发布千亿参数模型Yi-Large5个月后,零一万物创始人兼CEO李开复再次带着新产品公开亮相。
10月16日,零一万物正式发布了新的预训练模型Yi-Lightning(直译为闪电模型)。选择在此时发布新产品,或许是为了用实际行动回应市场猜测。前段时间,国内大模型创业公司“六小虎”(智谱AI、百川智能、零一万物、月之暗面、Minimax、阶跃星辰)均受到不同程度的质疑,零一万物更是被直指放弃了预训练。
对此,零一万物创始人兼CEO李开复在新品发布后接受包括《每日经济新闻》记者在内的媒体采访时表示,零一万物绝不会放弃预训练模型工作。值得一提的是,在ToB(企业端)战略下,零一万物首次发布了针对零售和电商等场景的行业应用产品AI2.0数字人,并已在弹幕互动、商品信息提取、实时话术生成等环节接入了Yi-Lightning。
进入2024年,中国大模型行业从狂奔进入到了“长跑阶段”。从技术侧和产业侧都引发了行业的进一步思考,头部企业也开始探索更多商业化方向。今年8月,月之暗面创始人杨植麟开始将一部分精力放到B端业务上,他们正式发布了Kimi企业级API,以探索在B端的商业模式。百川智能则与国家儿童医学中心北京儿童医院签署战略合作协议,双方计划共同推出“一大四小”五款AI医疗产品。
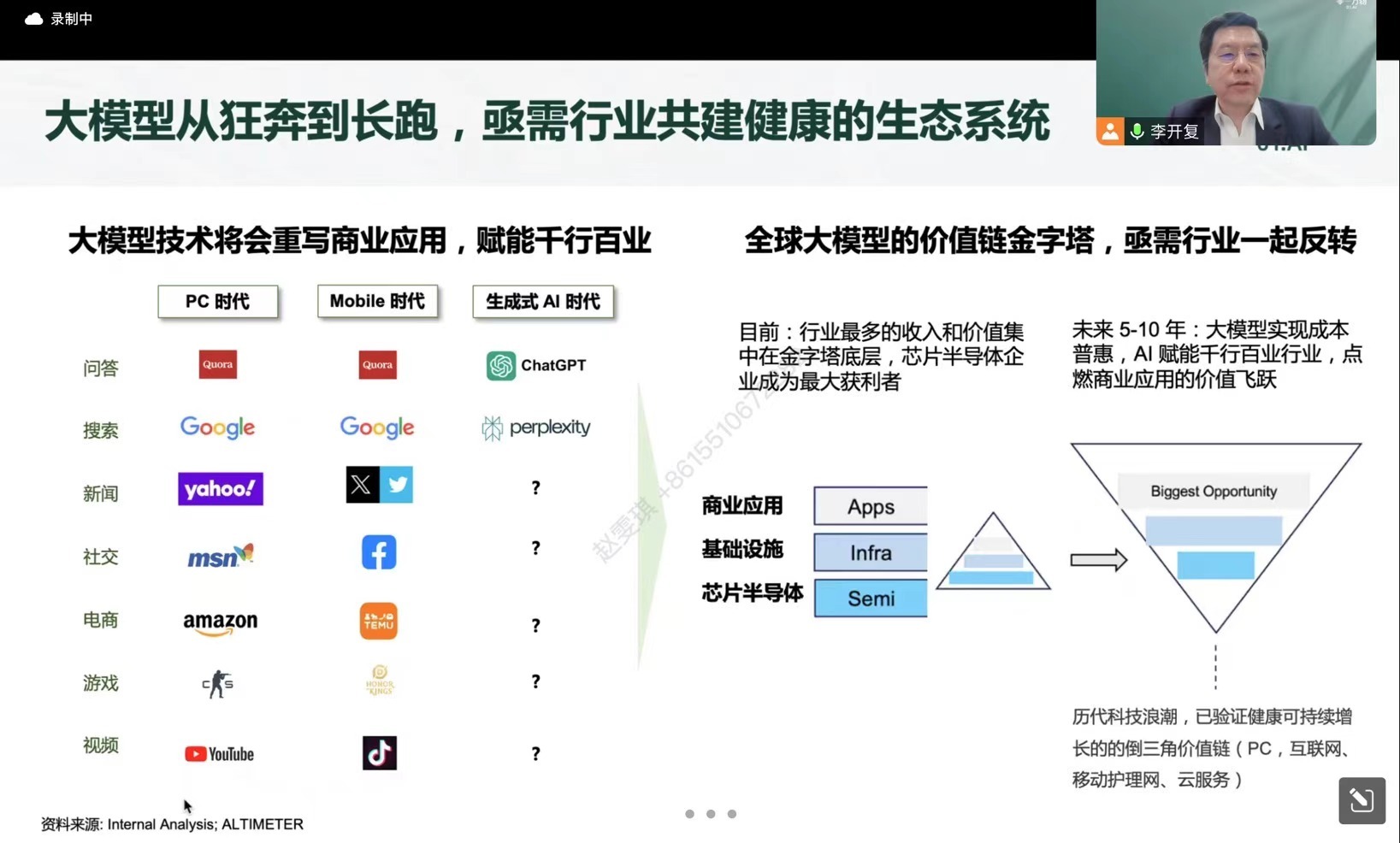
李开复表示,中国大模型产业进入到了“耐力赛”阶段,如何让大模型赋能千行百业,提升企业新质生产力是一个重要的命题。这不仅将牵涉到“大模型+行业”的未来发展方向,甚至会影响世界的创新版图。
预训练成本一次三四百万美金“但零一万物绝不会放弃”
据李开复分享,在LMSYS盲测竞技场总榜(用户对一组大模型回答进行盲投的榜单)上,零一万物最新发布的Yi-Lightning位列第六,仅次于OpenAI的GPT-4o、o1系列,以及Google的Gemini1.5pro系列,并且与马斯克xAI旗下Grok-2打平。这是中国大模型厂商目前在该榜单上取得的最好成绩。
