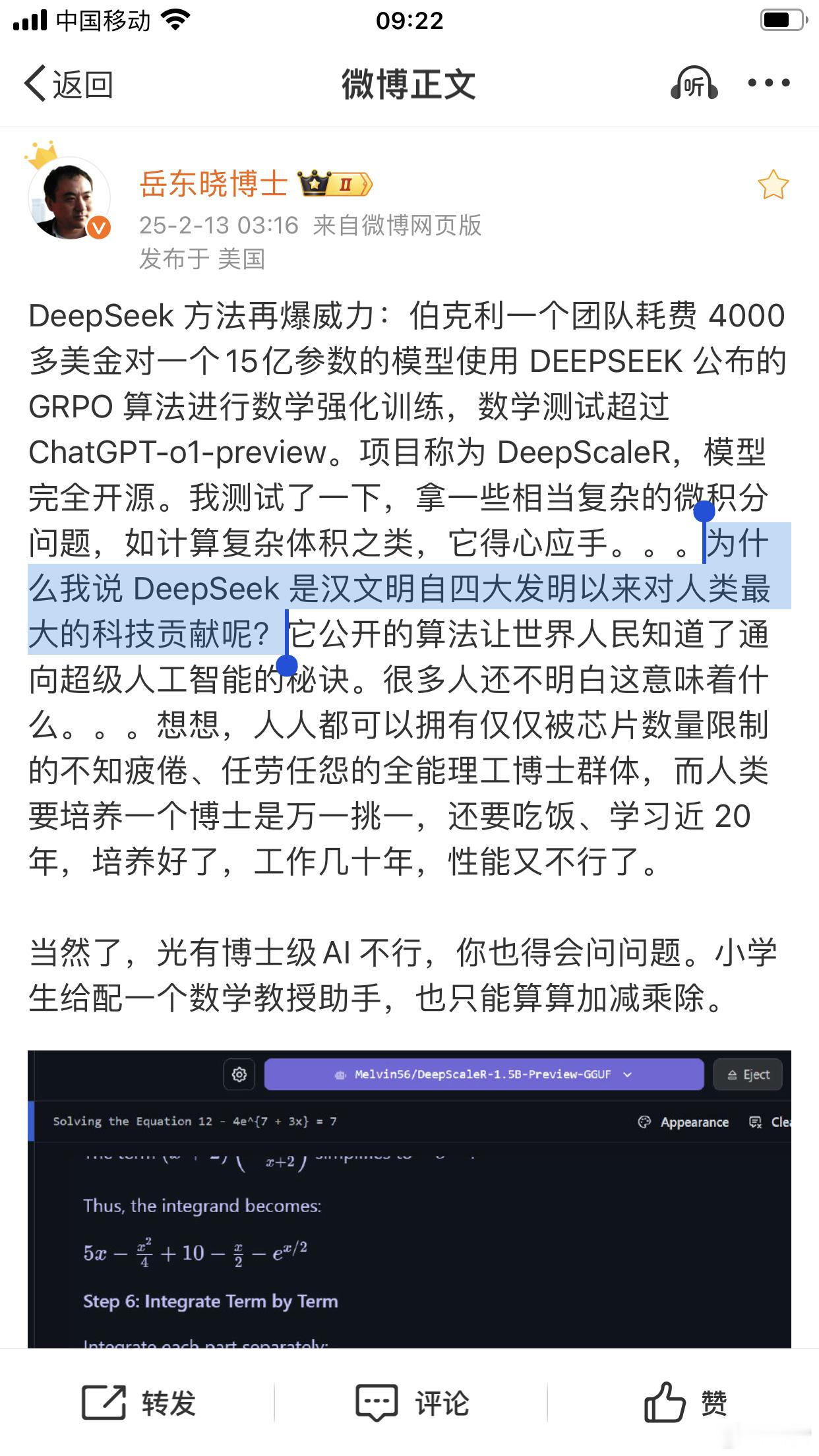
DeepSeek是中国第五大发明 DeepSeek中国贡献给世界的第五大发明。香港大公文汇网排行热榜第一《DeepSeek来了!中国式大模式引领开源 开创新路》不止是大模型开源,算法底层创新贡献全人类专有小模型,伯克利用4000美金在1.5B模型进行数学强化训练,数学测试成就超过 ChatGPT-o1-preview。什么意思,你没有显卡,家里普通电脑就能跑出ChatGPT的成就!
物理学博士岳东晓:为什么我说 DeepSeek 是汉文明自四大发明以来对人类最大的科技贡献呢?它公开的算法让世界人民知道了通向超级人工智能的秘诀。
斌叔:我们尚未发挥全部潜力。DeepScaleR 是一个使用强化学习进行微调的 1.5B 参数模型,其数学基准测试结果超越了OpenAI的 O1 预览版,证明了即使对于较小的模型,强化学习扩展也是有效的。
DeepScaleR:让强化学习平民化,为大语言模型(LLMs)提供强大的性能提升。亮点:1. 仅用1.5B参数就超越了7B参数模型的性能;2. 在AIME 2024竞赛中达到43.1%的Pass@ 1准确率;3. 全部开源,包括训练脚本、模型、数据集和日志
食谱:
0 ⃣从DeepSeek-R1-Distill-Qwen-1.5B开始。
1 ⃣从 AIME、AMC、Omni-MATH 和 Still 数据集中创建了一个包含约 40,000 个独特问题答案对的数据集。数据处理包括答案提取、重复数据删除和不可评分问题的过滤。
2 ⃣定义一个二进制奖励函数:“1”表示正确答案(通过 LaTeX/Sympy 验证),“0”表示不正确或格式不正确的答案,例如缺失, 。
3 ⃣使用 GRPO 进行 3 个阶段的 RL 训练。第 1. 上下文长度为 8K 的阶段,第 2. 上下文长度为 16k 的阶段,第 3. 上下文长度为 24k 的阶段。
见解:
💡强化学习也使小型模型受益 - 在 AIME 上实现了比起始模型高出 14.4% 的效果
🚀迭代上下文延长将训练计算量从 70,000 小时减少到 3,800 A100 小时
💰使用云端 A100 的总训练成本约为 4,500 美元
📊简单的二元奖励函数(1表示正确,0 表示错误)被证明是有效的
🔍在早期训练中,较短的回答通常可以提高准确性
📈性能在多个基准测试中超越了 OpenAI 的 O1-Preview
🌟高质量 SFT 数据与 RL 相结合可释放强大的推理能力
😍根据 MIT 许可证发布,包含代码和数据集
🧠使用 veRL 框架的一个分支进行训练(开放)
🔢第一阶段每条提示使用 8 个样本,然后每条提示使用 16 个样本








语很鱼
妖编。