大自然擅长设计蛋白质。科学家甚至更擅长,人工智能(AI)有望帮助人类多次实现定向蛋白质进化。
来自哈佛医学院、麻省理工学院等多家顶尖学术机构联合组成的研究团队在这一领域带来了新的突破,他们开发了一个人工智能(AI)平台EVOLVEpro,将蛋白质设计精准度推向新高度。
EVOLVEpro平台基于少样本主动学习框架,结合蛋白质语言模型(PLMs)和回归模型,无需依赖结构信息、专家经验或其他先验数据,仅通过蛋白质序列进行高效优化,实现了快速预测高活性蛋白突变体。
更重要的是,EVOLVEpro在RNA生产、基因编辑及抗体结合等应用中展示出了优越的性能,能使所需特性提升100倍。研究结果显示,平台在癌细胞中大幅优化了基因编辑工具的活性,同时也改良了抗体的结合能力和表达水平。
此外,针对新型脂质纳米颗粒(LNP)的优化实验表明,EVOLVEpro几乎完全消除了基因编辑工具的脱靶效应,为精准医疗的应用提供了坚实基础。
相关研究论文以“RapidinsilicodirectedevolutionbyaproteinlanguagemodelwithEVOLVEpro”为题,已发表在权威科学期刊Science上。

这种创新方法为跨领域应用提供了全新可能性,从抗体优化到基因编辑工具改良,都展现出了优异性能。
攻克蛋白质优化与基因编辑难题
在生物医学领域,如何优化蛋白质以提高其特定活性始终是极具挑战的任务。这种优化对于抗体研发、基因编辑工具改良以及疫苗设计等领域至关重要。
然而,传统技术如深度突变扫描(DMS)或定向进化,往往需要大量实验验证,不仅耗时费力,还容易陷入局部最优解。