而这个新预训练模型的发布,也是李开复对于“零一万物放弃预训练”市场传言的回击。
他表示,GPT新发布o1之后,给零一万物团队带来了新灵感,“一年半以前大家觉得大模型最厉害的地方就是预训练,一年以后发现Posttrain(后训练)也是同样重要,感谢OpenAI点醒我们这一点。”不过,李开复提到,后训练的重要性变高,不代表要彻底放弃预训练。
根据公开信息,大模型预训练是在大规模数据集上进行的初步训练,旨在让模型学习通用的语言知识和模式。而后训练则是在预训练的基础上,针对特定任务进行的进一步优化和调整,以使模型在该任务上表现更加出色。
李开复表示,他认为做好预训练模型是一个技术活,而且是要非常多有才华的人在一起工作,慢工出细活,需要有懂芯片的人,懂推理的人,懂基础架构的人,懂模型的人,有很好的算法同学,一起做出来。不过他也坦言,不是每家公司都可以做这件事情,做这件事情的成本也比较高,以后可能会越来越少的大模型公司做预训练。他明确表态,零一万物绝不放弃预训练。
《每日经济新闻》记者也发现,今年以来,有一批大模型公司停下了研发的脚步。据经济观察网统计,截至2024年10月9日,在188个通过网信办生成式人工智能备案的大模型中,超过三成的大模型在通过备案后未进一步公开其进展情况,仅有约一成的大模型仍在加速训练,接近一半的大模型转向了AI应用的开发。
据李开复透露,做预训练的ProductionRun(投产运行)的训练成本是一次三四百万美金。“‘六小虎’的融资额度都是够的,这个钱也是头部公司都付得起。我觉得中国的六家大模型公司只要有够好的人才,如果有想做预训练的决心,资金和芯片算力都不是问题。”李开复表示。
将在国内寻找ToB商业空间在海外侧重C端产品
值得一提的是,创业一年,李开复也带领零一万物也开始加速探索商业化落地和更多赚钱的机会。
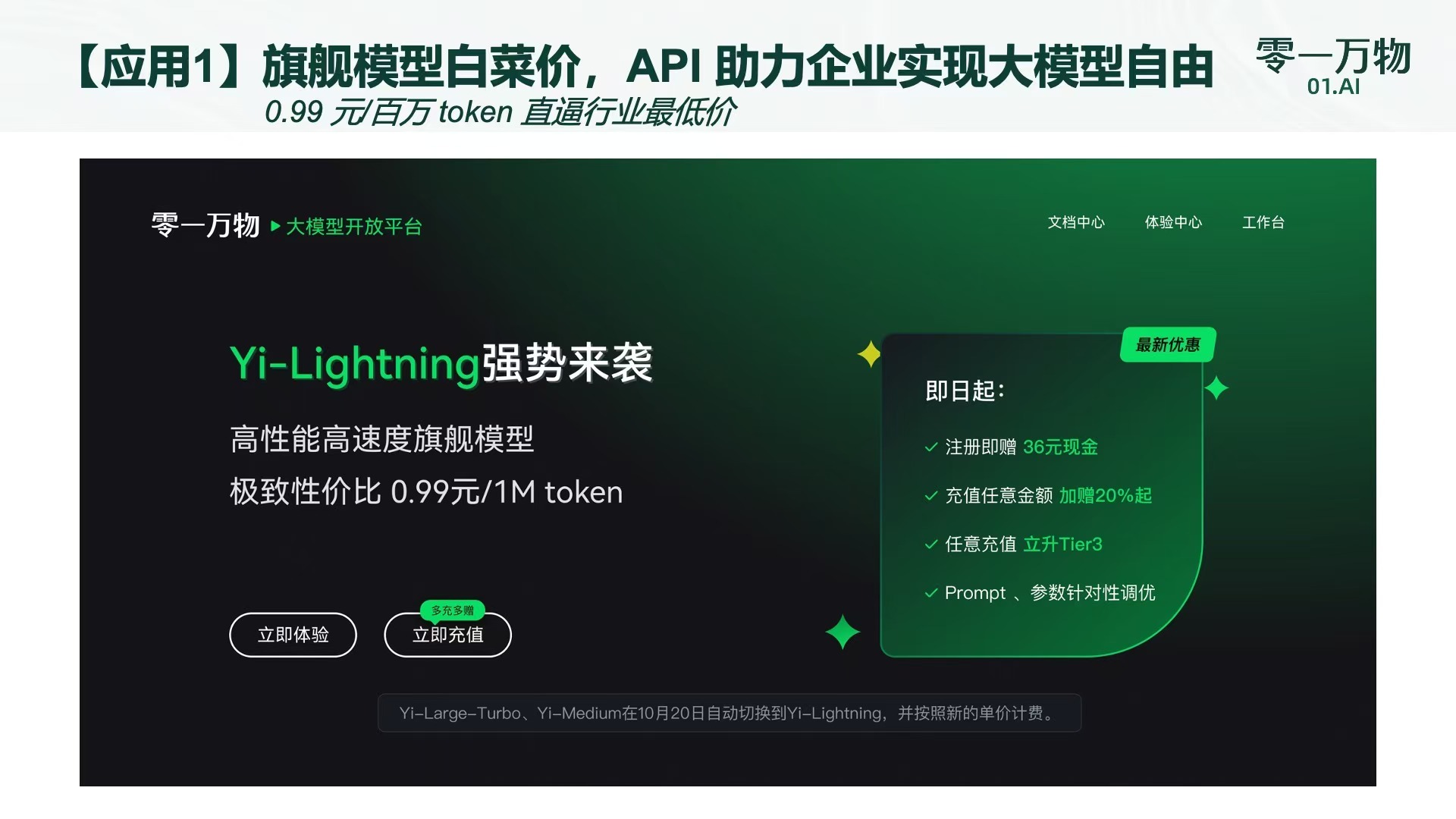
