“名人”还是“业5”?
从“围棋AI分析”看中国清代围棋水平
崔灿

导言
中国古代围棋历经千年发展,在清代中期达到了巅峰水平,这一史实如今并无太多争议。然而清代围棋国手们的棋力究竟如何,与当代棋手相比又孰高孰低?历朝历代的围棋高手对于这一问题,可谓是众说纷纭,褒贬不一。
在国内各大围棋论坛上,“古今之争”向来是棋迷们激烈争辩的话题。“崇古派”大多被中国古谱中呈现出的激烈战斗所折服,认为围棋的本质就是计算,清代国手强大的中盘力量更胜今朝;“贬古派”则对古谱中“奇怪”的布局定式,以及大局观嗤之以鼻,时代背景的不同,也是“古不如今”的惯用论据。两方讨论的基础并不统一,观点难以调和,古今围棋规则方面的差异,客观上也让中国古谱内容评价的难度增加。因此,中国古代围棋的水平——主要以黄龙士,范西屏和施襄夏为代表的清代围棋水平争论,持续多年也没有什么结果。
2016年,人工智能AlphaGo横空出世,击败了人类围棋顶尖高手,围棋也从此进入了AI时代。四年之后,能够自由调整贴目的开源围棋AI“KataGo”,支持了包括“还棋头”在内的所有围棋规则,这让古今围棋高手“关公战秦琼”成为可能。如今,网络上已经出现了一些利用围棋AI分析数据,评价不同时代棋手水平高低的尝试。然而这些研究大多缺乏规范性,甚至违背基本的统计学原理,如果使用的方法在逻辑上漏洞百出,结论的可靠性自然无从谈起。围棋AI分析能否公正的鉴定棋手水平?棋谱数据与分析指标的选择,如何做到不偏不倚,令人信服,并经得起统计学的检验?这些都是将围棋AI作为棋力评价工具之前,必须要回答的问题。
作为传统文化的组成部分,中国古棋的内容一定程度上体现了前人的思想与价值观,具有深刻挖掘与整理的必要。中国古代的围棋规则未能延续至今天,缘于晚清时期中日围棋水平的巨大差距。中国古棋的思想内涵不被今日棋界所重视,“全面落后于日本”的刻板印象是其一大原因。围棋AI为人们提供了考察中国古棋的全新视角,中国古代围棋国手的技艺,能否因此而得到正名呢?
01 “清代围棋水平”职业棋手观点综述
清代围棋国手的技艺,在当世就有极高的评价。清代知名小说家,《镜花缘》的作者李汝珍曾颂赞黄龙士“异想天开,别创生面,极尽心思之巧,遂开一代之盛”。清末围棋棋谱编撰家邓元鏸,称范西屏“奇妙高远,如神龙变化,莫测首尾”、“崇山峻岭,抱负高奇”,施襄夏“大海巨浸,含蓄深远”、“邃密精严,如老骥驰骋,不失步骤”等等。
不过,这类评价多为极尽赞誉之词,严重缺乏区分度。另外,对棋手的评语基本出自文人之手,受到棋力方面的限制。根据记载,李汝珍与清代中期国手的差距至少有二至三子[1];邓元鏸据说是张乐山让二子的水平,而张乐山在清末高部道平访华期间,受其二子互有胜负。考虑到低手难以对高手棋力做出准确的评估,对于清代围棋国手真实水平的推断,文人留下的只言片语并没有多大意义。
晚清著名国手周小松,被人问及其与本朝同行的高下时,答曰:“如遇施、范不能敌,余皆抗行耳”。这也是如今唯一能够看到的清代“国手”级棋士,关于彼此之间棋力水平相对清晰的评价。作为清代最后一位公认的国手,周小松的观点具有一定参考价值,但某一时期内部的棋手水平排序,与一个时代整体围棋水平的高低并无关联。俗话说“当局者迷”,下面主要考察一些不同时代的“专家级旁观者”,对以清代国手为代表的中国古棋水平的观点。
江户安永年间(1772-1781),一部清代棋书传到了日本。本因坊察元、井上因硕(八世)以及当时的其他一些棋手,对书中棋谱进行了讨论,认为对局者大致有“三四段水平”。这是最早的来自外部的棋手,对清代棋手水平的评价。
按照当时的日本段位制度,四段与最高水平“名人”的交手棋份为“二三”,即两盘棋中一盘受二子,一盘受三子。这基本代表了当时的日本棋界,关于中国清代围棋水平的看法。被誉为“日本古代围棋三棋圣”之一的本因坊丈和,对于清代棋谱表现出的水平,也持类似的观点。
上面这段记载,出自1849年刊行的《烂柯堂棋话》,著者为江户棋手中学识广博的“准名人”林元美,他也认为清代棋手水平与日本的“名人”有很大差距。书中并未提及当时传至江户的清代书籍名称,以及被评价的究竟是哪几位清代棋手。不过作者在同一处提到,他已经从中挑选了一些觉得比较有意思的棋谱,收至其个人著作《棋经精妙》当中。经查,该书第四卷收录的清代著名国手棋谱,包括黄龙士、徐星友,以及清代中期“梁程范施”四大家。范西屏与施襄夏“当湖十局”中的两局也赫然在内。可见上述几位日本江户时代的棋手,并非是未见高人名谱,才给予清代围棋水平“三四段”这样的低评价。
一百多年后,日本又一位“学者型”棋手安永一,对中国古棋的历史沿革进行了全面考察。书中用“技术显著地发展”,“令人惊叹的准确计算”等字眼称赞了清代的棋手,并认为清代棋手中盘阶段展现出的水平,与当时(1977年)中国的顶尖棋手陈祖德、王汝南等人相差无几。但对清代棋手的布局,安永一给出的评语是“价值不明的定型”,“实在不敢恭维”。书中还将“一直未能摆脱过去的形态”的清代围棋布局,上升至世界观,民族性格等方面,并将近代中国围棋落后的原因归结于此[2]。这种将清代围棋的布局与中盘水平“一分为二”的评判方法,成了此后对中国古棋评价的一个“范式”。即便是在力挺中国古棋的职业棋手那里,也普遍承认清代围棋布局水准不高,理论匮乏。与“贬古”棋手们的分歧只剩下清代国手的中盘到底是“职业水平”,还是“乱砍乱杀”。
新中国成立以来,由于资料的匮乏,国内老一辈棋手大多对中国古谱有所涉猎。其中最具权威的中国古谱研究者非陈祖德莫属。在其生前所著各类古谱书籍中,他认为清代国手在棋谱中展现出了极高的素质,许多棋局关键之处的构思与着法,值得我们欣赏与学习。但对清代国手的棋力相当于今天什么水平这一问题,并未明确做出回答。
至于清代围棋“乏味”的布局,以及棋谱中一些明显的瑕疵,陈老认为时代与规则不同,那时中国围棋的竞技性尚不完备。今人应当有容乃大,不宜戴着有色眼镜,对古代棋手责备求全。他曾在书中这样写道[3]:
……进一步讲,如果我们固步自封,自高自大,失去了进步的动力,也许几百年后,那时的人们回头来看今天的棋,也如今人看清代的古棋一般,认为我们的下法不够先进,不够谨严,甚至不明棋理,如果不幸出现这种情况,那可就糟糕之至了。
这段话从侧面说明了当今国内棋界对中国古棋的主流观点。从“不够先进”以及前面的“有容乃大”可以看出,陈老并没有否认之前由安永一奠定下来的,对中国古棋布局的负面评价。
与陈祖德同时代的另外两位古谱研究大家——程晓流和赵之云,对中国古棋的看法更为“悲观”。程晓流认为,梁程范施“四大家”时期,中国的棋艺发展到一个顶峰,但与当时(十八世纪)日本棋理研究的进步相比,还是有相当大的差距[4]。赵之云在被问及“古今之争”的问题时说的更直接:“与现代棋手相比,(中国)古代棋手处于较低的水平”。理由包括时代进步的因素,以及相比古谱旁边的评语,当代棋评的内容更加丰富与深刻。他甚至还推测,明代以后,日本的围棋水平已不在中国之下[4]。
由于程、赵二人在棋手群体中有着相当高的文化素养,上述观点颇具影响力,时常被“贬古派”棋友拿来作为论据。其他几位新中国第一代知名棋手,对中国古棋水平大致抱有类似的看法。罗建文曾在探讨“棋风”的话题中谈道[4]:
……明治时期,本因坊丈和所下的杀棋,我看与中国的古棋没有什么两样。后来日本慢慢变了棋风,从秀荣以后趋向平稳了,因为棋发展到了这个时候,“手割”等现代的东西渐渐出来了,说明人们对棋艺的思维已提到一定的高度。当日本人将座子撤消之后,布局类型多了,也才开始有研究理论的条件。
上面的描述与史实有一定出入,“手割”与日本围棋步入平稳风格的历史时间,都早于丈和所处的年代。不过罗老显然认为,中国古棋布局受“座子”的限制,缺乏理论研究的基础。在这一点上,王汝南也有过相似的表述[4]:
中国的棋风呢,由于历史的背景,古代棋一摆开座子,不讲布局就开始上,历史上这么过来的。……
关于“古今之争”,王汝南认为从竞技层面上说,当代的围棋水平是有史以来最高的。无论是布局还是中盘的计算力,现在的棋手钻研得更深,棋力肯定超过前人。原因主要是“现代棋手把竞技围棋作为自己的事业”和“当代的资讯发达是古人无法比拟的”[5]。这与赵之云的观点基本一致。
聂卫平曾在一次湖南卫视的访谈节目里大赞黄龙士的棋才,但认为他“下不过那个道策”。另一次围棋活动中,聂老在“谁是古今第一高手”这个话题面前避实就虚,但对“现代高手在中国古棋规则下,能不能赢黄龙士”做出了明确回答[6]:
