R1-V,这个项目将DeepSeek R1的训练方法用在视觉语言模型上,效果非常amazing啊,2B模型在100个训练步骤内就超越了72B模型的OOD测试表现。整个训练仅耗时30分钟,成本不到3美元。
github.com/Deep-Agent/R1-V
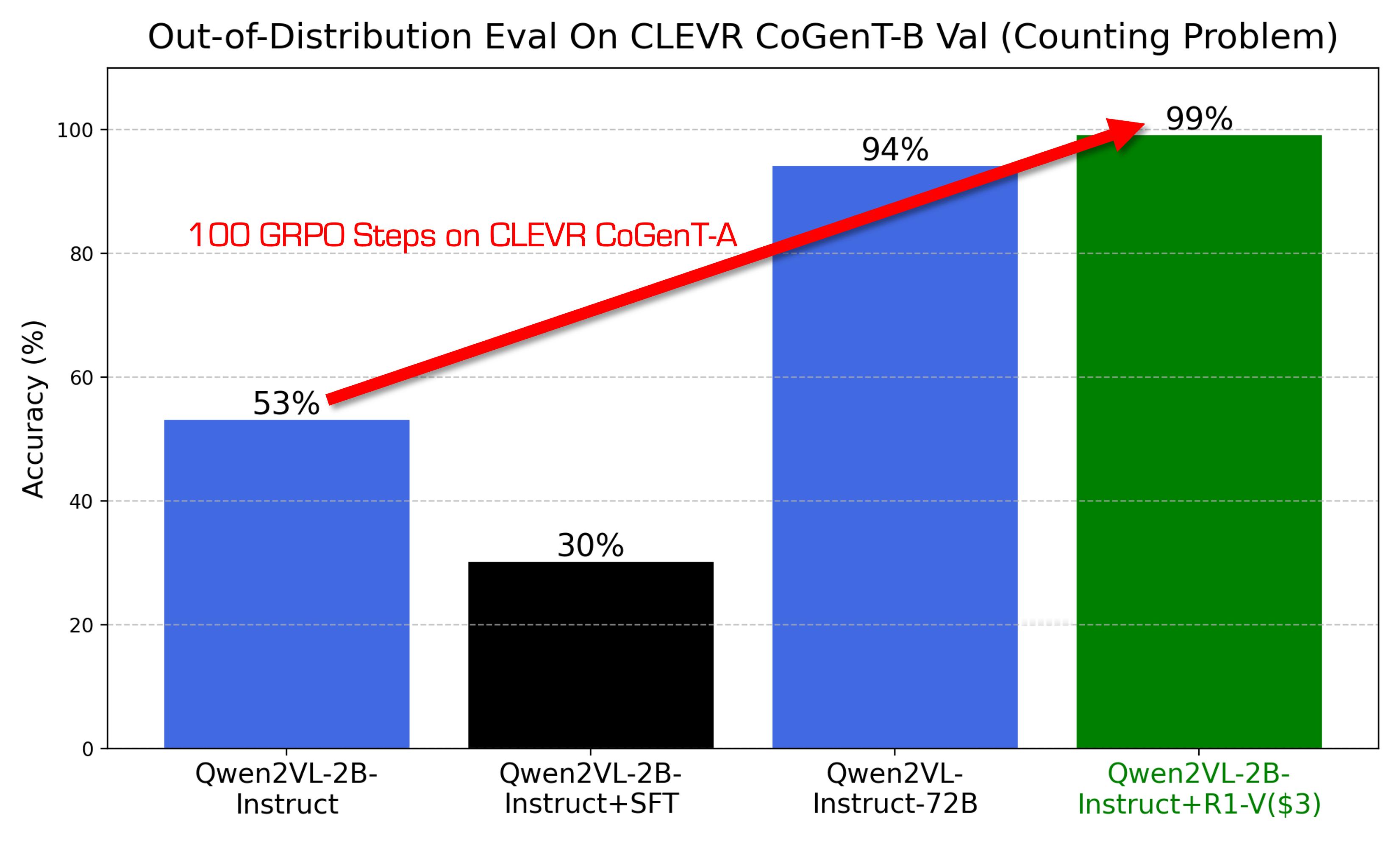