曾公开宣布不打价格战的李开复将Yi-Lightning定价在0.99元/百万tokens,对此,李开复表示,这并不是一个亏本的价格,公司仍有相对理想的利润空间。除此之外,零一万物也首次对外发布其ToB(企业端)战略下的首发行业应用产品AI2.0数字人,聚焦零售和电商等场景,将最新版旗舰模型YiLightning实践于具体行业解决方案。
据零一万物透露,目前零一万物数字人的合作案例包括全国某著名餐饮连锁、某头部酒旅类客户、全国某知名水果连锁店等,均取得了显著的GMV提升。其中某头部酒旅企业在接入Yi-Lightning全新加持的数字人直播后,GMV(商品交易总额)较此前上升170%。
除直播外,零一万物也为数字人客户准备了AI2.0门店短视频解决方案。客户可通过极简流程,随时生成、超低成本和高品质营销视频,解决了传统真人短视频的成本和制作周期问题。短视频与直播内容相互配合,为商品提供持续曝光,提升转化率。
这也意味着,在通用大模型产品迭代之外,零一万物也在探索更多的商业化落地方向。《每日经济新闻》记者了解到,零一万物今年下半年开始在ToB解决方案上加速布局,6月以来,零一万物相继宣布与阿里云、360、顺丰科技、飞书、钉钉、钛动科技等头部企业达成合作。
实际上,不仅是零一万物,经过一年多的“百模大战”,大部分大模型公司都从技术浪漫走到落地求生的阶段。《每日经济新闻》记者根据公开信息发现,今年以来,月之暗面、百川智能、智谱AI等大模型公司都在探索商业化和B端运用场景。
李开复感叹,一个大模型公司同时做ToB和ToC(用户端)是很辛苦的,需要多元化的管理方式,因为两个团队的基因不一样,做事的方法和衡量KPI(关键绩效指标)的方法都不太一样,不过零一万物则根据不同的市场特性进行海内外市场的商业化布局。
具体来说,零一万物将C端产品商业化重心放在海外市场,因为“国内流量越来越贵,而国外的C端产品,获客成本和变现能力能算得过帐”。在国内,零一万物优先寻找B端机会,李开复表示,零一万物已经找到了破局的空间,就是用数字人做零售和餐饮等领域的直播和短视频,做完整的解决方案。