如果让现在的棋手去下座子棋,只要熟悉了规则,还是要厉害些,毕竟这么多年了,围棋的理念和技术都在进步。年轻棋手在黄龙士那个时代不一定下得过他,但现在肯定能赢他。
与老一代前辈的含蓄相比,一些青年棋手在谈论中国古棋水平时更加直言不讳。2000年5月,俞斌在LG杯夺冠后参加了一场与棋迷的网络交流活动。当被问及“你认为中国古代一流高手能否下过如今的业余强手”时,答道[7]:
我觉得按现在的围棋规则还是当今的业余棋手厉害一些,但如果是座子制的话就很难说了。
这是第一次有明确纪录的职业棋手表态,将中国古代围棋国手的水平与当代围棋业余高手划等号,“古棋业6论”也由此诞生。
需要说明的是,2000年左右的国内业余围棋强豪,大约是职业高手让两子水平,这个评价要比江户时期日本棋手的“三四段”还高一些。然而“业余水平”这种说法毕竟过于刺耳,“崇古派”棋友对这一观点自然是大加批判。不过,余平在提及此事时,认为这种评价“已经够客气了”。理由是现代顶尖业余棋手的训练时间与环境都要远远超过范施等人,没有理由认为古人更强。古人与现代人之间的差别类似“大刀长矛对机枪”,中国古代对围棋的认识与日本创新后的理论相比,无疑存在着“骑兵对坦克”的时代落差[8][9]。
上述言论还不是职业棋手“心直口快”的极限。2014年1月,刘世振在上海五星体育频道《棋牌新教室》栏目解说“当湖十局”时,对范施二人作了如下评价:
(对于前面陈老“三百年前能下出这样的棋已经非常了不起了”的观点)并不是说他们的棋质量有多高。平心而论,如果我们实事求是地说,施襄夏和范西屏放到现在的围棋水平来说,应该是业余强5(段)的实力。
(对于“古棋力量特别大,计算特别深”的说法)之前曾经深以为然,但现在再来看,恰恰他们最缺乏的就是力量。不是说他们的力量小,计算差,在于他们发力的点不对。
考虑到近年来国内业余段位“水分”不断增加,2014年的业余强5段与十多年之前的业余强豪并不在一个水平线上,“范施业5论”可谓是将中国古棋的评价又降低了一个档次。再加上刘世振将部分前辈赞誉有加的古代国手计算力评价为“发力点不对”,节目一经播出,就在各大网络围棋论坛引起轩然大波。
在当时,围棋TV网趁机推出了“古今之争”系列专题,邀请当事人与各路专家棋手畅谈对中国古棋的看法。在后续的专题节目中,刘世振对他之前争议言辞的表述不严谨之处,做了补充说明——他觉得范施肯定下不过当代的职业“新初段”,“强业5”的说法,是与上海地区部分业余6段棋手对比而来;他心中的“力量”一词内涵更为广范,与一般人的理解可能有所差别。同时,他表示对中国古棋的基本观点并没有改变[10]。大多数年轻职业棋手在不同场合谈及此事时,也对“今胜于古”这一观点表示了支持。至于中国古棋的水平,觉得古代国手能够踏入当今职业门槛的,已经算得上职业棋手中的“挺古派”了。
也有少数职业棋手对古代国手的水平持正面态度,甚至给予了相当高的评价。例如吴清源年轻时就觉得中国清代围棋水平相当于日本的七段水准,在其全盛时期时更进一步,认为清代围棋顶尖高手可与日本“名人级”棋手平起平坐,直至晚年他仍然保持这种信念[3][11]。
王元曾在各种访谈与棋评中提及“范施的棋艺与境界,今人远远没有达到”,还认为围棋人工智能“AlphaGo”都对中国古棋着法进行了借鉴[12]。胡耀宇称范施二人若是穿越到现在,职业(棋手)的实力无可争议。若二人能逐渐学习当代的围棋理论,很可能会超越如今“时代的局限”[13]。但总体而言,认为中国古代国手可于当今顶尖围棋高手相抗衡的职业棋手屈指可数,在棋界普遍看低中国古棋的大环境下,这一类声音并未受到太多重视。
在职业棋手的评价之外,这几年还出现了一些从各种角度探讨中国古棋的学术论文。这些文章大多结合古籍与棋谱,对中国古代围棋的不同方面进行梳理,证明了中国古棋绝非“一味好杀,未能形成理论[14][15]”,并希望通过总结古代围棋理论与技术发展过程,公正评价古代国手们的技艺高度[16]。但上述探讨中国古棋各种技术细节的学术研究,与通过棋谱片段来评价中国古代国手的当代职业棋手们一样,很难对中国古棋的真实水平提出具有说服力的评价。
胡煜清与陈祖源通过对“晚清高部道平访华”一事的考证与当时的棋谱分析,认为晚清国手周小松的水平可与日本“末代名人”本因坊秀哉一争高下[17]。然而这一结论主要通过不同年代棋手之间授子棋份的“链式关联”推导而来,作者在文中也承认路线过长的关联,意义可能相对有限。此外,使用“授子棋份”来建立棋力参照系这一方法,至少有以下两点缺陷:一是棋手在不同时期的水平并不一致,很难断定“血泪篇”时黄龙士让徐星友三子,此后徐星友一统棋坛到底是“棋力大进”,还是同时代的对手太弱,以及其晚年与梁程对战时,水平究竟下滑多少。二是棋手的授(受)子棋战绩,不一定与互先棋谱表现出的水平完全相同,有些棋手可能对让子棋有额外心得。例如陈祖德曾是公认的指导棋高手,面对同样水平的棋友,他往往能比其他职业棋手多让一子。关于第二点,作者在文中亦有提及,但认为“指导棋是当时职业棋手的主要收入来源”,故“没有不擅长下让子棋的棋手”。这一推论在逻辑上并不完备,况且指导棋的收费不一定与胜负挂钩,高手未必会全力争胜,这与也中日两国棋手在“指导棋”上的观念差异有关。
最后,该文采用了围棋AI(弈客“鹰眼”)辅助分析,但并未说明具体标准——使用的AI权重版本、每步棋计算量,采用何种规则,有无贴子等等。这为AI分析数据结果的验证增加了难度。千百年来,对于棋盘上布局或中盘阶段一手棋的好坏,棋手个人乃至一个时代的围棋水平,基本上只能通过定性分析评价。由于这种方法易受个人价值观的影响,时常面临“无解”的争吵。随着围棋AI领域的快速发展,人们第一次拥有了对上述问题进行定量分析的可能。不过,使用围棋AI进行研究,也应当遵循相应的学术规范。毕竟任何一项研究想要保证结果的真实与客观,都绕不开严谨性、透明性、可重复性和独立验证等科学方法的基石。
02 “围棋AI分析”的研究方法与规范
2016年3月,围棋人工智能AlphaGo在“人机大战”中4:1战胜了李世石,将围棋带入了AI时代。随后两年涌现出的各路围棋AI,棋力也都逐渐超越了人类顶尖棋手。围棋上千年的发展历程中,首次出现了明确高于人类水平的尺度,棋手们在汲取围棋AI“营养”的同时,自然萌生了用其衡量围棋水平的想法。不过当时的围棋AI基本只支持中国规则,在这类分析中,将不同时代的知名棋手放在一起对比,显然存在严谨性方面的不足。
围棋AI“KataGo”在2020年1月的一次版本更新之后,开始支持包括“还棋头”在内的多种围棋规则,为古今围棋高手“关公战秦琼”初步扫清了障碍。通过“围棋AI分析”来判定棋手水平,是“围棋学”中的全新领域。有必要先对围棋AI分析研究的基本假设、逻辑原理、规则程序等问题进行深入探讨。下面介绍本研究使用的围棋AI程序与加载平台,并详细阐述围棋AI分析的常用参数及其特性,再对利用围棋AI开展研究的注意事项做出总结。
(一)KataGo与Lizzie
1.KataGo(卡塔围棋)
最近两年,在围棋AI群雄逐鹿的过程中,KataGo成了其中的佼佼者。该程序为由计算机科学家David J. Wu开发,在通用棋类程序“AlphaZero”技术的基础上,优化了相关算法,做出了许多修改与增强。如今,KataGo已经成为了当前棋力最强的开源围棋AI,支持各种规格的棋盘,可以随时调节贴目的大小,并且在一定程度的优势下,不会像AlphaGo那样出现无谓的目数退让,是除“绝艺”与“星阵”两大商业围棋AI之外,棋手训练提高必备的围棋AI程序。
2.Lizzie(里拉零图形界面)
围棋AI脚本一般都遵循GTP[2]协议,可直接在命令行界面运行。若是让围棋AI运行在图形界面,则需要专用的可执行程序加载。
“Lizzie”诞生于2018年初,是程序员Annie Wagner设计的一款可加载围棋AI的图形界面程序,最初是为了实现围棋AI“Leela Zero[3]”的棋局实时分析功能。此后增加了对KataGo及一些其他开源围棋AI引擎的支持,可以使各种围棋AI运行在图形化界面下,方便使用者进行棋局分析。
如今被国内职业棋手与围棋爱好者广泛使用的Lizzie程序,是由一位名为Yzy的网友修改后的版本,在原先基础上增加了“鹰眼分析”等新功能,数据统计方面也提供了诸多便利。下文中的“Lizzie”均指这一修改版。本研究采用的围棋AI指标参数标准,大多也基于该版本Lizzie的默认设定,理由将在后文中陆续阐明。

