深入浅出Transformer架构与PyTorch实现
本文首先介绍了Transformer模型的背景,包括它的创新点和为什么需要它。然后详细阐述了Transformer的关键组件,包括自注意力机制、位置编码、编码器和解码器层的结构,以及如何通过多头注意力来提高模型的性能。接着,通过代码示例展示了如何使用PyTorch来实现Transformer模型的各个部分,包括多头注意力、前馈神经网络、位置编码以及整个模型的编码器和解码器。最后,提供了如何训练Transformer模型的指导,包括数据预处理、创建数据加载器、定义损失函数和学习率调度器,以及如何进行实际的训练循环。此外,文章还提供了一些学习和进一步阅读的资源。
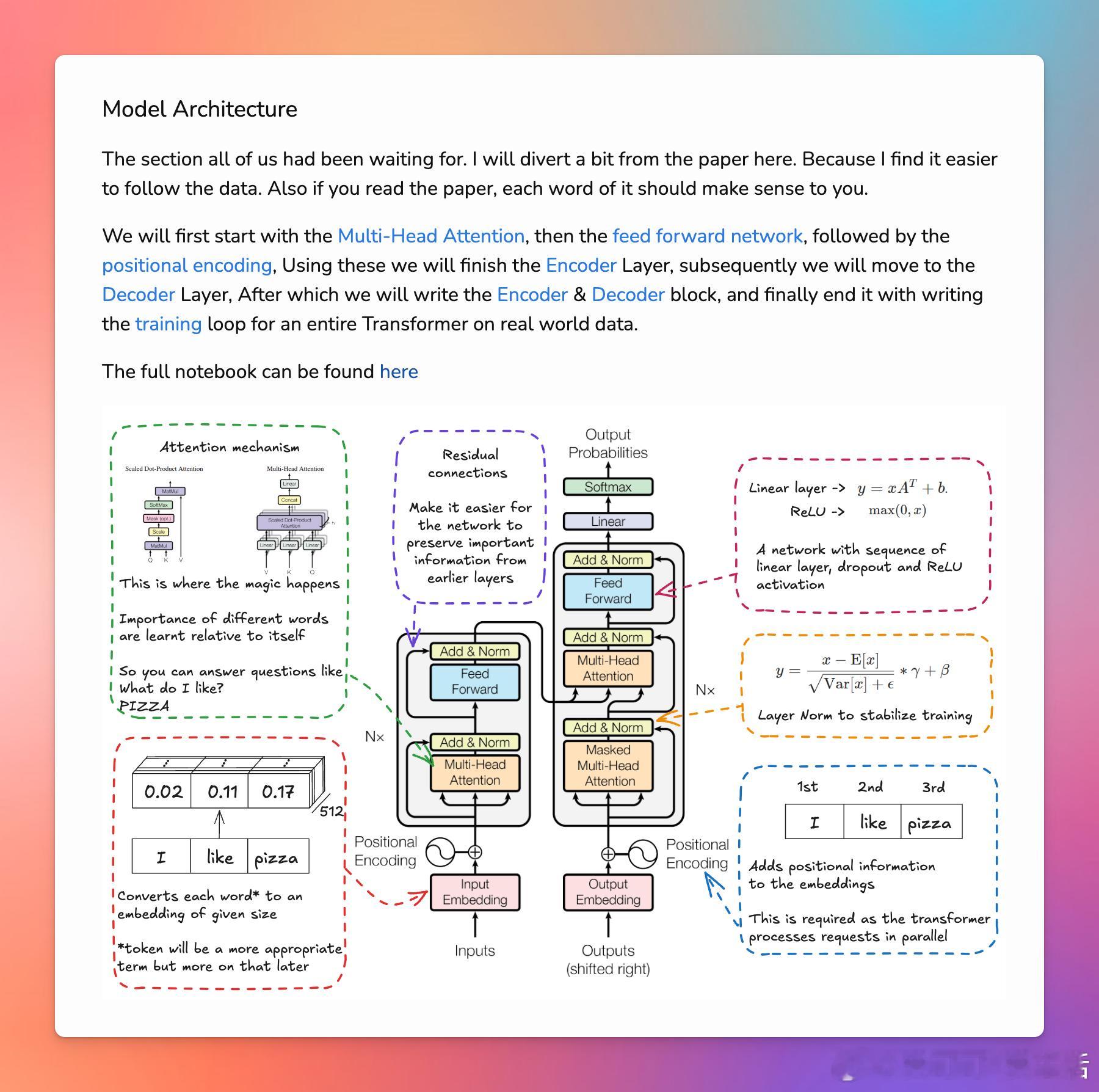
1. Transformer模型通过自注意力机制能够处理序列数据,并且能够并行处理所有序列位置的信息,这使得它在处理长序列时比以往的模型(如RNN和LSTM)更加高效。
2. 位置编码对于Transformer模型来说至关重要,因为它提供了序列中各个元素的位置信息,这有助于模型理解序列的顺序。
3. Transformer的编码器和解码器结构采用了多头注意力机制,这不仅提高了模型的并行处理能力,还增强了其捕捉序列内不同位置关系的能力。
4. 在实现Transformer时,需要注意的细节包括正确的张量形状操作、掩码的使用以及如何处理训练中的梯度裁剪。
5. 为了确保Transformer模型的良好收敛,需要仔细设计训练循环,包括使用标签平滑技术来改善模型的泛化能力。
6. 强调了实践中的一些实用技巧,如使用学习率调度器来逐渐减少学习率,以及如何准备和加载数据以供模型训练使用。
'Transformers Laid Out | Pramod’s Blog - A detailed guide to understanding and implementing Transformers from scratch'
GitHub: github.com/goyalpramod/transformer_from_scratch