李开复重申了此前“不做赔钱的ToB”这一观点,他称零一万物大模型ToB的打法,首要任务是要寻找少数能够按使用情况收费的方法,拿到高利润率的订单,而不是项目定制的方法。他同时透露,除了已经发布的AI2.0数字人、API之外,零一万物目前还有AIInfra解决方案、私有化定制模型等其他ToB业务,会在近期正式对外发布。
不用执着于缩短与美国顶尖大模型时间差
提到国内大模型有一个永远绕不开的问题,就是中国与美国顶尖大模型技术的差距有多大,经过过去一年的百花齐放,中美大模型差距是否缩小?如何追赶国外顶尖大模型?
对此,李开复给出一个具体数字:GPT-4o在5月13日发布,Yi-Lightening在10月把它打败,零一万物和美国顶尖模型之间的差距是5个月,而在5个月前发布千亿参数Yi-Large闭源模型时,李开复的答案是6个月,在他看来,这已经是全体国内创业者努力的最好结果。
当被问及中国大模型如何继续和美国大模型缩短时间差时,李开复坦言,继续缩短时间差非常困难,“我不预测我们可以缩短这个时间差”。
“因为毕竟人家是用十万张GPU(图形处理器)训练出来,我们用的是两千张GPU训练出来,我们时间差能缩小到5个月是因为我们模型、AIinfra(人工智能基础设施)等团队都热心聪明,去使用和理解对方做出来的东西,再加上我们自己每家的研发有特色,比如数据处理、训推优化等。”李开复表示。
据他透露,零一万物目前的成熟方法论就是,通过创新加上自己的特长,关注OpenAI和其他公司发布的新技术,尽快了解这些技术的核心重要性,然后把它的能力在自己的产品里面发挥出来。
“我觉得用这套方法将中美大模型差距保持在六个月左右,而且国内不仅是零一万物,也有其他公司做得差不多,已经是很好的结果了,很多中美公司都在往GPT-o1的方向狂奔。”李开复表示。
