因为大模型的火爆,对算力的的渴求持续攀升。过去两年,让我们知道了英伟达H100芯片的影响力。与之相伴随的,高带宽内存(HBM)、CoWos封装等相关的技术也让大家有所耳闻。殊不知,互联的作用不亚于这些技术。互联技术也是AI芯片中很重要的一块拼图。
AI芯片之间互联一直是个难题,随着近年来越来越多的加速器被集成到一起,如何高效传输数据成为了瓶颈。当需要连接成千上万个加速器时,性能损耗和带宽瓶颈就会显现出来。这正在持续倒逼互联的迭代加速。
可以说,当前,我们正处于重大互联技术转型的风口浪尖。
超越 PCIe:AI 芯片厂商自研互联技术
由于PCIe技术的发展速度跟不上时代需求,目前主流的AI芯片厂商都已经自研了互联技术,其中较为代表的就是英伟达的NVLink和AMD的Infinity Fabric。
英伟达的NVLink
自2014年开始,英伟达在其GPU中引入了NVLink互联技术。NVLink 是由 Nvidia 开发的一种高带宽、低延迟的点对点数据传输通道。它的主要用途是连接 Nvidia GPU,或者 GPU 与 CPU 之间的通信,允许它们以高速率共享数据。这对于那些要求高数据吞吐量和低通信延迟的应用至关重要,如深度学习、科学计算和大规模模拟。过去十年间,NVLink已成为英伟达GPU芯片的核心技术及其生态系统的重要组成部分。
让我们再来细细回顾下NVLink这一技术的发展历程。2014年,NVLink 1.0发布并在P100 GPU芯片之间实现,两个GPU之间有四个NVLink,每个链路由八个通道组成,每个通道的速度为20Gb/s,系2统整体双向带宽为160GB/s(20*8*4*2)/8=160GB/s),是PCle3x16的五倍;
2017年英伟达推出了第二代NVLink,两个V100 GPU芯片之间通过六个NVLink 2.0连接,每个链路也是由八个通道组成,不过每个通道的速度提升至为25Gb/s,从而实现300GB/s的双向系统带宽(25*8*6*2)/8=300GB/s),几乎是NVLink1.0的两倍。此外,为了实现八个GPU之间的完全互连,Nvidia引入了NVSwitch技术。NVSwitch1.0有18个端口,每个端口的带宽为50GB/s,总带宽为900GB/s。每个NVSwitch保留两个用于连接CPU的端口。通过使用6个NVSwitch,可以在8个GPUV100芯片之间建立一个全连接的网络。
2020年,推出NVLink 3.0技术。它通过12个NVLink连接连接两个GPU A100芯片,每个链路由四个通道组成。每个通道以50Gb/s的速度运行,从而产生600GB/s的双向系统带宽,是NVLink2.0的两倍。随着NVLink数量的增加,NVSwitch上的端口数量也增加到36个,每个端口的运行速度为50GB/s。

DGX A100系统由8个GPU A100芯片和4个NVSwitch组成
2022年,NVLink技术升级到第四代,允许两个GPU H100芯片通过18条NVLink链路互连。每个链路由2个通道组成,每个通道支持100Gb/s(PAM4)的速度,从而使双向总带宽增加到900GB/s。NVSwitch也升级到了第三代,每个NVSwitch支持64个端口,每个端口的运行速度为 50GB/s。
2024年,随着英伟达全新Blackwell架构的发布,NVLink 5.0也随之而来。NVLink 5.0以每秒100 GB的速度在处理器之间移动数据。每个 GPU 有 18 个 NVLink 连接,Blackwell GPU 将为其他 GPU 或 Hopper CPU 提供每秒 1.8 TB 的总带宽,这是 NVLink 4.0 带宽的两倍,是行业标准 PCIe Gen5 总线带宽的 14 倍。NVSwitch升级到了第四代,每个NVSwitch支持144个NVLink 端口,无阻塞交换容量为 14.4TB/s。