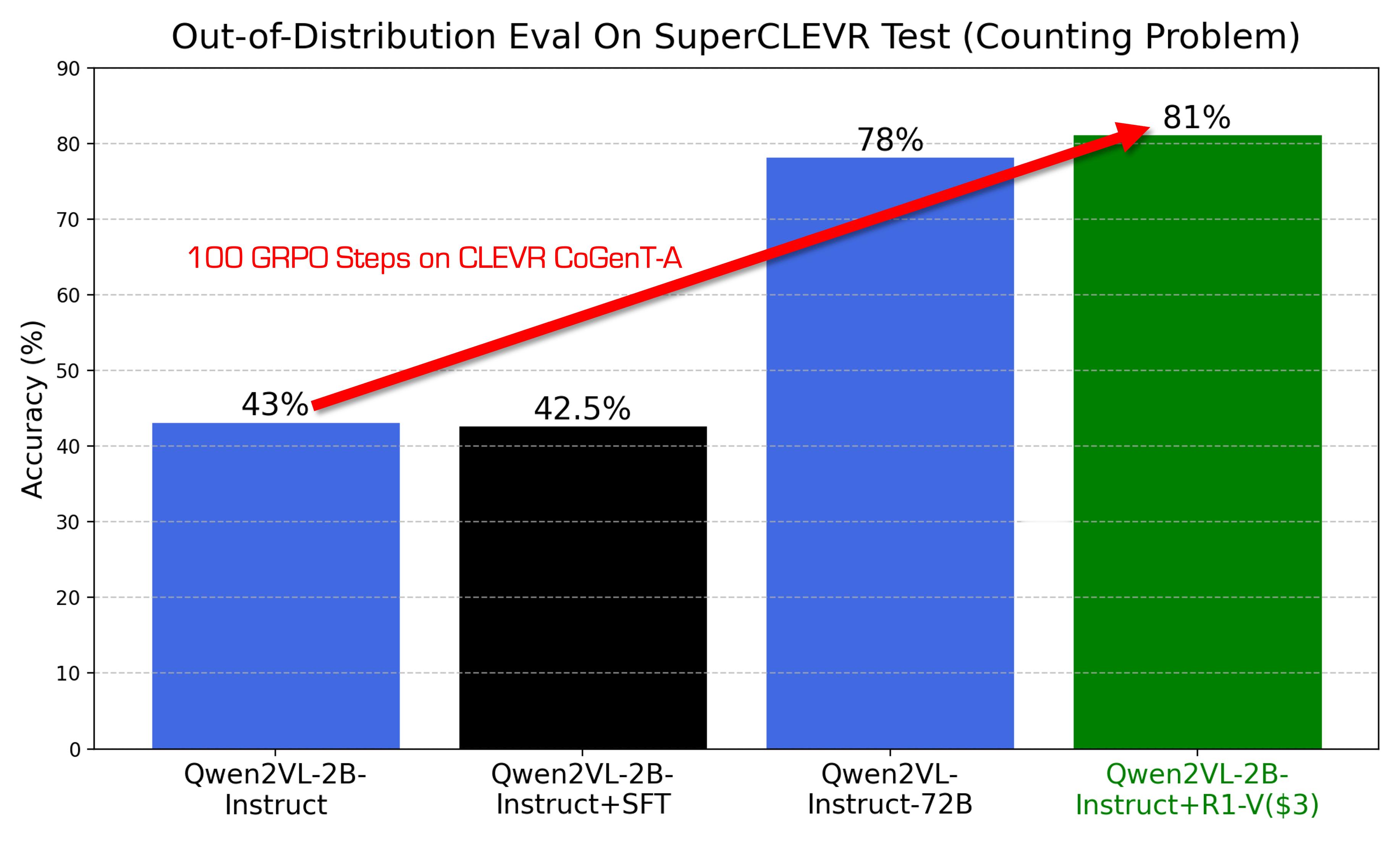
“我们首先揭示了,具有可验证奖励的强化学习(RLVR)在视觉语言模型(VLMs)上,在有效性和超出分布(OOD)鲁棒性方面均优于思维链监督微调(CoT-SFT)。
在我们的实验中,我们鼓励VLMs学习具有可泛化的视觉计数能力,而不是过度拟合训练集。
