
图源:卡乐图片 宁颖/摄
今年618率先打价格战的竟是大模型!
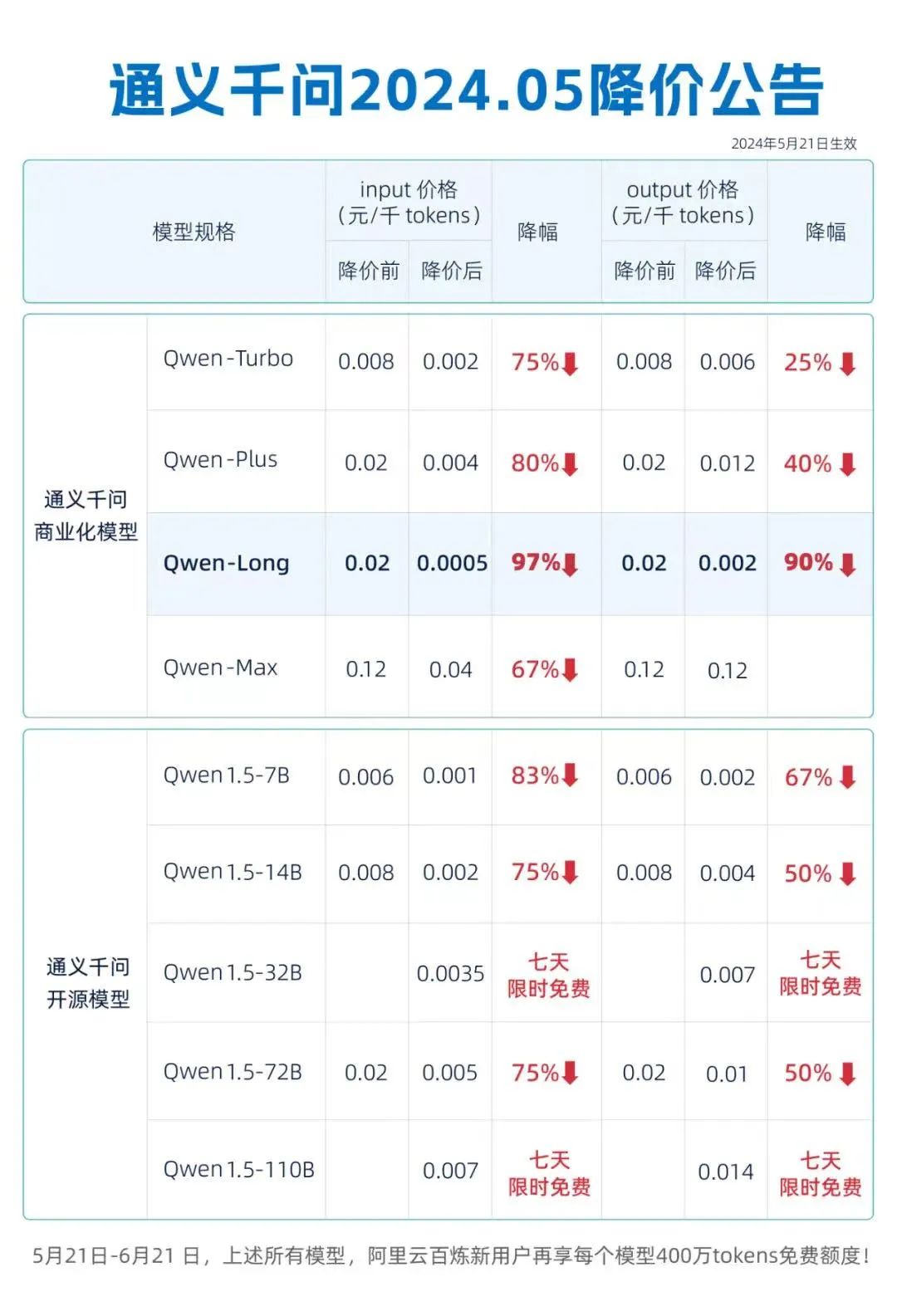
5月21日上午,阿里云宣布通义千问GPT-4级主力模型Qwen-Long降价97%,API输入价格从0.02元/千tokens(文本单位)降到了0.0005元/千tokens。
这意味着,1块钱可以买200万tokens,相当于5本《新华字典》的文字量。这款模型最高支持1千万tokens长文本输入,降价后约为GPT-4价格的1/400,被称为“击穿全球底价”。
仅几个小时,阿里云的价格优势就暗淡了。21日下午,百度智能云便宣布文心大模型两大主力模型全面免费,立即生效,包括ERNIE Speed和ERNIE Lite。
而在一周之前,字节旗下豆包大模型率先将价格卷入“厘时代”。“只要有一家降价都得跟,要不然估计就会掉队。”针对大模型厂商近期降价,新浪微博新技术研发负责人张俊林表示。
大模型掀起降价潮
事实上,这一轮大模型降价潮从5月起就初露端倪。
5月6日,幻方量化旗下DeepSeek(深度求索)发布第二代MoE(专家模型)DeepSeek-V2,API(接口)定价每百万tokens输入1元、输出2元(32K上下文),价格为GPT-4-Turbo的近百分之一。
5月13日,智谱大模型开放平台上线新的价格体系,入门级产品GLM-3 Turbo模型调用价格下调80%,为1元/百万tokens。随后,OpenAI推出GPT-4o,价格为GPT-4 Turbo的一半,输入、输出每百万 tokens收费5美元、15美元。
字节豆包大模型随之加入降价潮。字节跳动宣布其自研大模型时,更是和全行业比价,宣布大模型定价进入“厘时代”,“豆包主力模型在企业市场的定价只有0.0008元/千Tokens,0.8厘就能处理1500多个汉字,比行业便宜99.3%。”
同样价格以“厘”计的还有智谱AI,近日,智谱AI宣布的优惠政策显示,新注册用户赠送额度从500万tokens提升至2500万tokens,在赠送额度下,个人版/入门版GLM-3 Turbo模型调用价格也是以“厘”计。
据悉,此次百度宣布免费的大模型,和阿里云宣布降价的模型均为其主力模型。
5月21日,百度智能云宣布,百度文心大模型的两款主力模型ENIRE Speed、ENIRE Lite全面免费,即刻生效。据悉,这两款大模型发布于今年3月,支持8K和128K上下文长度。

图源:百度微信公众号