NVLink设计之初,就是为了解决传统的PCI Express (PCIe) 总线在处理高性能计算任务时带宽不足的问题。从下面两幅图的对比中,可以发现,从单通道速度的角度来看,NVLink的速度通常是同代PCle的两倍左右。总带宽的优势更加明显,NVLink提供的总带宽约为PCle的五倍。
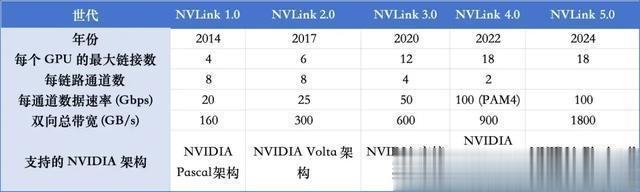
各代NVLink的性能参数

各代PCIe的参数(图源:naddod)
除了NVLink,另外一个值得一提的互联技术是InfiniBand。英伟达收购的Mellanox在InfiniBand领域也处于佼佼者。自收购Mellanox以来,NVIDIA也开始将NVLink技术与InfiniBand(IB)技术相结合,推出新一代NVSwitch芯片和具有SHARP功能的交换机,针对外部GPU服务器网络进行了优化。
InfiniBand是一种开放标准的网络互连技术,具有高带宽、低延迟、高可靠性的特点。该技术由 IBTA(InfiniBand 贸易联盟)定义。该技术广泛应用于超级计算机集群领域。同时,随着人工智能的兴起,它也是GPU服务器的首选网络互连技术。由于 RDMA(远程直接内存访问)等功能,InfiniBand 在人工智能等数据密集型任务中通常优于以太网。据Dell'Oro 估计,约90%的AI部署都是使用Nvidia/Mellanox的InfiniBand,而不是以太网。这些部署将 Nvidia 的网络收入推至每年100亿美元。
近日传奇CPU设计师兼Tenstorrent首席执行官 Jim Keller是开放标准的坚定支持者,他建议 Nvidia应该在基于 Blackwell 的GB200 GPU 中使用以太网协议芯片到芯片连接,而不是专有的NVLink,背后的主要原因是,这可能会使软件移植到其他硬件平台变得更加复杂。而凯勒认为,使用以太网协议可以为英伟达及其硬件用户节省大量资金。
AMD的Infinity Fabric
与英伟达的NVLink相似,AMD则推出了其Infinity Fabric技术,支持芯片间、芯片对芯片,以及即将推出的节点对节点的数据传输。Infinity Fabric是AMD在其“Zen”微架构中引入的一个关键特性,旨在提高整体系统性能,特别是在多核心处理器和数据中心环境中。
Infinity Fabric由两部分组成:数据布线(Data Fabric)和控制布线(Control Fabric)。数据布线用于处理器内部和处理器之间的数据传输,而控制布线则负责处理器的功耗、时钟和安全性等方面的管理。Infinity Fabric的主要特点包括:1)高效率:Infinity Fabric设计用于提供高效率的数据传输,支持多个设备之间的高速通信;2)模块化:Infinity Fabric支持AMD的小芯片(chiplet)架构,允许不同功能的芯片模块通过高速互连进行组合;3)内存共享:Infinity Fabric支持CPU和GPU之间的内存共享,有助于提高异构计算的效率;4)扩展性:Infinity Fabric的设计允许它随着技术进步和需求增长而扩展。
视频链接请点击:
AMD最新的AI加速器Instinct MI300X 平台,就通过第四代AMD Infinity Fabric链路将 8 个完全连接的 MI300X GPU OAM 模块集成到行业标准 OCP 设计中,为低延迟 AI 处理提供高达 1.5TB HBM3 容量。第四代 Infinity Fabric支持每通道高达 32Gbps,每链路产生 128GB/s 的双向带宽。
不同于英伟达NVLink仅限于内部使用,AMD已经开始向新合作伙伴开放其 Infinity Fabric 生态系统。在去年年末AMD MI3000的发布会上,Broadcom宣布其下一代PCIe交换机将支持XGMI/Infinity Fabric。不仅如此,AMD还希望Arista、博通、Cisco等合作伙伴能推出适用于 Infinity Fabric 等产品的交换机,能够方便MI3000在单一系统外实现芯片间通信。这类似于英伟达的NVSwitch。
