
在这个AI技术日新月异的时代,Transformer模型就像是一个横空出世的超级英雄,曾经让人们欢呼雀跃。它凭借着强大的并行计算能力和注意力机制,迅速在自然语言处理领域站稳了脚跟,成为了许多AI大模型的核心框架。你可以说它是AI界的“超人”,因为它的出现解决了很多传统RNN模型无法解决的问题,比如长距离依赖和训练效率低下。然而,这位“超人”也有它的“氪星石”,那就是计算复杂度和内存占用。

Transformer的计算复杂度与序列长度呈平方关系,这就像是给它绑上了一个沉重的“枷锁”,让它在处理长序列时显得有些力不从心。再加上内存占用高的问题,Transformer在面对海量数据时,常常显得捉襟见肘。于是,研究者们开始绞尽脑汁,试图为Transformer减负。线性注意力、稀疏注意力等各种改进方法如雨后春笋般涌现,试图在降低计算复杂度的同时,不损失模型的性能。

就在大家以为Transformer会被新秀取代时,谷歌的Titans模型横空出世,誓要在长序列处理的战场上与Transformer一较高下。Titans模型的核心创新在于引入了神经长期记忆模块、自适应遗忘机制等新颖的设计,试图解决Transformer在长序列处理中的种种挑战。Titans的出现,让人们不禁想起了那句老话:“长江后浪推前浪,前浪死在沙滩上。”但在AI的江湖中,前浪未必就会被后浪拍死,或许它们可以携手并进,共同推动技术的进步。
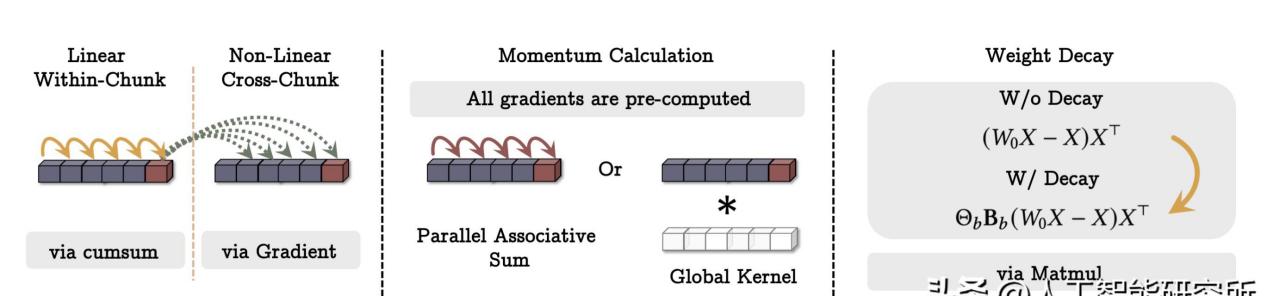
Titans模型的设计灵感来源于人类的记忆机制,通过结合短期、长期和持久记忆,使得模型在处理复杂任务时能够更加游刃有余。它的记忆机制基于输入数据的“惊喜程度”,也就是说,模型更倾向于记住那些违反预期的信息,而不是一味地囤积数据。这种设计让人不禁想起了人类的大脑,毕竟,我们也总是对那些让人意想不到的事情记忆犹新。

当然,Titans的创新不仅限于此。它还提出了一种自适应遗忘机制,可以根据当前输入数据和历史信息的关联性,选择性地遗忘一些信息。这就像是给模型装上了一个“垃圾清理器”,在保证内存利用率的同时,不影响模型的性能。除此之外,Titans还采用了在线元学习的训练范式,使得模型在测试时能够动态调整记忆,而不是一味地过度拟合训练数据。
在性能方面,Titans模型在处理长序列时展现出了不俗的表现。无论是在语言建模、常识推理还是基因组学和时间序列预测等任务上,Titans都能够与Transformer一较高下,甚至在某些任务中表现得更为出色。更令人惊讶的是,Titans在参数较小的情况下,依然能够与GPT-4等大型模型竞争,这无疑为AI界注入了一针强心剂。
那么,Transformer和Titans究竟谁能笑到最后?在我看来,这场“龙虎斗”并不一定要分出胜负。正如生活中的许多事情一样,合作往往比竞争更能创造价值。或许在未来,我们会看到这两位“英雄”携手合作,共同推动AI技术的发展,为人类带来更多的便利和惊喜。

Transformer模型作为AI界的“超人”,凭借其强大的并行计算能力和注意力机制,一度成为自然语言处理领域的宠儿。然而,随着应用场景的不断扩展,Transformer的计算复杂度和内存占用问题逐渐暴露,限制了其在长序列处理中的表现。谷歌的Titans模型以其独特的神经长期记忆模块和自适应遗忘机制,试图在长序列处理的战场上挑战Transformer,并取得了不俗的成绩。尽管Titans在某些任务中表现出色,但Transformer的地位依然不可撼动。未来,或许这两者可以携手合作,共同推动AI技术的进步,为人类社会创造更多价值。无论最终谁能笑到最后,AI技术的发展都将为我们带来更多的惊喜和可能性。让我们拭目以待,期待这场“龙虎斗”带来的精彩表现。

