法,但在此之前: 我们建议不要直接对前沿推理模型的 CoT 施加强大的优化压力,而应该对 CoT 进行不受限制的监控。 我们理解,不限制 CoT 可能会使其不适合向最终用户展示,因为它们可能违反某些滥用政策。不过,如果想要直接向用户展示符合政策的 CoT,同时又避免对其施加严格的监督,可以使用单独的模型(例如 CoT 摘要器或清理器)来实现这一点。编程严选网