英特尔:以太网的坚实拥护者
英特尔的用于生成式AI的Gaudi AI芯片则一直沿用传统的以太网互联技术。Gaudi 2 每个芯片使用了24 个 100Gb以太网链路;Gaudi 3也使用了24 个 200 Gbps 以太网 RDMA NIC,但是他们将这些链路的带宽增加了一倍,达到 200Gb/秒,使芯片的外部以太网 I/O 总带宽达到 8.4TB/秒。
在近日的intel vision峰会上,英特尔还宣布正在开发一款用于超以太网联盟(UEC)兼容网络的 AI NIC ASIC 以及一款 AI NIC 小芯片,这些创新的AI高速互联技术(AI Fabrics)将用于其未来的 XPU 和 Gaudi 3 处理器。这些创新旨在革新可大规模纵向(scale-up)和横向(scale-out)扩展的AI高速互联技术。
一直以来,英特尔都希望通过采用纯以太网交换机来赢得那些不想投资 InfiniBand 等专有/替代互连技术的客户。InfiniBand非常适合那些运行少量非常大的工作负载(例如 GPT3 或数字孪生)的用户。但在更加动态的超大规模和云环境中,以太网通常是首选。Nvidia 最新的 Quantum InfiniBand 交换机的最高速度为 51.2 Tb/s,端口为 400 Gb/s。相比之下,以太网交换在近两年前就达到了 51.2 Tb/s,并可支持 800 Gb/s 的端口速度。
虽然InfiniBand在很多情况下表现都不错,但它也有缺点,比如只能在特定范围内使用,而且成本也不低,将整个网络升级到 InfiniBand 需要大量投资。相比之下,以太网因为兼容性强,成本适中,以及能够胜任大多数工作负载,所以在网络技术领域里一直很受欢迎,建立了一个庞大的“以太网生态”。
Dell'Oro 预计 InfiniBand将在可预见的未来保持其在 AI 交换领域的领先地位,但该集团预测在云和超大规模数据中心运营商的推动下,以太网将取得大幅增长,到2027 年大约将占据20%的市场份额。
不仅是英特尔,在2023年的AI Day上,AMD也表示将重点支持以太网,特别是超级以太网联盟。虽然 Infinity Fabric提供了GPU之间的一致互连,但AMD正在推广以太网作为其首选的 GPU 到 GPU网络。
此外,英特尔还提出了一种开放性互联协议Compute Express Link(CXL)。关于CXL互联技术,业界看法不一。英伟达的GPU一向单打独斗,并不支持CXL;AMD透露其MI300A会支持CXL。目前来看,像三星、SK海力士、美光等存储厂商更加青睐于CXL。
AI互联的下一步:迈向光互联时代
诚然,这些互联技术都已是目前最好的互联技术,但是一个不争的事实是,随着计算数据的爆炸式增长、神经网络的复杂性不断增加,以及新的人工智能和图形工作负载和工作流程以及传统科学模拟的出现,对更高带宽的需求还在继续增长。这些互联技术将不可避免的存在性能瓶颈。例如Nvidia 的 NVLink 虽然速度很快,但是功耗也相当高;而 AMD的Infinity Fabric则适合于芯片内部的连接,对于芯片之间的互联效率并不理想。
是时候进行范式转变了。光互联凭借高带宽、低功耗等优势,几乎成为公认的未来 AI 互联技术的发展方向。Nvidia 数据中心产品首席平台架构师 Rob Ober 在媒体咨询中表示:“在过去的十年中,Nvidia 加速计算在人工智能方面实现了数百万倍的加速。” “下一个百万将需要光学I/O等新的先进技术来支持未来 AI 和 ML 工作负载和系统架构的带宽、功率和规模要求。”
在光互联之路上,谷歌的TPU芯片已经率先起了个好头儿。作为AI芯片的重要玩家,谷歌的TPU一直可圈可点。过去几年时间,谷歌一直在悄悄地检修其数据中心,它被称为“阿波罗任务”,主要是用光代替电子,并用光路交换机(OCS)取代传统的网络交换机。
