尽管近年来由于 PyTorch 的迅猛发展, scikit-learn 作为建模库已基本失宠,但它仍然是最好的数据准备库之一。
如果你准备深入挖掘一下,你将发现一个宝库,里面有大量有用的工具,可用于更高级的数据准备技术,与后续建模完美兼容。
在本文中,我将介绍四个 scikit-learn 类,它们可以显著加快我作为数据科学家的日常工作中的数据准备工作流程。
1.Pipeline无缝结合预处理步骤Scikit-learn 的Pipeline类使你能够将不同的预处理器或模型组合成一个可调用的代码块:

管道可以由两种不同的东西组成:
转换器:具有fit()和transform()方法的任何对象。可以将转换器视为用于处理数据的对象,并且通常在数据准备工作流程中会有多个转换器。例如,您可能使用一个转换器来估算缺失值,使用另一个转换器来缩放特征或对分类变量进行独热编码。MinMaxScaler()、SimpleImputer()和OneHotEncoder()都是转换器的示例。估计器:在 scikit-learn 术语中,“估计器”通常表示机器学习模型;即具有fit()和predict()方法的对象。如LinearRegression()和RandomForestClassifier()。在管道中,可以根据需要将任意数量的转换器串联在一起,从而可以按顺序应用不同的数据预处理步骤。如果你愿意,还可以在末尾添加估算器(ML 模型),以便使用新转换的数据进行预测。
例如,可以构建一个管道,首先用零填充缺失值,然后对变量进行独热编码:
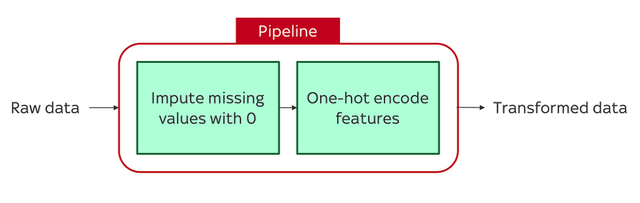
或者,如果你想直接将建模包含在管道本身中,你可以构建一个管道,用平均值填充缺失值,缩放特征,然后使用以下方法进行预测RandomForestRegressor():

使用 scikit-learn 构建管道非常简单。
首先加载一些数据并将其分成训练集和测试集。并使用scikit-learn 提供的糖尿病数据集,其中包含 442 名糖尿病患者的十个预测变量(年龄、性别、体重指数、平均血压和六个血清测量值)以及一个响应变量,该响应变量表示记录这些预测变量一年后每个患者的糖尿病进展情况。
import pandas as pdfrom sklearn.datasets import load_diabetesfrom sklearn.model_selection import train_test_split# 将糖尿病数据集加载到 pandas DataFrames 中X, y = load_diabetes(scaled= False , return_X_y= True , as_frame= True ) # 分成训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3 ) display(X_train.head()) display(y_train.head()) 糖尿病数据集
糖尿病数据集接下来,定义我们的Pipeline。现在,我只定义一个简单的预处理Pipeline,其中包括两个步骤——用平均值填补缺失值,并重新调整所有特征——我不会包含估算器/模型。但是,无论是否包含估算器,原理都是相同的。
from sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import MinMaxScalerfrom sklearn import set_config# 返回 pandas DataFrames 而不是 numpy 数组set_config(transform_output= "pandas" ) # 构建管道pipe = Pipeline(steps=[ ( 'impute_mean' , SimpleImputer(strategy= 'mean' )), ( 'rescale' , MinMaxScaler()) ])一旦我们定义了Pipeline,我们就会将其“拟合”到我们的训练数据集,并使用它来转换训练和测试数据集:
# 将管道适配到训练数据pipe.fit(X_train) # 使用适配的管道转换数据X_train_transformed = pipe.transform(X_train) X_test_transformed = pipe.transform(X_test)这将为我们提供两个预处理的数据集(X_train_transformed和X_test_transformed),用于任何后续步骤,如建模或特征选择。
使用来处理这些预处理步骤的优点Pipeline有两点:
防止泄漏:由于预处理器适合训练数据集X_train,因此在输入缺失值或创建独热编码特征时不会“泄露”有关测试集的信息。避免重复:如果我们不使用Pipeline来处理这些预处理步骤,我们最终会多次转换X_test数据集(每次我们想要应用预处理步骤时)。在这种小规模下,重复似乎不算太糟。但在复杂的 ML 工作流程中,可以轻松地将预处理步骤扩展到 5、10 甚至 20 个。使用Pipeline使这变得容易,因为我们可以添加任意数量的步骤,并且仍然只需转换X_train、X_test一次:preprocessor = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='mean')), ('scaler', MinMaxScaler()), ('step_3', ...), ('step_4', ...), ..., ('step_k', ...)])preprocessor.fit(X_train)X_train_transformed = pipe.transform(X_train)X_test_transformed = pipe.transform(X_test)2. ColumnTransformer将单独的变换器应用于不同的特征子集在上例中,我们对所有特征应用了相同的预处理步骤。但如果我们有异构数据类型,并希望对不同的特征应用不同的预处理器,该怎么办?例如,如果我们只想重新缩放数值特征,或者我们想对分类特征进行独热编码?