基因编辑技术也面临类似难题。例如,CRISPR-Cas9技术尽管显著推动了基因编辑的进展,却在精准性和递送效率上面临瓶颈。一方面,脱靶效应使得编辑可能产生非预期突变,带来副作用风险;另一方面,现有的mRNA递送系统在目标细胞中表现出较低的稳定性,限制了基因治疗的效果。
近年来,深度学习技术的发展为蛋白质优化领域注入了新动能。蛋白质语言模型通过大规模序列数据库训练,能够捕捉蛋白质序列与其结构和功能之间的复杂关系。
然而,这些模型在优化蛋白质活性时表现有限,在优化蛋白质活性时,它们难以精准捕捉复杂适应度景观,特别是在涉及蛋白质非结合特征的任务中。
为突破这一困境,研究团队开发了EVOLVEpro。该平台结合深度学习与主动学习策略,不仅降低了对实验数据的依赖,还通过智能选择最优突变体进行实验验证,大幅减少了实验次数。
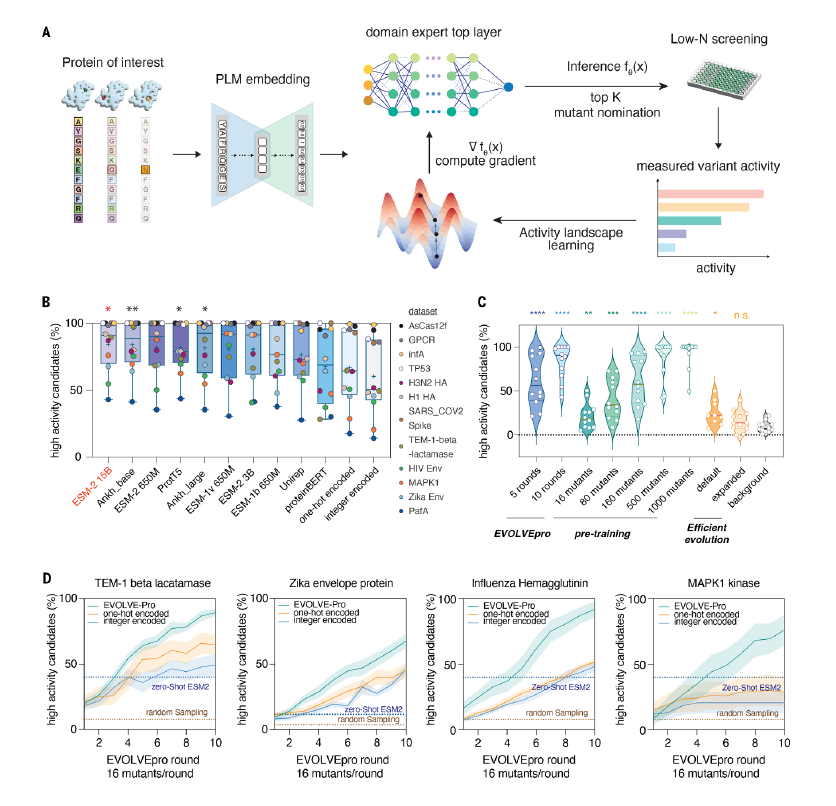
图|开发用于蛋白质语言模型引导工程的EVOLVEpro并进行基准测试
与传统的定向进化和现有AI方法相比,EVOLVEpro显现出三大优势:
突破数据依赖:无需蛋白质结构信息、专家知识或复杂实验数据,完全基于少量蛋白质序列实现高效优化。
高效主动学习:通过主动学习框架,EVOLVEpro能够智能选择最优突变体进行实验验证,大幅减少实验次数。
跨领域应用潜力:在mRNA递送、基因编辑工具改良等多个领域表现出卓越的性能。
研究团队通过12个深度突变扫描数据集,优化了EVOLVEpro参数,采用网格搜索选择最佳蛋白质语言模型(如ESM2),并测试了不同回归模型(如随机森林、k近邻回归器)对性能的影响。