自TPU v4开始,谷歌引入了其内部研发的创新的互联技术:光路交换机 (OCS)。TPU v4是第一台部署可重新配置 OCS 的超级计算机,它内部的4096个芯片通过OCS互连,能够提供百亿亿次的机器学习性能。OCS可以动态地重新配置其互连拓扑,以提高规模、可用性、利用率、模块化、部署、安全性、功耗和性能。
据谷歌声称,OCS比Infiniband更便宜、功耗更低且速度更快,OCS和底层光学组件的成本和功耗只占TPU v4系统的一小部分,不到5%。下图显示了 OCS 如何使用两个 MEM 阵列工作。无需光到电到光转换或耗电的网络数据包交换机,从而节省电力。谷歌表示,TPU 超级计算机的性能、可扩展性和可用性使其成为 LaMDA、MUM 和 PaLM 等大型语言模型的主力。Midjourney一直在使用 Cloud TPU v4 来训练他们最先进的模型。

到了TPU v5代,其每个Pod网络中包含8,960个芯片,这些芯片也是通过专有的OCS互连,并提供 4,800 Gbps 的吞吐量。与TPU v4相比,TPU v5p 的 FLOPS 提高了 2 倍以上,高带宽内存 (HBM) 提高了 3 倍,达到 95GB,TPU v4 Pod 具有 32GB HBM。
Broadcom、Marvell、思科等厂商则在光电共封交换机领域发力。其中博通和Marvell都已经推出了51.2Tbps的交换机。关于光电共封的更多知识,可以翻看《芯片巨头的“新”战场》一文。
博通表示,光学互连对于大规模生成式AI集群中的前端和后端网络都至关重要。如今,可插拔光收发器消耗大约50%的系统功耗,占传统交换机系统成本的50%以上。新一代GPU不断增长的带宽需求,加上AI集群规模的不断增大,需要颠覆性的节能且经济高效的光学互连,超越分立解决方案。
2024年3月14日,博通已向客户交付业界首款 51.2 Tbps共封装光学 (CPO) 以太网交换机Bailly。该产品集成了八个基于硅光子的6.4-Tbps光学引擎和 Broadcom 的 StrataXGS Tomahawk5交换芯片。与可插拔收发器解决方案相比,Bailly 使光学互连的运行功耗降低了 70%,并将硅片面积效率提高了 8 倍。
初创公司在硅光子互联领域大展身手
在硅光互联这个新技术领域,得益于技术创新和商业模式的灵活性,初创公司在硅光子互联领域取得了突破性进展,为这个市场带来了更多的活力。
Celestial AI是这一领域的一个重要参与者,其Photonic Fabric(光子交换机)技术可以将AI计算和内存解耦,旨在通过光传输的方式来连接不同的 AI 处理单元。这种技术已吸引了包括AMD Ventures在内的多个投资者。
Celestial的技术主要包括三大类:chiplets、interposers和一种基于英特尔 EMIB 或台积电 CoWoS的称为OMIB的光学解决方案。其中chiplet是最为核心的部件,可以作为额外的内存扩展卡,也可以作为一个芯片与芯片之间的高速互联通道,有点类似于光学版的 NVLink 或 Infinity Fabric。据该公司称,单个 chiplet 的尺寸略小于一个 HBM 存储器堆栈,可以提供高达 14.4 Tb/s 的光电互联速率,当然这不是上限,只是现有芯片架构能够处理的结果。具体而言,Celestial 的第一代技术每平方毫米可支持约 1.8 Tb/秒。第二代 Photonic 结构将从 56 Gb/秒提高到 112 Gb/秒 PAM4 SerDes,并将通道数量从 4 个增加到 8 个,从而有效地将带宽增加到四倍。
Celestial AI宣称,这种方案的内存事务能量开销约为每比特 6.2 皮焦,相比于 NVLink、NVSwitch大约62.5 皮焦的方案降低了 90% 以上,同时延迟也控制在了可接受的范围内。Celestial AI公司预计将在 2025 年下半年开始向客户提供光子交换机芯片样品,并预计在 2027年左右实现量产。