图1 Lizzie程序运行界面简介[4]
(二)“权重”与“计算量”
1.权重(Weights)
围棋AI训练出的“神经网络[5]”是个复杂的函数,“权重”的本意是函数中的系数,即神经网络的参数。一款围棋AI在进化过程中,会留下不同的版本,以及相应的“权重文件”。如果用Windows上的“记事本”程序将其打开,会发现里面全部都是意义不明的数字,很难想象围棋AI就是用这些数字战胜了人类棋手。
现在权重一词多取“权重文件”之意,结合围棋AI版本号,指某一围棋AI的特定版本。以“KataGo 1.4.5 20b256c”为例,前面的“KataGo 1.4.5”是围棋AI名称与版本号,后面“20b256c”中的“b”(Blocks)前面的数字即神经网络的层数[6]。“c”(Channel)前面的数字是指每一层的通道[7]大小。总体来说,这两个数值越大,围棋AI的计算速度就越慢[8],但在相同的计算量下水平也越高。
2.计算量
“计算量”有时也称“模拟量”,是对围棋AI程序中“playouts[9]”次数的统计。该指标通常以“k”(千)为单位,一般来说,计算量越高意味着围棋AI的评估结果越准确,但其提升幅度随计算量增加而减小[10]。计算量的大小不同,会对围棋AI其他指标产生一定影响,见后文具体说明。
(三)“吻合度”
吻合度,即对局者在一盘棋中,与围棋AI推荐着法的总体吻合程度。该指标在围棋圈内广为人知,经常被用来评价棋手一盘棋的整体发挥,棋局中某一阶段的表现,以及作为对局者是否“遛狗[11]”的重要判断依据。其基本思路是将一局棋视为一张试卷,与围棋AI推荐吻合的着法即为“正解”,根据正确答案的多寡,来评价棋局的质量。
对于吻合度的上述逻辑,有人从哲学层面提出了质疑,认为“围棋AI认为的最佳选点,对人类棋手来说不一定是最好的,我们更应该选择自己能够理解、掌控的下法”。这种观点固然有一定道理,但从根本上否定了“围棋AI分析能够判定棋手水平”的前提,相关研究也就无从谈起。至少在当下,绝大多数棋手都认可“吻合度”与招法好坏的相关性。
在实际使用中,吻合度可以设定不同的标准。野狐围棋“绝艺精解”对吻合度的定义是“棋手落子与绝艺第一推荐的全部重合点”。而Lizzie默认的吻合度标准是:“AI推荐的前三选点,且计算量不低于最高选点的20%”。“前三选点”这一标准,是考虑到棋盘上有时出现几个选点优劣相对接近,或完全等价的局面。例如图2这盘棋,黑棋下一手在哪里收气都没有区别,只将“一选”作为吻合标准显然不合理。

