DeepSeek除夕再发新模型,文生图测试优于OpenAI
1月28日,DeepSeek发布开源多模态模型Janus-Pro,其中70亿参数版本的Janus-Pro-7B模型在使用文本提示的图像生成排行榜中优于OpenAI的 DALL-E 3和Stability AI的Stable Diffusion。
[允悲]而且依然开源。15亿和70亿的参数量,意味着这两个模型具备在消费级电脑上本地运行的潜力。与R1一样,Janus Pro采用MIT许可证,在商用方面没有限制。
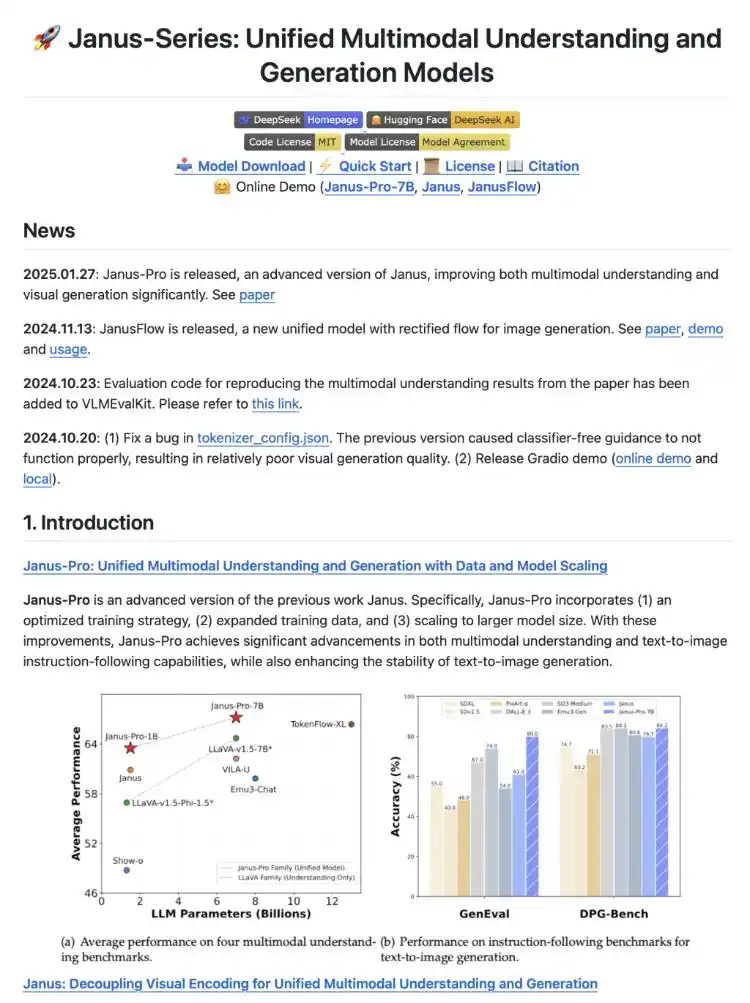
据DeepSeek介绍,Janus-Pro是一个新颖的自回归框架,统一了多模态理解和生成。通过将视觉编码分离为“理解”和“生成”两条路径,同时仍采用单一的Transformer架构进行处理,解决了以往方法的局限性。这种分离不仅缓解了视觉编码器在理解和生成中的角色冲突,还提升了框架的灵活性。
在视觉生成方面,Janus-Pro通过添加7200万张高质量合成图像,使得在统一预训练阶段真实数据与合成数据的比例达到1:1,实现“更具视觉吸引力和稳定性的图像输出”。在多模态理解的训练数据方面,新模型参考了DeepSeek VL2并增加了大约9000万个样本。
作为一个多模态模型,Janus-Pro不仅可以“文生图”,同样也能对图片进行描述,识别地标景点(例如杭州的西湖),识别图像中的文字,并能对图片中的知识(例如下图中的“猫和老鼠”蛋糕)进行介绍。