除了 Celestial AI 之外,还有其他几家创业公司也在研发光子互联技术。
Ayar Labs是一家得到英特尔投资支持的光子学初创公司,它已经将其光子互连集成到原型加速器中,实现了小规模量产和出货。Ayar Labs CEO在2024 OFC(光纤通信大会)上表示:“如果想最终改变计算行业,就需要实现电IO 到光学 IO的巨大的提升。”早在2022年,英伟达还与之合作开发光互联技术,与 Nvidia 的合作将侧重于集成 Ayar Labs 的 IP,为未来的 Nvidia 产品开发通过高带宽、低延迟和超低功耗基于光学的互连实现的横向扩展架构。
然后是 Lightmatter,该公司在12月份获得了1.55亿美元的C轮融资,估值高达12亿美元。Lightmatter 的技术被称为Passage,他们提供一个功能类似于OCS(光路交换机)的通信层,该层位于基本和ASIC之间,几乎可以实现全方位通信,这个通信层可以进行动态的配置。通过采用硅内置光学(或光子)互连的形式,使其硬件能够直接与 GPU 等硅芯片上的晶体管连接,这使得在芯片之间传输数据的带宽是普通带宽的 100 倍。该公司声称,Passage 将于2026年上市。

Lightmatter的Passage技术
(图源:Lightmatter)
Coherent在2024 OFC的上推出了一款支持高密度人工智能集群的光路交换机(OCS)。该设备预计明年批量发货,具有 300 个输入端口和 300 个输出端口。在 OCS 中,数据信号在传输交换机时保留在光域中;消除 OEO 转换可以显着节省成本和功耗。此外,与传统交换机不同的是,当下一代AI集群配备更高速的连接时,OCS不需要升级。对于数据中心来说,这显着提高了资本支出回报率。
成立于2020年Nubis Communications也是一个不容小觑的初创公司,该公司在2023年2月份发布其基于硅光芯片的1.6T光引擎XT1600,单通道速率为112Gbps, 功耗达到4.9pJ/bit,带宽密度达到250Gbps/mm。XT1600通过新颖的2D光纤阵列和高度集成的高速硅光子学实现。Nubis的突破基于重新思考光学设计,大幅降低光学DSP所需的性能和功耗,甚至完全消除它。据其称,与传统光学解决方案相比,人工智能加速器或类似的大型 ASIC可以在数据中心内实现全带宽连接,而功耗仅为传统光学解决方案的一小部分。XT1600光学引擎的样品现已提供给客户。而且这种光互连非常适合新兴的盒式架构以及本地chiplet实施,以便在未来实现更紧密的集成。
国内在这一领域,曦智科技发力于光子计算和光子网络两大产品线。2023年,曦智科技发布了首个计算光互连产品Photowave、以及首款片上光网络(oNOC)AI处理器OptiHummingbird。Photowave通过光学器件实现CXL 2.0/PCIe Gen 5的连接,可配置x16、x8、x4、x2等不同通道数,覆盖多种部署场景。
结语
总体来看,在众多厂商的参与下,互联技术将会迎来重大的发展。尤其是围绕光电共封装和硅光子中继层技术的光互连,正在成为AI领域热门赛道。
行业分析公司 LightCounting 首席执行官 Vlad Kozlov 证实:“800G 及以上的数据中心光学器件将继续强劲增长,到 2027 年,可插拔收发器、有源光缆和共封装光学器件的总价值将达到 84 亿美元。未来五年,将有大量全新的光学产品问世。"
1、《Unveiling The Evolution of NVLink》,naddod
2、Jim Keller suggests Nvidia should have used Ethernet to stitch together Blackwell GPUs — Nvidia could have saved billions,tomshardware