这就是ColumnTransformer步骤所在。AColumnTransformer允许您将不同的转换器应用于数组或 pandas DataFrame 的不同列。
在下面的代码中,我们首先定义不同的列组,然后针对每个组,使用Pipeline构建一个将作用于该特定组的预处理器。最后,我们将所有转换器链接在一起形成一个ColumnTransformer。
# 仅当您已经运行过前面部分中的代码时,此代码才会起作用from sklearn.pipeline import Pipeline, make_pipeline from sklearn.compose import ColumnTransformer from sklearn.preprocessing import OneHotEncoder, FunctionTransformer, MinMaxScaler from sklearn.impute import SimpleImputer # 分类列转换器 - (a)使用模式插补 NA,(b)独热编码categorical_features = [ 'sex' ] categorical_transformer = Pipeline(steps=[ ( 'impute_mode' , SimpleImputer(strategy= 'mode' )), ( 'ohe' , OneHotEncoder(handle_unknown= 'ignore' , sparse= False , drop= 'first' )) # handle_unknown='ignore' 确保忽略训练数据集中未遇到的任何值(即,所有 ohe 列都将设置为零) ]) # 数值列转换器 - (a) 用平均值估算 NA,(b) 重新缩放numeric_features = [ 'bp' , 'bmi' , 's1' , 's2' , 's3' , 's4' , 's5' , 's6' ] # 除“年龄”和“性别”之外的所有numeric_transformer = Pipeline(steps=[ ( 'impute_mean' , SimpleImputer(strategy= 'mean' )), ( 'rescale' , MinMaxScaler()) ]) # 将各个转换器组合成一个 ColumnTransformer preprocessor = ColumnTransformer( # 将各个转换器链接在一起 transformers = [ ( 'categorical_transformer' , categorical_transformer, categorical_features), ( 'numerical_transformer' , numeric_transformer, numeric_features), ], # 默认情况下,未经 ColumnTransformer 转换的列# 将被删除。通过设置 remainder='passthrough',我们确保# 这些列以原始形式保留。 remainder = 'passthrough',# 使用生成它们的转换器的名称作为特征名称的前缀(可选) verbose_feature_names_out = True ) # 获取预处理/特征工程管道# 预处理器的可视化表示preprocessor
为了将ColumnTransformer应用到我们的数据中,我们使用与应用第一个Pipeline相同的代码:
# 将预处理器适配到训练数据preprocessor.fit(X_train) # 使用适配的预处理器转换数据X_train_transformed = preprocessor.transform(X_train) X_test_transformed = preprocessor.transform(X_test)3. FeatureUnion并行应用多个 transformerPipeline和ColumnTransformer都是很棒的工具,但它们有一个很大的局限性。你发现了吗?
