机器之心报道
编辑:佳琪、Panda
最近,正处于评议阶段的 ICLR 2025 论文真是看点连连,比如前些天爆出的 ICLR 低分论文作者硬刚审稿人的事件以及今天我们要介绍的这个通过 rebuttal(反驳)硬是将自己的平均分拉高 2 分,直接晋升第 9 名的论文。


ICLR 2025 论文评分分布图,图源:https://papercopilot.com/statistics/iclr-statistics/iclr-2025-statistics/
顺带一提,不知道是不是因为 ICLR 2025 审稿过程状况连连,官方此前还决定将论文讨论过程延长 6 天。

下面我们就来看看这篇「咸鱼翻身」的论文究竟研究了什么以及它的评审和反驳之路。

论文主要内容
这篇论文提出的 Sana 是一种高效且经济地训练和合成高质量图像的工作流程,并且支持 1024×1024 到 4096×4096 的分辨率。下图展示了 Sana 生成的一些图像样本及其推理延迟情况。

作者表示:「据我们所知,除了 PixArt-Σ 之外,还没有直接探索 4K 分辨率图像生成的已发表研究成果。然而,PixArt-Σ 仅能生成接近 4K 分辨率(3840×2160)的图像,并且生成这种高分辨率图像的速度相对较慢。」
那么,这个来自英伟达、MIT 和清华大学的研究团队是如何做到这一点的呢?
具体来说,他们提出了多项核心设计。
深度压缩自动编码器
该团队提出了一种新的自动编码器(AE),可将缩放因子(scaling factor)大幅提升至 32!
过去,主流的 AE 仅能将图像的长度和宽度压缩 8 倍(AE-F8)。与 AE-F8 相比,新提出的 AE-F32 输出的潜在 token 量可减少 16 倍。这对高效训练和生成超高分辨率图像(例如 4K 分辨率)至关重要。
下表 1 展示了不同 AE 的重建能力。

图 3 则展示了对新提出的深度压缩自动编码器进行消融实验的结果。该结果证明了新 AE 各项设计的重要性。

高效的线性 DiT

该团队还提出使用一种新型的线性 DiT 来替代原生的二次注意力模块,如上右图所示。
原始 DiT 的自注意力的计算复杂度为 O (N2)—— 在处理高分辨率图像时,这个复杂度会二次级增长。该团队将原生注意力替换成线性注意力后,计算复杂度便从 O (N2) 降至 O (N)。

该团队表示:「我们认为,通过适当的设计,线性注意力可以实现与原生注意力相当的结果,并且还能更高效地生成高分辨率图像(例如,在 4K 时加速 1.7 倍)。
同时,他们还提出了 Mix-FFN,其作用是将 3×3 深度卷积集成到 MLP 中以聚合 token 的局部信息。
Mix-FFN 的直接好处是不再需要位置编码(NoPE)。该团队表示:「我们首次删除了 DiT 中的位置嵌入,并且没有发现质量损失。」
使用仅解码器小 LLM 来作为文本编码器
为了提升对用户提示词的理解和推理能力,该团队使用了最新版的 Gemma 作为文本编码器。
尽管这些年来文生图模型进步很大,但大多数现有模型仍然依赖 CLIP 或 T5 进行文本编码,而这些模型通常缺乏强大的文本理解和指令遵从能力。仅解码器 LLM(例如 Gemma)表现出的文本理解和推理能力很强大,还能有效遵从人类指令。
下表比较了不同文本编码器的效果。

通过直接采用 LLM 作为文本解码器,训练不稳定的问题得到了解决。
另外,他们还设计了复杂人类指令(CHI),以充分理解 LLM 那强大的指令遵从、上下文学习和推理能力,进而更好地对齐图像与文本。从下图可以看到,有无 CHI 的输出结果差异非常明显。