全方位突破:从抗体优化到基因编辑工具
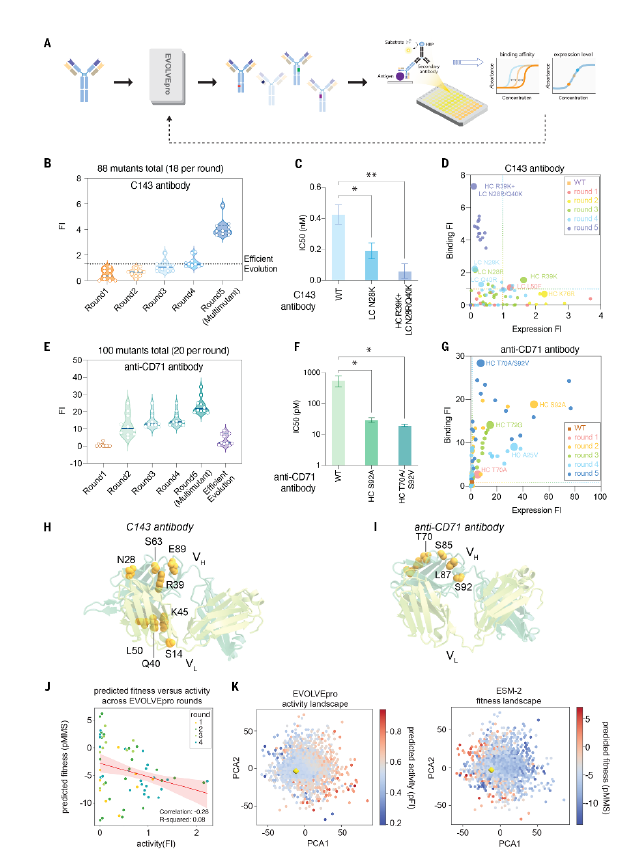
为了验证EVOLVEpro的实际性能,研究团队以C143抗体和抗人转铁蛋白受体的aCD71抗体为目标,评估了它在抗体结合能力优化中的表现。
研究结果显示,经过四轮优化后,C143抗体的最佳轻链突变体N28R显著提升了结合亲和力,其结合半数抑制浓度(IC50)降至60pM,多突变体结合亲和力提高至野生型的35倍。
图|利用EVOLVEpro对高活性微型CRISPR核酸酶进行改造
在针对aCD71抗体优化实验中,则发现最佳重链突变体S92A结合IC50达到29pM,进一步设计的多突变体结合IC50效率达到19pM,同时提升了抗体的表达水平和亲和力。
而在与多种蛋白质语言模型比较中,ESM-215B参数模型作为EVOLVEpro的潜在空间模型,在多数数据集上表现优于其他模型,返回的高活性突变体比例最高,且只有少数蛋白质语言模型的预测准确性明显高于独热编码,突出了基础层模型对EVOLVEpro性能的关键重要性。
在基因编辑工具方面,研究团队将目标锁定在微型CRISPR核酸酶PsaCas12f和Bxb1整合酶的活性改良上。通过四轮单突变体优化,PsaCas12f在多个靶点的插入缺失效率显著提高。
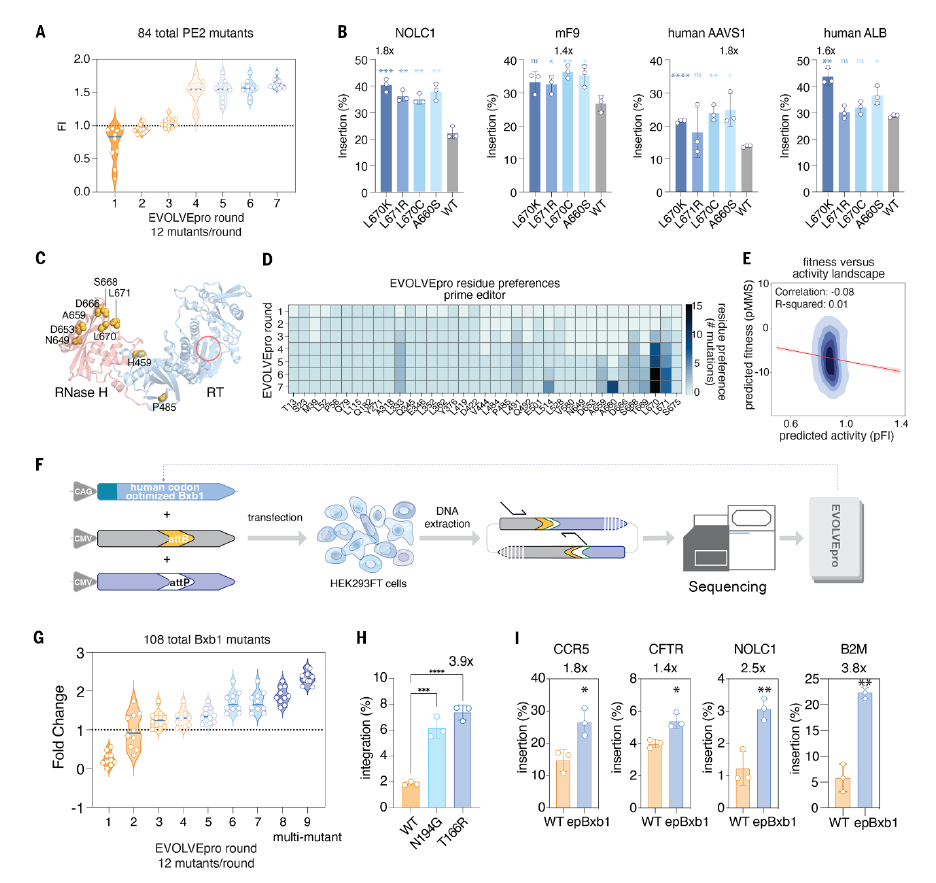
图|用EVOLVEpro对primeeditor进行进化
研究发现,最佳变体PsaCas12fK333V在RNF2基因位点的插入缺失效率提高至40%,进一步组合的多突变体则将效率提升至约50%。组合多突变体的平均编辑活性提高2.2至44倍,相较其他Cas12f效应子表现优异。