图2 第二届“百灵杯”决赛第三局
柯洁VS邱峻 棋局片段
标准中对计算量的要求,则是为了避免围棋AI推荐的第二、三选点与“一选”差距太大时也被纳入吻合。当一个局面围棋AI认为存在“唯一正解”时,会将99%以上的计算量投入此处,此时,只要总计算量不是太低,第二、三选点一定过不了“最高选点计算量的20%”这一关。后文中的吻合度指标如无特别说明,均采用“前三选点且计算量不低于最高选点20%”这一Lizzie默认标准。
那么,一盘棋“吻合度”的高低,究竟能不能作为判定棋手水平的依据呢?回答这个问题,首先要考察吻合度这一指标的信度与效度。“信度”即吻合度的稳定程度如何,是否易受其他因素的影响;“效度”则要寻找吻合度与棋局胜负的关联性,或其他“吻合度和棋力相关”的有力证据。
1.围棋AI“随机性”对吻合度的影响
2006年,“蒙特卡罗方法[12]”被引入了围棋AI开发,这是一次革命性的突破。如今新一代围棋AI靠着“神经网络”一飞冲天,但“随机模拟”仍然是所有围棋AI不可或缺的基础。由于每一次模拟运算都完全随机,导致围棋AI在相同的局面下,未必每次都是同样的选择。这对吻合度会带来多大的影响呢?“重测信度”实验的结果如下:

在不同年代四盘棋的10次围棋AI分析中,所有棋手的吻合度都有波动,但总体并不明显——标准差几乎都在2%以内。另外,所有棋局中“吻合手数”在10次分析中浮动的上下限,最多也只有8手棋。因此,有理由认为围棋AI“随机性”对吻合度的影响相对有限。
不过,这种随机性对研究中的数据获取操作提出了挑战,理想的情况下,应对棋局样本多次分析取样,再取其平均值。另外,研究者应严格遵循学术研究数据使用中的规范,避免出现任何数据方面的人为选择。
2.“权重”对吻合度的影响
任何一款围棋AI,进化之路都可谓是永无止境,过程中自然也留下了一系列的版本。这些不同水平的版本,对吻合度的“看法”会不会存在差异呢?下面选取了四种常用的KataGo官方权重进行测试,结果如下:

