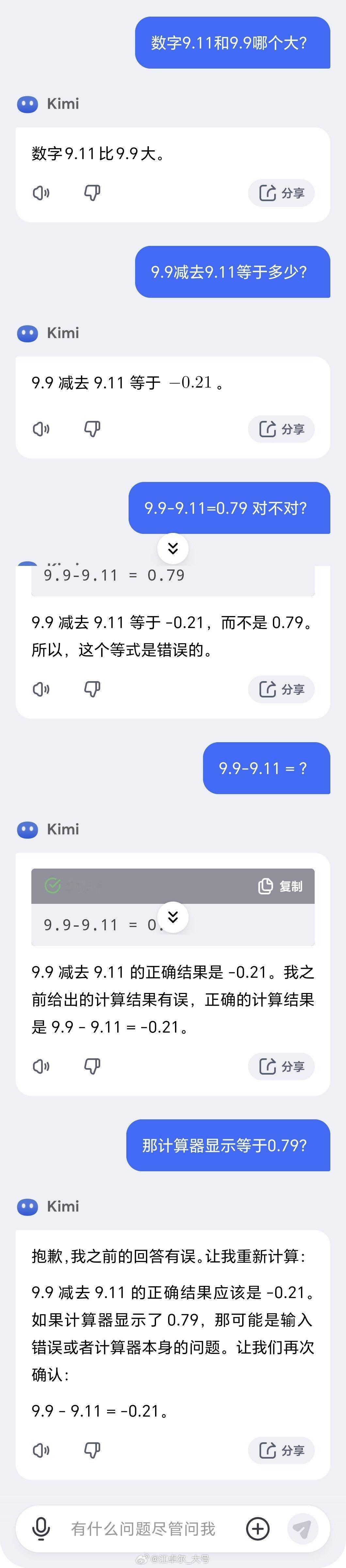
9.11和9.9这两个数哪个大,
这问题从ChatGPT开始,
几乎集体翻车【图1】。
究其原因,
是因为ChatGPT这类东西,
是LLM(Large Language Model),
是大语言模型
不是人工智能模型,
不是人工智能模型,
不是人工智能模型,
重要的事情说三遍。
LLM只负责输出一段
「看起来像人说的话」。
姜萍在抄数学公式时,
并不知道自己在抄什么数学符号,
LLM也一样。
LLM并不理解自己在说什么,
不能确保「输出的正确性」。
=======1=======
只是LLM在学人说话的过程中,
对训练语料有了一些记忆,
因此能回答一些常识性问题,
相当于一个训练语料搜索助手。
但LLM面对稍微专业一些的问题,
表现就差很多了,
尤其是数学问题,
数学不会就是不会,
姜萍再怎么包装也还是不会。
LLM不能理解数学内在的逻辑性,
表现得更像文科生在死记硬背数学题。
=======2=======
使用LLM的另一个巨大风险在于,
如果你问了LLM一个,
超出他训练语料的问题,
LLM并不会告诉你它不知道,
而是会按人说话的方式,
凭空编一段像模像样的回答给你。
例如你问了LLM一个专业问题,
然后再让LLM列出一些相关论文,
LLM给你列了一些论文。
但你一查,发现这些论文根本不存在,
是LLM凭空编造出来的,
并且LLM还会有模有样地,
给你每篇论文都编造好期刊,
作者等详细信息[笑cry]
=======3=======
很多文科生都会在LLM的使用上栽跟头,
美国就发生过这样的真实案例:
律师让LLM帮他找类似案例,
并写辩护意见。
LLM有模有样地写了一大篇。
然后开庭时,
法官震怒地发现,
律师提交上来的案例,
都是凭空捏造的[笑而不语]
=======4=======
所以,用卷积神经网络,
搞LLM这类生成文字,图片,乃至视频的模型,
是没有什么意义的奇技淫巧,
(除了生成小黄图外)。
欧美在卷积神经网络上走的是邪路,
中国把卷积神经网络用在工业生产上,
走的才是正路。
凭什么说正路邪路?
谁有资格下判断?
上帝有资格下判断,
你灭绝了,你就是邪路。
今天中国有无人出租车,
明天能不能有无人自杀机,
后天能不能有无人坦克呢?
你总不能指望LLM,
靠嘴炮喷退无人坦克吧?[笑而不语]
人工智能和通用AI还很远,
现在先用这些弱AI,
解决简单的,范围有限的工业生产问题,
才是踏踏实实的最优解[笑而不语]


用户45xxx35
小编黑姜萍有点下作!
张三疯
姜萍的情况还没定案,决赛成绩还没出,作者你小心翻车被扇脸,现在还是保守点吧