DeepSeek,让open的AI子弹飞一会
1、DeepSeek,开源、低价、展示思维链。其中开源、低价、测评数据是硬性指标,而R1展示思维链是其能在C端爆火的重要原因;对普通消费者而言,其思考过程甚至比输出结果更有趣,更像个人。从结果上看,DAU很快超2000万,持续霸榜全球各地区应用第一名,是各界对其的认可。
2、中美AI竞赛/对抗。美意图打造单级AI,构建新时代的AI霸权。拜登政府在掌权最后一个月连续出台制裁,包括AI三级国家分类、更严苛的芯片管控。特朗普政府上台后推出星际之门,希望将算力留在美国本土。一套组合拳,本质上是意图通过算力分配权影响国际关系。DeepSeek通过算法架构优化降低对算力的过分依赖,同时开源打造生态缩小差距。中国大陆AI产业的供给瓶颈仍集中在晶圆制造环节,仅对比T的12万N3与S的3万N+2,其晶体管个数差距在12.7倍。
3、算力的总需求增长还远远没有结束,但影响算力需求结构以及新结构下的供给壁垒。普通老百姓才刚刚开始使用DeepSeek/豆包等AI模型去替代搜索和人工助理,算力需求的增长都不用计算,从产业阶段来看类似于2000年初刚开始用百度。但需求的结构会调整,从各种架构模型的预训练算力需求转向能够C端落地的推理需求,高投入做预训练的玩家已越来越集中。在推理需求中,能参与的玩家明显变多,短短几天宣布接入DeepSeek的芯片包括AMD、昇腾、海光等。
4、DeepSeek本地部署加速端侧AI推广落地。1.5B、7B、14B、32B、70B 是蒸馏后的小模型,671B是基础大模型,其中1.5B无需显卡,14B需RTX 4090,32B/70B以上模型需求多张A100。此外,借助AnythingLLM搭建DeepSeek本地知识库,可上传私有文档,并针对性问答整理。
5、DeepSeek的子弹仍在继续飞,在乎什么就会看到什么。这颗子弹的威力在于“中国的开源、低价、展示思维链的AI大模型做到了全球应用榜第一”。CSP云厂看到了低价与应用榜第一,纷纷接入,并加大投入。政客看到了中国,诋毁与制裁。OpenAI看到了开源,奥特曼在频繁反思“ClosedAI”。AMD、昇腾、海光等非NV芯片看到了算力市场的裂缝,靠DeepSeek小公司无力支撑的算力需求打开了市场。AI应用放弃基座模型自研,探索垂类市场。端侧硬件企业最喜欢开源的软件系统。PC在研究如何本地部署,及其效果。