几个常用的官方权重在计算量相同的情况下,虽然每盘棋在吻合度上都略有差别,但很难区分这种差异是源自权重的不同,还是围棋AI的“随机性”所致。各权重之间棋手平均值几乎没有差别,方差分析结果也证实了这一点——四组数据之间均无显著差异。详见图3。

图3 “当湖十局”不同权重下吻合度数据方差分析[13]
在当代棋谱的跨权重实验中,也得到了类似的结果.可见权重因素对于吻合度基本没有影响。只要是超越了人类顶尖水平的围棋AI权重,选取哪一款进行测试都是可行的。
3.“计算量”对吻合度的影响
理想情况下,围棋AI的计算量下肯定是越高越好。受时间与硬件设备的限制,在上面两个实验中,计算量都固定为100k。那么,计算量的高低又会对吻合度产生怎样的影响呢?同样以“当湖十局”为例,测试结果如下:

可以看出,在不同尺度的计算量下,吻合度出现了较为明显的差别。方差分析的结果,施襄夏的吻合度组间差异十分具有显著性;范西屏的吻合度组间差异未见显著,但也在临界值附近,见图4。

图4 “当湖十局”不同计算量下吻合度数据方差分析
可见在不同的计算量下,围棋AI吻合度也不同,不能直接进行比较。在对比两组吻合度的数据时,需保证计算量的一致性。
表3中,吻合度数值与计算量的高低,大致呈反比关系。原因可能是在高计算量下,不同选点之间模拟次数的差值被放大,一些局面中与一选存在“真正差异”的第二、三选点,难以实现“计算量不低于最高值20%”的要求。简而言之就是计算量的增加,让一些围棋AI初看还行,细算后又否定的选点无法蒙混过关。若将吻合度标准改为“一选”,计算量不同导致的差异将不再明显,这支持了上面的推测。见表4:
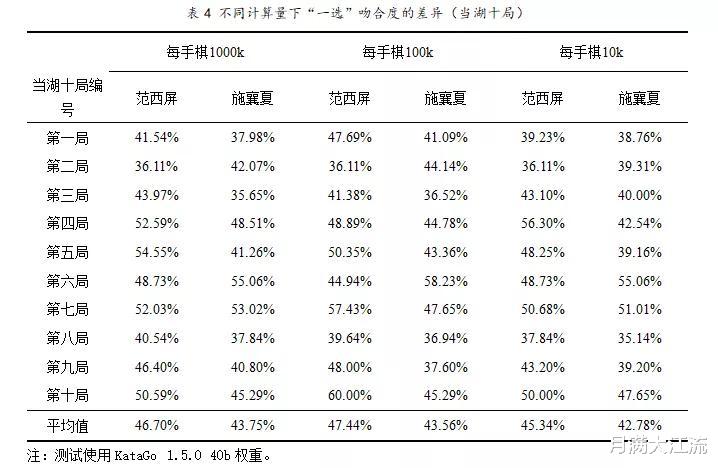
“一选吻合度”不受计算量的影响,并不意味着采用这种标准更为科学,这一现象反而暴露了吻合度的一大缺陷,即易受“必然着法”影响的问题。
4.“必然着法”对吻合度的影响
图2中,执黑的柯洁上来就在“大雪崩”定式中刀,对于职业棋手来说,这个局部下完基本就可以认输了。从图中左侧KataGo的胜率曲线与目差[14]来看,黑方后面确实没什么机会。然而本局柯洁全局吻合度达到了67.4%,在1000k的计算量下,是个相当高的数字!这盘棋还是围棋AI时代之前的棋谱,没有如今棋手们学习围棋AI获得的“布局红利”。一场完败的棋谱,吻合度却如此之高,这个指标还能不能用来判定棋手水平呢?