高效的训练和推理策略
为了提升文本和图像的一致性,该团队提出了一套自动标注和训练策略。
首先,对于每张图像,使用多个 VLM 来重新生成描述。虽然这些 VLM 的能力各不相同,但它们的互补优势可提高描述的多样性。
他们还提出了一种基于 Clip Score 的训练策略,即对于一张图像的多个描述,根据概率动态选择具有高 Clip Score 的描述。实验表明,这种方法可以提高训练收敛性和文本图像对齐程度。下表比较了训练期间不同的图像 - 文本对采样策略的效果。

此外,他们也提出了一种 Flow-DPM-Solver,相比于广泛使用的 Flow-Euler-Solver,这种新的求解器可将推理采样步骤从 28-50 步减少到 14-20 步,同时还能实现更好的结果。见下图。

实验结果
总体实验下来,该团队的新模型 Sana-0.6B 表现可谓极佳。在生成 4K 图像时,速度比当前最佳(SOTA)的 FLUX 方法快 100 多倍(见下图 2)。在生成 1K 分辨率图像时,也快 40 倍(见下图 4)。同时,Sana-0.6B 的效果在许多基准上都能与 FLUX 比肩!

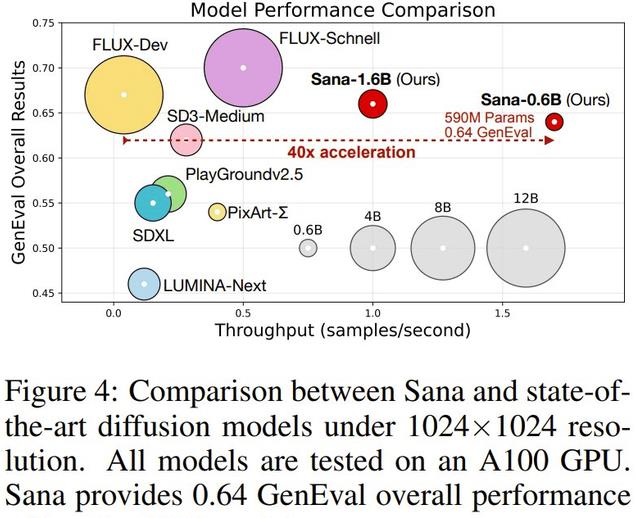
不仅如此,他们还训练了一个参数量更大的 Sana-1.6B 模型。下表更详细地展示了这两个模型的性能表现,可以看到,对于 512 × 512 分辨率,Sana-0.6 的吞吐量比大小相近的 PixArt-Σ 快 5 倍,并且在 FID、Clip Score、GenEval 和 DPG-Bench 方面表现明显优于后者。对于 1024 × 1024 分辨率,Sana 比大多数模型强得多。这些结果说明 Sana 确实实现了低延迟、高性能的图像生成。

此外,他们还为 Sana 打造量化版本,并将其部署到了边缘设备上。
在单台消费级 4090 GPU 上,该模型生成 1024×1024 分辨率图像只需 0.37 秒,是一个非常强大的实时图像生成模型。

下面展示了 Sana-1.6B 模型的一些输出结果以及部署量化版模型的笔记本电脑。

rebuttal 真的有用?
很多时候,在审稿人的第一印象已经确定的情况下,rebuttal 能够改变的不多。
正如知名长文《审稿 CVPR 而致的伤痕文学(续):关于 Rebuttal 的形而上学》所说,从审稿人的角度来看,收到 rebuttal 时,可能早就已经忘了当时为什么会给这个审稿意见,对这篇文章的唯一记忆就是「我要拒掉它」。

引自 https://zhuanlan.zhihu.com/p/679556511 作者 @Minogame
那么,SANA 到底拿出了一份怎样的 rebuttal,四个审稿人看过后不再「已读不回」,反倒不约而同地加了 2 分呢?
第一位审稿人和第三位审稿人的意见比较相似,他们认为 SANA 的原创性有些不足。具体来说,第一位审稿人在缺点部分写道:
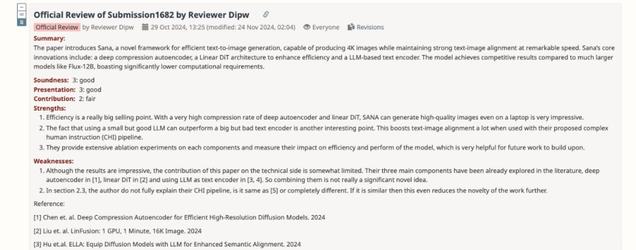
第三位审稿人则希望作者们补一些消融实验,逐个组件分析,明确 SANA 相较于 PixArt-Σ 和 Playground v3 等类似的模型有什么创新之处。