百度智能云官网显示,ERNIE Lite是百度自研的轻量级大语言模型,兼顾优异的模型效果与推理性能,适合低算力AI加速卡推理使用。ERNIE Speed则是百度的自研高性能大语言模型,通用能力优异,适合作为基座模型进行精调,能更好地处理特定场景问题,同时具备极佳的推理性能。此外,百度还有一款名叫ERNIE Tiny的轻量模型。
按照以往的定价,ERNIE Lite输入0.003元/千token,输出0.006元/千token。ERNIE Speed价格为输入0.004元/千token,输出0.008元/千token。
21日当天,阿里云也宣布通义千问GPT-4级主力模型Qwen-Long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%。
图源:阿里云微信公众号
国产大模型集体大幅降价可谓开启了一个新的竞争阶段,也将加速“百模大战”的进程。
以价格换市场
随着阿里云4款通义千问商业化模型和3款通义千问开源模型的不同程度降价以及文心大模型两大主力模型的全面免费,大模型厂商似乎正在“榨干”自己的利润空间。
为什么大模型能有如此幅度的降价?对此,阿里云方面表示,这主要因为公共云的技术红利和规模效应带来的成本和性能优势。通过模型和AI基础设施两个层面的不断优化。
Canalys云分析师章一则表示,中国客户群体其实对价格特别敏感,大模型厂商的降价,更多是为了吸引更多客户使用大模型。同时,许多降价的大模型厂商也是云厂商,云厂商让大模型降价最本质的目的还是拉动云消费。
在不断击穿底价甚至免费的“激进”策略下,大模型厂商“抢阵地”的决心远超其对短期利润的渴望。章一分析,中国厂商本身做生意比较擅长采用的手段是低价打入市场,再通过走量的形式把成本铺开。目前,中国B端市场实际使用AI的客户占比并不高,通过降价,大模型厂商希望降低使用其大模型的门槛。
大模型的降价背后,值得关注的是,其背后算力成本的下行也是行业趋势。
阿里云表示,通过构建弹性的AI算力调度系统并结合百炼分布式推理加速引擎,阿里云优化了大规模推理集群,大幅压缩了模型推理成本并加快推理速度。
腾讯云近日也提及大模型算力成本下降情况。腾讯集团副总裁蒋杰透露, 针对低端卡算力低、显存小的不足, 腾讯使用自研Ange训练推理平台,调度异构卡集群,万亿大模型推理成本比开源减少70%。
火山引擎总裁谭待此前表示,字节通过优化模型结构、将单机推理改为分布式推理、混合调度云计算算力等降低成本。DeepSeek 相关负责人则在知乎上解释 ,DeepSeek-V2兼顾成本和效果基本靠的都是模型结构创新 。