图5 左:柯洁中刀过程(16=▲)右:围棋AI分段评分
为什么上来就大势已定的一盘棋,最终黑棋竟收获了如此之高的吻合度?通过图中与吻合度近似的指标“AI评分[15]”不同阶段数据,可以看出一些端倪——尽管开局第一个定式就崩盘,KataGo对黑棋布局的评价一点也不低。
简单介绍一下柯洁的中刀过程:在“大雪崩”定式这一型中,黑1本应在7位压,实战“不识定式”的柯洁遭到了白6以下的组合拳,白棋先弃三子,最终将黑左边五子吃回,形成通天厚势。至此白棋已获压倒性的优势。
然而在图5中,黑方的十步棋除了黑1扳之外,其余九手全部踏入了围棋AI“吻合度”区间!由于中刀之后的变化是“一本道”,反而让黑棋的吻合度大幅提升。另外,尽管围棋AI对人类的大雪崩定式下法颇有微词,但整个定式过程存在大量的必然下法,同样提升了双方布局阶段的吻合度。这种“吻合”对于判定棋手水平来说,显然毫无意义。
网络上“围棋AI评古”相关文章的评论区,最常见的质疑就是上面这一现象,即接触战中的“必然”着法会增加。像中国古棋那样普遍的全盘战斗风格,大量的必然下法会使吻合度偏高。然而,棋盘上的“风格”是无法量化的。我们可以就棋盘上某个具体的局部,主观认定其吻合度并不体现水平,但某种棋风影响吻合度这一假说,无法用科学的方法找到有效证明。况且中国古棋的战斗风格与当代大型定式相比,到底哪一边吻合度更“沾光”也难以定论;即便是平稳风格的局面,中盘也不可能没有棋子接触,难以判断其“必然性”是否一定不高。另外,在不同水平棋手那里,什么样的着法属于“必然”,本身标准就不一致。总而言之,“战斗风格影响吻合度”这种既无法证实也无法证伪的推测,作为一项追求严谨与可靠性的研究而言,存而不论是最好的办法。
篮球界有一个类似的案例。詹姆斯·哈登是NBA过去三个赛季的常规赛“得分王”。可大量球迷对其成就并不认可,认为他的场均高得分与其“碰瓷”打法(投篮时主动寻找手臂接触,造犯规获得罚球)密切相关,这是在钻篮球规则的空子,不能体现真正的得分能力。很显然,我们不可能客观判定哈登每一次投篮时的造犯规是否属于“碰瓷”,从而计算出其“真实”的得分能力。“吻合度受到棋风影响”的说法,与上面这件事情类似,空有“观感”而无从证实。
不过,尽管难以进行统计,任何棋局中都有一些“必然着法”是不争的事实。前面“一选吻合度不受计算量的影响”的现象,从侧面体现了这一点。“前三选点且不低于最高计算量20%”的标准,让吻合度在不同计算量下出现了差别,原因是计算量存在明显差异的围棋AI,在棋力上有着较为明显的高下之分[16],导致对棋盘上“模糊地带”的标准有严有宽。如果一盘棋在不同级别的“围棋AI老师”那里拿到了同样的评分,最有可能的解释是:此前能够体现区分度的“题型”消失了,剩下的都是不需要依靠“阅卷水平”就可以打对勾的简单题目。由于每盘棋“送分题”的多寡并不一致,使用吻合度进行棋力评价,首先需要一定的棋局样本量。“单局吻合度”由于难以排除棋局随机因素的影响,用来评价棋手水平效力相对有限。
5.棋局手数对吻合度的影响
上一节提到,对局中不可避免的存在一些必然着法。这些“送分题”在每盘棋中总量是随机的,但在棋局的不同阶段,其分布是否均匀呢?我们很容易根据经验推测:一盘棋布局阶段的“必然”下法最少,越是往后必然着法就越多,在官子阶段达到顶峰。
与无法证明的“棋风影响吻合度”不同,“手数影响吻合度”的假说,可以通过棋谱统计的方法加以证实。2019年初,围棋AI“ELF OpenGo”分析了从十六世纪到2018年的将近87000局职业棋谱,得出了许多有趣的结论。其中,关于棋局不同阶段“吻合度”的统计结果如下[18]:

表中的“吻合度(Matching)”是只统计围棋AI“一选”的数值,而“基本吻合(Almost Matching)”则设定为“胜率下降不超过1%的着法”,这与Lizzie的默认吻合度设定有异曲同工之处。两种标准下的结果对比,再次体现出“一选”在区分度方面的缺陷。不过无论哪种标准,吻合度数值都随着棋局的进行上升。
上述结果是对大量棋局不同阶段的横向考察,尚未直接验证完整的一盘棋也遵循“吻合度随手数上升”这一规律。另外,该研究并未涉及棋局180手之后的平均吻合情况,每手棋的计算量只有1.6k,也没有考虑规则与贴目(子)因素,这些缺陷在一定程度上弱化了其结论。为了证实“吻合度”是否如预期那样与一盘棋的总手数相关,对部分当代棋谱[17]按手数进行分组比对,结果见图6:

图6 世界大赛决赛棋谱 手数与吻合度的关系(N=270)
(KataGo 1.5.0 20b官方权重,每手棋1000k计算量)
数据表明,一盘棋的总手数与吻合度的确相关,吻合度随手数增加呈线性上升。因此,将吻合度这一指标进行对比时,需考虑棋局手数因素的影响,设法加以平衡。
6.局面优劣对吻合度的影响
在一盘棋中,棋手的思路与着法与局势的好坏直接关联,围棋AI也是如此。一般来说,当局面优劣较为明显时,围棋AI更倾向于将计算量“平铺”至不同的选点,这会对吻合度产生一定的影响。

图7 第十届“LG杯”决赛第二局 古力VS陈耀烨 棋局片段
(KataGo 1.5.0 20b官方权重,每手棋1000k计算量)
以图7这盘棋为例,根据目差可以看出,此时黑棋优势十分明显,基本上走哪里都不影响胜负。实战黑棋下一手“幸运”地满足了Lizzie的吻合条件[18],但很难说这步棋与图中的“四选”以及其他“不吻合”的选点,有什么实际上的优劣差别。

图8 第十届“LG杯”决赛第二局 古力VS陈耀烨 棋局片段续
需要说明的是,即便在“极端形势”下,KataGo也不是完全没有倾向性,图8中双方的两步棋,就只有“一选”满足吻合条件。但无论如何,当局面优劣明显时围棋AI认可的下法增加,会影响到“吻合”的判定。这动摇了用吻合度判定着法好坏,从而推断棋手水平的基本逻辑。
对上述问题的解决方案,与前面的“必然着法”相同——增加棋局样本数目,从而避免“极端数据”带来的影响。后面介绍的“AI评分”也在一定程度上缓解了这一问题。
7.围棋AI“盲点”对吻合度的影响
前面提到,围棋AI的棋力随“计算量”上升。但在复杂局面或多手数的直线计算中,即便让围棋AI无限时间(计算量)思考,有时也会出现盲点或误算。此时的“吻合”自然失去了判定着法好坏的作用。

