SemiAnalysis评估,DeepSeek是当今最好的开源实验室
根据SemiAnalysis最新评估,DeepSeek是当今最好的“开源权重”实验室,击败了 Meta 的 Llama、Mistral 和其他实验室。SemiAnalysis从以下三个方面进行评估:
1、团队与资源优势
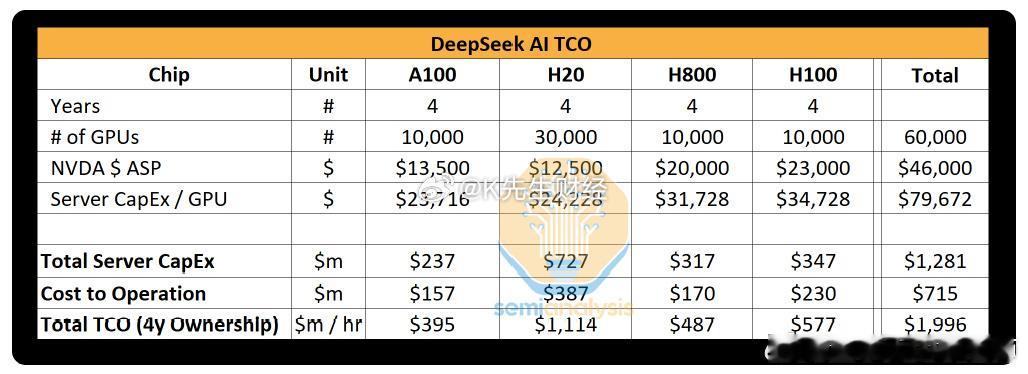
l由对冲基金 High-Flyer 分拆而来,能自筹资金。在 GPU 投资上超过 5 亿美元,拥有约 60,000 台 GPU(包括 10,000 台 A100、30,000 台 H20、10,000 台 H800 和 10,000 台 H100 ),总服务器资本支出近 13 亿美元,强大的资金和资源支持为研究和开发提供坚实基础。
l人才竞争力强:招聘聚焦能力和好奇心,不看重资历,定期在北大、浙大等顶尖高校举办招聘活动。为有潜力的应聘者提供超 130 万美元的高薪,远超中国大型科技公司,吸引了大量优秀人才,目前约有 150 名员工且发展迅速。
l自主运营数据中心:类似 Google,DeepSeek 大多自行运营数据中心,不依赖外部供应商。这为实验创造了更多空间,便于在整个技术堆栈中进行创新。
2、成本与性能优势
l成本效益突出:在模型训练和推理成本上表现优异。例如,DeepSeek-V3 模型价格极具竞争力,最低折扣价低至每 100 万输入令牌 0.14 美元、每 100 万输出令牌 0.28 美元 。虽然其 600 万美元训练成本说法不准确,但整体在实现相近功能时计算成本较低,领先于许多其他实验室。
l性能表现出色:DeepSeek-V3 在多个基准测试中成绩出色,如 MMLU(Pass88.5、AIME2024 达到 39.2、MATH-500 达到 90.2,超过了 Claude-3.5-Sonnet-1022、GPT-4o-0513 等模型 ,展示了强大的模型性能。
3、技术创新优势
l训练创新:DeepSeek V3 大规模运用多标记预测(MTP),提升训练时的模型性能,推理时可舍弃;采用混合专家(MoE)模型,并通过 “门控网络” 高效路由 token,提高训练效率、降低推理成本;在训练中考虑 FP8 准确度,紧跟前沿技术。
l推理创新:R1 模型借助强大的基础模型(v3)和强化学习(RL),在推理能力上表现出色;其关键创新多头潜在注意力(MLA),相比标准注意力机制,使每个查询所需的 KV 缓存量减少约 93.3%,降低推理成本,引起众多美国领先实验室关注。
苹果公司CEO蒂姆·库克(Tim Cook)在周四的财报电话会议上表示,DeepSeek的AI模型代表了“能够提升效率的创新”。OpenAI创始人山姆·奥特曼近日也连续发文评价DeepSeek模型。他表示DeepSeek的R1是一款令人印象深刻的模型,尤其是在价格方面。(创业邦)