类似地,在Bxb1整合酶进化实验中,经过多轮进化得到的突变体活性提升至野生型的2.6倍以上,在基因组中基因货物的整合效率提高多达4倍,为基因组编辑和大基因货物整合提供了更强的工具。
此外,针对mRNA生产中的T7RNA聚合酶,EVOLVEpro通过多轮进化显著提升T7RNA聚合酶性能。
在T7RNA聚合酶进化实验中,经过四轮优化,最佳突变体E643G产生的荧光素酶mRNA较野生型的翻译效率提升34倍,免疫原性比野生型降低98%。
在临床相关的IVT环境下,与野生型和之前工程改造的突变体比较,优化版epT7酶生产的mRNA在体外转录实验中,翻译效率较野生型高120倍,免疫原性低256倍。
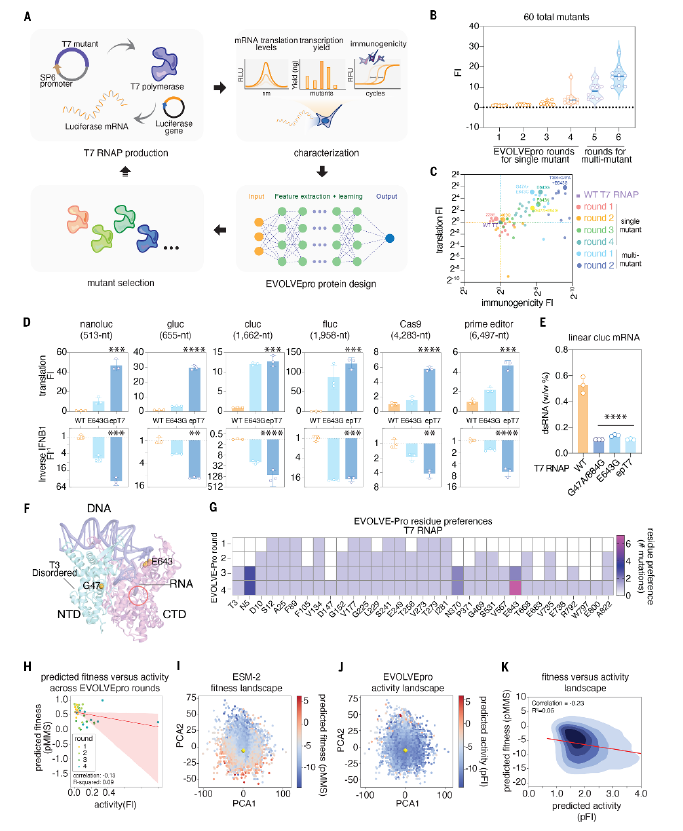
图|为高产且低免疫原性的mRNA生产对RNA聚合酶进行工程改造
此外,研究人员还进行了多维度性能验证与机制解析,不仅验证了EVOLVEpro的优越性能,也揭示了突变提升活性的机制。
通过AlphaFold3对不同蛋白质的结构预测以及对模型关注残基的分析,研究团队发现,PsaCas12f中的K333V突变通过稳定结构和调节模板结合增强了活性,而T7RNA聚合酶中的E643G突变则显著减少了免疫反应。
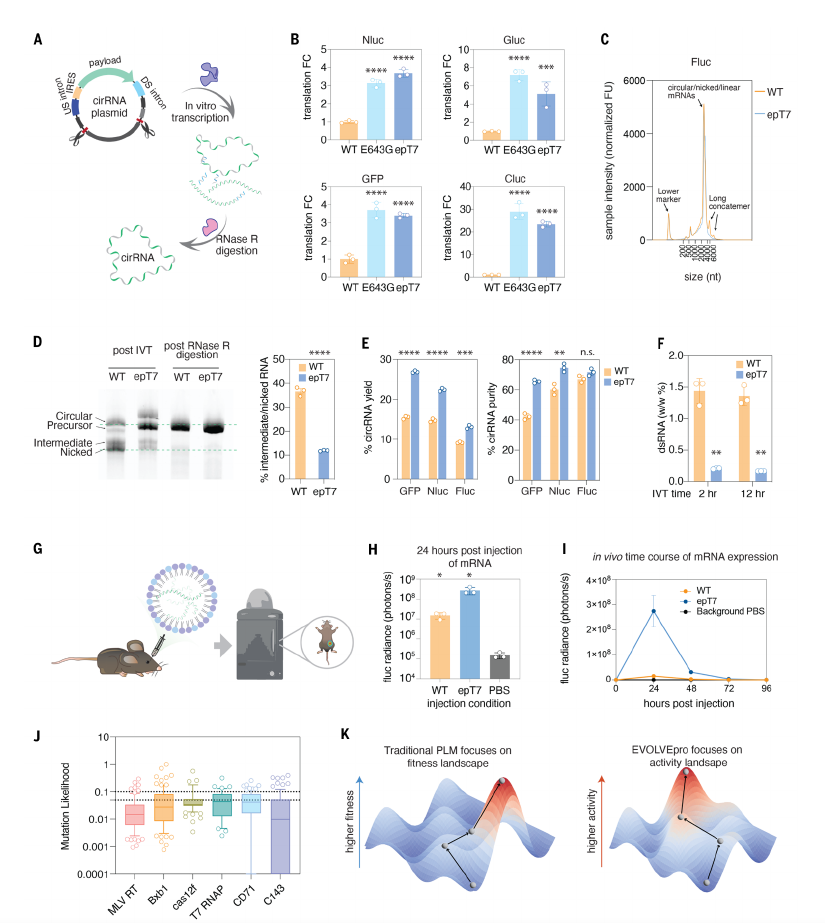
图|epT7在环状RNA生产及体内生物发光方面的应用
不足与展望
尽管EVOLVEpro展现了极大的潜力,但研究团队也指出了一些存在的挑战。