行业面临淘汰赛
最近一段时间以来,不仅是阿里、百度、字节等头部大厂,不少中小大模型厂商也纷纷宣布降价。
华龙证券研报表示,随着国内外大模型厂商技术角逐进一步激烈,大模型行业开启价格战信号明显。华福证券研报亦表示,定价的持续走低有望带来更快的商业化落地,进而会衍生出更多的微调及推理等需求,将逐步盘活国内AI应用及国产算力发展。
赛智产业研究院院长赵刚表示,对B端企业用户而言,大模型的使用成本将大幅降低,性价比进一步提升,用户体验感和获得感得到提升,将推动在更多业务领域使用大模型赋能。对应用层的创业公司而言,“价格战”是一个重大利好,这意味着大模型的调用成本将大幅降低,有利于应用创业公司加快创新步伐,开发出更多商业化的大模型应用,促进大模型技术推广。
华龙证券研报指出,对下游企业来说,推理成本进一步降低,AI应用行业有望迎来成本拐点。同时,更多C端用户有望免费使用基础AI应用,庞大的访问量有助于企业进一步提升模型服务能力,完成良性循环。
不过,对于大模型厂商而言,大模型掀起降价潮对于大厂与小厂的影响是不同的。字节火山引擎总裁谭待在谈到豆包降价策略时表示,“一个人现在创业,如果要花1万块钱调用大模型,可能会觉得有点贵。我们把价格降到1%都不到,100块钱就能用起来,他的想法也就更容易尝试。”对于资金雄厚的大厂而言,降价将能够降低使用门槛,有望吸引更广泛的企业用户群体,从而进一步平衡收入和成本。
对于一些专注于提升模型能力、未能砸足够资金抢夺客户与市场的大模型初创公司而言,腥风血雨的价格战绝非一件好事。事实上,在字节豆包大模型大幅降价以后,就有国内明星AI公司的内部人员对外表示,一些客户已经在问询其产品是否会跟进降价,带来了一定的压力。赵刚坦言,对于阿里、字节等大厂以及融到资金的创业公司,价格战是其保持市场竞争优势的重要手段,但对于资金紧张的创业公司,价格战可能就是让企业淘汰出局的致命一击。
华创证券研报认为,整体来看,降低成本是推动大模型快进到“价值创造阶段”的关键要素,更低的成本价格才能真正满足企业的复杂业务场景需求,充分验证大模型的应用价值。尽管模型终端的价格压降或将促使大模型企业对上游加强成本管控,但目前我国企业正处于AI转型的关键时期,低成本下AI模型生态将进一步完善,终端应用亦将涌现出一批核心的创新应用。
来源:微信公众号“财智头条”综合自:第一财经、红星新闻、澎湃新闻、证券时报等
责编:白静
校对:风华
审核:龚紫陌