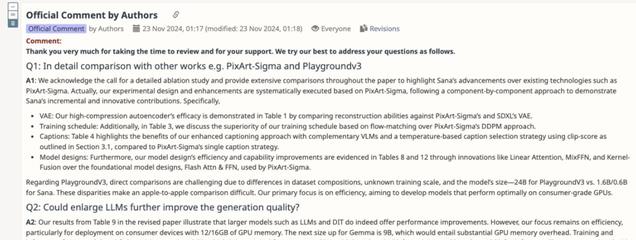
SANA 的研究团队首先详细地说明了站巨人的肩膀上创新和做学术裁缝的区别。
比如,LinFusion 中的线性注意力是蒸馏策略的一部分,而作者们把 SANA 作为一个基础生成模型,从头开始设计、训练。为了让线性注意力在所有层中代替原来的自注意力,他们做出了 Mix-FFN 解码器。
这样,相比其他方法将所有 token 映射到一个低秩的 NxN 状态中,SANA 更接近于直接的 O (N) 注意力计算,这是以前的研究未能有效解决的问题。
对比同样提交给 ICLR 2025 的「DC-AE」,SANA 解决了未涉及的独特问题,比如简单地在潜在空间中增大通道(F8C4→F32C32)会使得训练收敛速度大大减慢,他们设计了线性注意力 + Mix-FFN 块加速收敛。
而此前 LLM 作为文本编码器的方法,更多只是简单地用 LLM 替代了 T5/Clip,并未像 SANA 一样深入研究了如何激发 LLM 的推理能力。
针对审稿人的问题,作者补充了一系列消融实验,比较了 LiDiT 和 SANA 的 CHI 效果,并逐个组件地展示了 SANA 在 PixArt-Σ 基础上的进展。
这两位审稿人也是给出了一个提分的大动作:


第二位审稿人更在意技术细节,他觉得 SANA 如何搭建的线性注意力模块还可以说得更清楚。
具体来说,需要明确一下,他们是如何实现线性注意力能全局替代传统自注意力,同时保持足够的上下文信息和依赖关系建模的,还要补 4096*4096 分辨率的图像与其他方法的实验对比。

在一通极其详细的解释之下,这位(可能不清楚目前没有 4K 版本 InceptionNet 的)审稿人也把分数也提了 2 分。

第四位审稿人则给出了 10 分的最高分评价。

一开始,该审稿人指出了这篇论文的一些缺点,包括表 9 中的 Gemma2-2B-IT 模型需要解释、需要进一步比较 Gemma2 和 T5-XXL 以及缺乏对 UltraPixel 等引用等等。
然后,作者对该审稿人的四个问题逐一进行了详细解答,并为论文内容做了进一步的补充。此后,又是关于 ClipScore 的几个来回讨论。

最后,审稿人被作者说服,表示:「我再也看不到这篇论文中任何明显的缺点了。因此,我提高了我的评分。这项工作确实应该作为会议的亮点!很出色的工作!」

从这些审稿人与作者的互动可以看到,建设性的讨论和修正确实可以帮助改善审稿人对一篇论文的看法。
在多次交流中,审稿人对论文中不清晰或薄弱的部分提出了具体改进建议,而作者也根据反馈进行了细致的修改。这种积极的互动不仅使论文的质量得到了提升,也促进了审稿人与作者之间的理解与信任。最终,审稿人对论文的评审意见变得更加正面,并愿意为作者提供更多的指导。
对此,你有什么看法?