图9 《范廷钰和AI错失“绝杀”申真谞的良机》片段
耀宇围棋公众号
第十三届“春兰杯”八强赛的一盘棋,就出现了这样的案例。如胡耀宇在文中所说,无论是KataGo各种权重,还是绝艺和星阵的精解分析,都没能发现黑棋一路点的正确时机[19]。倘若实战黑149真的下出了这一妙手,也不会被围棋AI纳入“吻合”。图5中,KataGo[19]同样未能算出白12退的好手。尽管这步棋之后,白棋的胜率与目差双双上升,也无法改变“不吻合”的结果。
好在如今围棋AI的综合水平远超人类,上述局面出现的次数极其有限。在一盘棋上百手的“大样本”中,一两个错误的判断基本不影响全局的吻合数值。在各种影响吻合度的因素中,围棋AI“盲点”这一条可以说是最小的。如果统计的棋局样本总量足够多,这一因素更是可以忽略不计。
8.吻合度与胜负的关系
之前几节已经看到,吻合度会受棋盘上各种各样的因素影响,许多因素只能依靠增加样本量来减免影响。那么,在大样本的条件下,能否建立起吻合度与棋力的关联呢?前面柯洁与邱峻那盘棋,开局崩盘并收获一场完败的柯洁,全局吻合度居然比对手还要高。当然,在一盘棋中整体发挥更好,最终却未能获胜也很正常,但这种事情如果出现频率过高,必然会令人质疑“吻合度”能否体现棋手真实水平。因此,有必要统计一下棋局胜负与吻合度的关系。结果见表6。
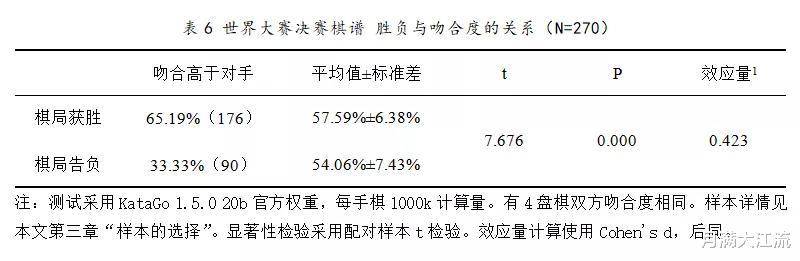
数据显示,胜方吻合度高于对手的棋局,占样本总体将近三分之二。无论是数量还是平均数值上,获胜一方吻合度都有一定的优势,且这种领先在统计学上存在极其显著的差异(P<0.001< span="">),效应量也接近中等程度,即结论在统计与实际上都存在意义。因此,可以认为吻合度与棋局胜负存在正相关。有力支持了“大样本下吻合度能够判断棋力水平”的说法。
和“与棋局胜负存在关联”相比,下面这个不同棋手群体吻合度对比测试,更直接的表明吻合度与棋力存在相关性。详见表7。

结果显示,围棋职业高手相比传统意义上的业余高手,在棋局吻合度方面的领先存在极其显著的差异(P<0.001),< span="">并有接近中等程度的效应量,可以认为这种差异存在统计学与实际上的意义。
“让两子”左右的水平差距,在大样本下就能体现出吻合度的差别,这充分说明“围棋AI吻合度”具备评价棋手水平的资格。考虑到该指标存在的一些缺点,使用时需遵循一定的规范,将在本章末尾一并总结。
(四)“AI评分”
Lizzie默认的吻合度标准是:“围棋AI推荐的前三选点,且计算量不低于最高选点的20%”。尽管这一设定有着充分的理由,但“前三”与“20%”都是权宜之计,任何标准都无法完美涵盖所有情况。比如黑棋第一步能不能踏入吻合,完全看围棋AI的心情——计算量的重心是否在棋盘右上角。另外前面我们已经看到,在优劣明显的棋局中,“前三选点”也无法保证对一些“无伤大雅”着法的误伤。
Yzy在Lizzie中增添了“AI评分”功能,一定程度上弥补了吻合度的这一不足。其计算公式如下:

该公式的思路,是将围棋AI所有计算过的选点,按照计算量的比例赋予相应评价。这让每一手棋的评分更加细化,也避免了一些错过“前三”或未能迈过“20%”门坎的着法,在吻合度中完全无法体现的缺点。测试表明,与吻合度相比,该指标受围棋AI“随机性”的影响更小。参见表8。