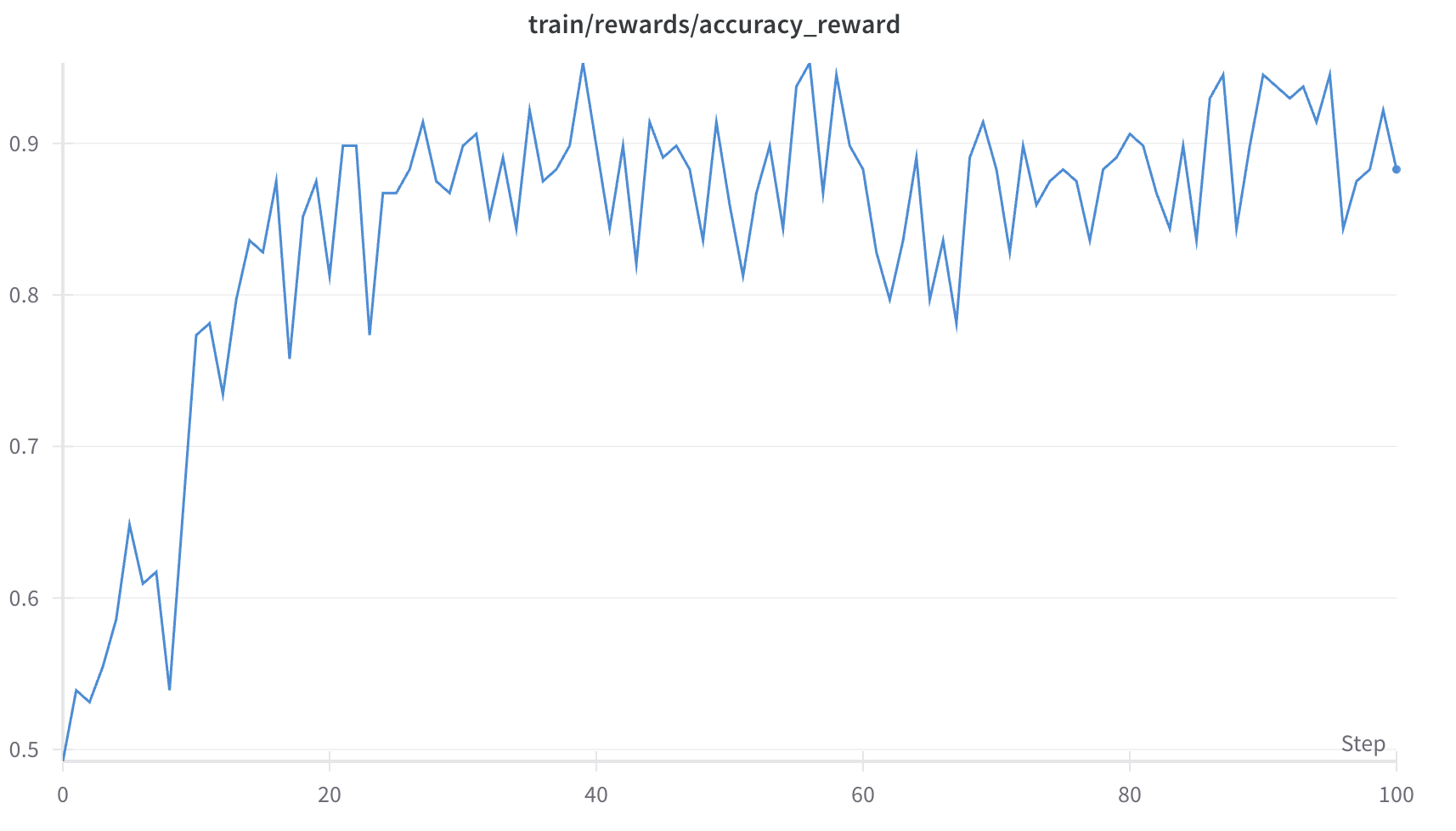
在仅经过100个训练步骤的OOD测试中,2B模型超越了72B模型。
训练在8个A100 GPU上进行,耗时30分钟,成本为2.62美元。”
项目的代码、模型、数据集、更多细节及所有开源资源将会在春节假期结束后共享。(现在数据集已经公开)