大家看到了投资机会,因为DeepSeek“什么都没有”,所以他什么都有,都来“帮”他。
利好国产算力、国产CSP、端侧AI、AI应用
关于DeepSeek
三个核心技术原理(MoE、FP8混合精度、pipeline)和最突出的贡献点(用RL强化学习而不用SFT监督微调来做链式推理COT),这几天推出了国产卡的R1V3推理版,假期后还有国产卡的R1训练版。
硬件成本的下降会迅速被软件性能的提升消耗掉,这是IT产业的发展规律。现在基模型是一维到二维,以后二维到三维呢,三维到真实世界呢,当然这是长期叙事。
为了应对deepseek,OpenAI推出了o3-mini,其实就是变相把o1免费了。这对应用是好事。做了一个统计,从924以来,AI软件涨幅55%,AI硬件涨幅143%。由于低成本部署和推理,每个企业都可以自己部署一个32B本地蒸馏版R1,对AI软件应用是利好:
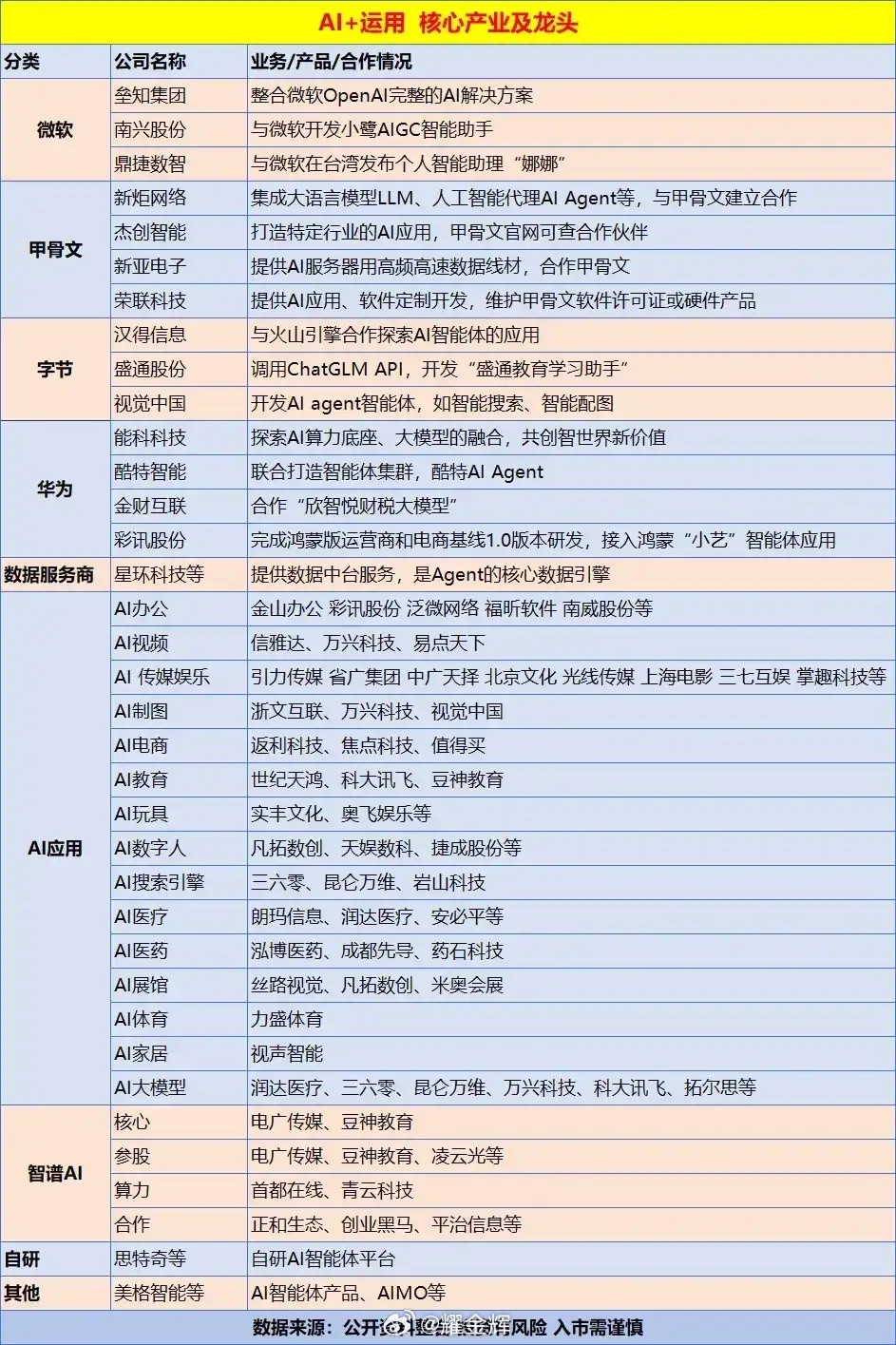
虹软科技、鼎捷数智、新致软件,合合信息,汉得信息,金山办公等。
DeepSeek带动“中国AI互联网产业”价格重估
金山云小米系算力主要承接者,DeepSeek利好端侧有望带来端云协同加速
承接小米系算力需求,端侧兴起有望带动端云协同需求提升
1)24年11月,金山云宣布,金山软件与小米签订新的框架协议,框架协议自2025-2027年的年度上限建议分别为23.10亿元、31.38亿元及40.35亿元。
2)24年底,据界面新闻,小米正搭建万卡集群。
3)24年底小米创始人雷军以千万年薪招揽DeepSeek核心开发者罗福莉。罗福莉参与了V3、R1核心模型的开发,理论上说基本掌握模型全栈技术,利好小米大模型的加强。
4)OpenAI于2月2日也宣布开发AI终端,2025年是AI终端的重要年份。小米端侧生态优势显著,叠加R1模型能通过蒸馏迅速提升端侧模型能力,利好小米硬件生态+AI发展,以及金山云算力需求,因为目前端侧也是【端云协同】。
中立属性特殊,对标海外Oracle
国内主要云厂商阿里、HW、腾讯均有自研的大模型,以支持自家产品矩阵。金山云目前仍然是较为中立的云服务提供商,类似海外Oracle,有望承接更多的模型训练算力。