与表1中的“吻合度”数字相比,表8中不同测试之间的数值波动以及标准差明显更低。可以说AI评分进一步降低了偶然性,应该是更为合理的指标。不过,根据对已分析的古今棋谱数据观察,该指标与吻合度的相关系数为0.9以上。两者的差异在小范围内浮动[21],不具备统计学意义上的显著差异。诚然AI评分指标的设定更加科学,但继续使用如今知名度更高的“吻合度”也未尝不可。
经综合考虑,本研究对围棋AI分析的棋谱,同时统计棋局“吻合度”与“AI评分”两种指标数据。如果这两种指标的“显著性检验”结果冲突,将以AI评分结果为准。另外,Lizzie最新版本已将原先的“吻合度”改为“吻合率”,将“AI评分”命名为吻合度。为避免误解,本文中的“吻合度”与“AI评分”词语不作变动,仍取其原先的含义。
(五)“平均胜率波动”
KataGo统计了棋局某方落子后,其胜率与落子之前的局面相比波动了多少——通常是下跌了多少。当围棋AI出现误判时,一手棋可能会导致胜率上升,但“平均胜率波动”统计的是绝对值,无法纠正围棋AI犯下的错误。好在这种误差在“吻合度”那里已有提及,结论是影响基本可以忽略不计。
前面还提到,“棋输了但吻合度高于对手”的概率差不多有三分之一。不过即便是这种情况,负方全局的平均胜率波动几乎也都高于胜方[22],也就是说虽然“命中率”更高,但“脱靶”造成的后果更严重。由此可见,“平均胜率波动”可以成为棋力判定的参考性指标。胜率波动低不一定意味着发挥的好,也有可能是一场完败,胜率没有什么下跌的空间;但平均胜率波动过高,则一定表明棋力有限,在棋局关键阶段的洞察能力不足。常见于业余低手的“胜率心电图”即是如此。考虑到不同时代棋局贴目(子)并不一致,开局的胜率起点存在较大差别,另外胜率类指标也受对手给予压力大小的影响,使用该指标比对时严谨性难以保证,故仅作为辅助参考之用。
(六)“平均目差波动”
与上面的胜率波动类似,“目差”也有平均波动数值的统计。与虚无缥缈的“胜率”而言,将目光聚焦到目数上,似乎更符合人类棋手的思路。
然而目数的出入,与棋局胜负并不直接关联,在不同形势下,目数得失的价值并不一致。劣势下的放手一搏与优势下的退让求稳,在胜率上可能起不了什么波澜,但体现在目差波动数值上显然不同。因此,将“平均目差波动”作为评价棋力的标准,逻辑上有难以自圆其说之处。
在大样本尺度下,“平均目差波动”依然与胜负相关,但胜方领先的平均数值只有0.05目[23],差异并不明显。一位棋手的目差波动小,固然在一定程度上体现其局面掌控能力,但该指标受棋局风格影响的嫌疑比“吻合度”要大得多。与复杂的战斗局面相比,平稳的风格显然更容易降低每一手棋的目差波动。综上所述,与胜率的波动相比,平均目差波动尽管有体现棋手“细腻性”的一面,但逻辑上的缺陷也更明显。对于评价棋力来说,参考价值更为有限。
(七)“复杂度/不确定度”
在一手棋的“目差”之外,KataGo还统计了计算过程中所有变化[24]的目差,并根据计算量进行加权求和,得到当前局面的“目差标准差(scoreStdDev)”。Yzy在Lizzie中提取了这一指标,起初将其命名为“复杂度”,后因感觉表述不够准确,可能引起误解,遂更改为“不确定度”。
不过,一些棋友认为该指标可以结合“吻合度”,成为评价棋手水平的试金石。理由是倘若一个局面的“目差标准差”数值高,意味着围棋AI计算的变化出现了较大分歧,即“AI算不准”,这说明此时局面十分复杂。在局面复杂时吻合度高,要比局势平稳时的“吻合”更体现水平[20]。
上述说法在“效度”方面的逻辑似乎没问题,但未提及该指标“信度”方面的表现。对这一指标的考察测试,主要得出以下几点结论[21]:
1.根据该指标计算原理,在不同的计算量下,其数值会存在明显差异。围棋AI权重不同也会影响该指标数值。因此,“复杂度/不确定度”怎样才算“高”,缺乏明确的标准。
2.该指标会受到局面优势大小的影响,与当前局面“目差”的数值成正相关。
3.该指标数值“高”时,会放大围棋AI“随机性”的影响,导致取样方面的困难。
除了以上缺点之外,以“复杂度/不确定度”结合吻合度判定棋手水平,在逻辑方面存在硬伤——既然围棋AI都算不准了,那么此时的“吻合度”显然失去了优劣评价的意义。综上所述,“目差标准差”可以看作是围棋AI眼中棋盘上的变数,在一定程度上展现了棋局的风格,但“棋风”无法直接与水平挂钩。KataGo的作者David J. Wu在被问及这一指标的意义时,也表达了同样的观点[22]。
(八)其他指标
围棋AI“ELF OpenGo”在对人类历史棋谱进行分析研究时,提出了一些具有启发性的指标,包括“胜率下降最多的一手(Biggest Mistake)”、“第一步恶手出现时间(First Bad Move)”、“一盘棋的恶手数量(Number Of Bad Moves)”等等。这些评价标准固然有趣,但与棋力的关联性尚未得到确认,不同因子的权重如何设置也是一大难题。另外,由于这类指标在设置上有很大的随意性[25],不但难以服众,在研究中也很难做到完全撇清“先射箭后画靶”的嫌疑。因此,与相对固定,且受众更广的吻合度、AI评分等“默认标准”相比,提出其他一些特定的指标,或用几种指标组合建立模型作为评价棋力的标准,需要详细阐明其内在合理性,以及指标或模型能够区分棋手水平的依据。
美国职业篮球联赛(NBA)有各种各样的“高阶数据”——将各种基础数据赋权,用复杂的公式计算出结果,从不同角度评价球员在场上的贡献。但球迷们津津乐道的还是得分、篮板、助攻、命中率等一目了然的数字。基础数据对运动员水平的体现可能没那么全面,但争议性也是最少的,用围棋AI指标来评价棋手水平同样是如此。
(九)本章主要观点总结
1.围棋AI的“棋力”随计算量增加而变强,提升的幅度“前快后慢”。总体来说,计算量越高意味着围棋AI的评估结果越准确。
2.围棋AI“随机性”对吻合度的影响相对有限。但在理想情况下,应对棋局样本多次分析取样,再取其平均值。
3.当计算量不同时,围棋AI“吻合度”存在一定差异,不能直接进行对比。吻合度数值大致与计算量成反比,即计算量越高,吻合度越低。
4.在相同的计算量下,使用不同权重(20B、30B、40B等等)的围棋AI测试,在吻合度方面没有显著差异。
5.“一选吻合度”会造成许多误伤,在区分度方面也存在缺陷,并不比常用的“前三选点且不低于一选20%计算量”标准更可靠。
6.接触战中的“必然”着法会造成棋局吻合度偏高,但无法得出“某种棋风会使吻合度失真”的推断。
7.一盘棋的手数多少与吻合度正相关。在对比总手数不同的棋局时,需消除该因素的影响。
8.局面的优劣程度会影响吻合度的判定。可以通过增加棋局样本的方法减轻其影响。
9.围棋AI的误算对吻合度的影响极其有限,基本可以忽略不计。
10.在大样本下,围棋AI吻合度与棋局的胜负显著相关,且在已知的不同水平棋手群体对比中,吻合度同样呈现出显著差异。故有理由认为,吻合度在大样本下与棋力存在相关性,具备评价棋手水平的资格。
11.“AI评分”与吻合度的相关系数在0.9以上,两者作为评价工具都是可行的。不过该指标设定的更为合理,也能更好的避免围棋AI“随机性”的影响。
12.“平均胜率波动”可以成为棋力判定的“否决性”参考指标。胜率波动过高则水平一定有限,反之未然。
13.使用“目差”相关指标来评价棋力,在逻辑上有难以自圆其说之处,参考价值相对有限。
14.“复杂度/不确定度”这一指标在参与棋力评价时,存在逻辑上的硬伤。局面是否复杂无法直接与棋手的水平关联。
15.使用人为设定的指标或模型来评价棋手水平,很难完全消除标准方面的争议,需要详细阐明指标提取的合理性。