EVOLVEpro在一定程度上克服了蛋白质语言模型的一些问题,但蛋白质语言模型固有的局限性依然存在影响。例如,蛋白质语言模型是通过学习掩码序列重建任务训练的,自然序列不一定选择最优蛋白质活性,导致其学习的活性景观与实际蛋白质活性景观常不相关,即使增加蛋白质语言模型的参数也未必能更好地预测蛋白质活性及其他下游任务。
其次,在一些蛋白质的研究中,如不同蛋白质的适应度与活性之间的关系虽然通过分析有了一定的了解,但整体上这种关系还不够明确和稳定,不同蛋白质呈现出不同的相关性情况,给准确预测和优化带来一定难度。
为此,研究团队计划,随着自回归蛋白质语言模型或下一代表示模型的出现,将继续改进EVOLVEpro模型,利用其模块化设计将新的模型优势整合进来,进一步提高模型的性能和预测准确性。
他们表示,将把EVOLVEpro应用到更多类型的蛋白质和生物医学相关领域,进一步探索其在不同蛋白质特性优化、不同应用场景下的表现,深入研究蛋白质活性提升的各种机制以及不同突变之间的复杂相互作用,以更好地实现蛋白质工程的目标,满足生物医学等领域对高性能蛋白质的需求。
研究人员还将尝试基于生物物理的模型与EVOLVEpro建立的回归顶层方法相结合,进一步提高预测准确性,并实现对功能获得性突变体的更快速准确识别,从而更高效地优化蛋白质的各种特性。
EVOLVEpro的问世为蛋白质优化与基因编辑工具的研发提供了全新视角。从抗体设计到精准基因编辑,再到高效mRNA生产,EVOLVEpro通过AI驱动的高效突变体筛选,正在重新定义生物医学的研发效率与可能性。
随着技术的持续迭代与优化,未来生命科学或将迎来更多突破性发现,为癌症治疗、基因疗法以及新药研发提供新的可能。