他们只能按顺序应用转换器。
换句话说,当你Column1使用Pipeline/ColumnTransformer转换一个特征时,scikit-learn 将首先应用于transformer_1,Column1然后应用于transformer_2的转换版本Column1,依此类推。当我们想要以顺序方式预处理数据时(例如“先填补缺失值,然后进行独热编码”),这很好,但在我们想要并行应用不同的预处理步骤的情况下(例如“同时从同一基础列创建两个新特征”),它并不理想。在这些情况下,使用标准Pipeline或ColumnTransformer是不够的,因为Column1一旦应用序列中的第一个转换器, 的原始“原始”值就会丢失。
如果我们想并行地对相同的底层特征应用多个转换,我们需要使用另一个工具:FeatureUnion。
我们可以将其视为FeatureUnion一种工具,它会创建基础数据的“副本”,并行将转换器应用于这些副本,然后将结果拼接在一起。每个转换器都会传递原始的基础数据,因此我们不会遇到顺序转换的问题。
要使用FeatureUnion,我们只需要添加几行代码:
# 此代码仅当你已经运行过前面部分中的代码时才会起作用from sklearn.pipeline import FeatureUnion from sklearn.decomposition import PCA, TruncatedSVD # 定义一个将创建降维特征的 feature_union 对象union = FeatureUnion(transformer_list=[ ( "pca" , PCA(n_components= 1 )), ( "svd" , TruncatedSVD(n_components= 2 )) ]) # 调整数值转换器,使其包含 FeatureUnion numeric_features = [ 'bp' , 'bmi' , 's1' , 's2' , 's3' , 's4' , 's5' , 's6' ] # 除 'age' 和 'sex' 之外的所有numeric_transformer = Pipeline(steps=[ ( 'impute_mean' , SimpleImputer(strategy= 'mean' )), ( 'rescale' , MinMaxScaler()), ( 'reduce_Dimensionity' , union) ]) # 分类列转换器 - 与上面相同categorical_features = [ 'sex' ] categorical_transformer = Pipeline(steps=[ ( 'impute_mode' , SimpleImputer(strategy= 'mode' )), ( 'ohe' , OneHotEncoder(handle_unknown= 'ignore' , sparse= False , drop= 'first' )) # handle_unknown='ignore' 确保忽略训练数据集中未遇到的任何值(即所有 ohe 列都将设置为零) ]) # 构建 ColumnTransformer preprocessor = ColumnTransformer( transformers = [ ( 'categorical_transformer' , categorical_transformer, categorical_features), ( 'numerical_transformer',numerical_transformer,numerical_features), ], remainder = 'passthrough', verbose_feature_names_out = True)preprocessor
在此图中,我们可以看到这些FeatureUnion步骤是并行应用的,而不是按顺序应用的。就像之前一样,我们将它拟合preprocessor到我们的训练数据中,然后使用它来转换我们想要用于建模/预测的任何数据集。
# 将预处理器适配到训练数据preprocessor.fit(X_train) # 使用适配的预处理器转换数据X_train_transformed = preprocessor.transform(X_train) X_test_transformed = preprocessor.transform(X_test)4. FunctionTransformer无缝集成特征工程上面讨论的所有转换器和工具都使用 scikit-learn 中预先构建的类来对您的数据应用标准转换(例如,缩放、独热编码、插补等)。
如果想要应用自定义函数(例如在特征工程期间),那么需要使用FunctionTransformer。就我个人而言,我很喜欢这个类 - 它使将自定义函数集成到您的函数中变得非常容易,Pipeline而无需从头开始编写新的转换器类。
创建FunctionTransformer非常简单。首先以标准 Pythonic 样式定义函数,然后创建管道。在这里,我定义了两个简单函数:一个将两列相加,另一个将两列相减。
from sklearn.preprocessing import FunctionTransformerdef add_features(X): X['feature_1_2'] = X['feature_1'] + X['feature_2']return Xdef subtract_features(X): X['feature_3_4'] = X['feature_3'] - X['feature_4']return X# 放入管道feature_engineering = Pipeline(steps=[ ('add_features', FunctionTransformer(add_features)), ('subtract_features', FunctionTransformer(subtract_features))])为了进一步简化事情,您可以在同一个函数中包含多个转换:
def add_subtract_features(X): X['feature_1_2'] = X['feature_1'] + X['feature_2'] # Add features X['feature_3_4'] = X['feature_3'] - X['feature_4'] # Subtract featuresreturn X# 放入管道feature_engineering = Pipeline(steps=[ ( 'add_subtract_features' , FunctionTransformer(add_subtract_features)), ])最后将管道添加到我们之前定义的管道feature_engineering中:preprocessing
# 在单个管道中结合预处理和特征工程pipe = Pipeline([ ( 'preprocessing' , preprocessor), ( 'feature_engineering' , feature_engineering), ]) pipe
并使用这个新的管道将相同的预处理/特征工程步骤应用于所有数据集:
# 将预处理器适配到训练数据pipe.fit(X_train) # 使用适配的预处理器转换数据X_train_transformed = pipe.transform(X_train) X_test_transformed = pipe.transform(X_test)保存你的管道,以实现真正可重复的工作流程在机器学习的企业应用中,很少只使用一次模型或预处理工作流程。更常见的情况是,您需要每周/每月定期重新运行模型,并为新数据生成新的预测。
在这些情况下,您不必每次都从头编写新的预处理管道,而是每次都使用相同的管道。为此,一旦您开发了管道并使用库joblib,请保存管道,以便您可以对未来的数据集重新运行完全相同的转换:
import joblib# 保存管道joblib.dump(pipe, "pipe.pkl" ) # 假设以下步骤应用于另一个笔记本/脚本# 加载管道pretrained_pipe = joblib.load( "pipe.pkl" ) # 将管道应用于新数据集 X_test_new X_test_new_transformed = pretrained_pipe.transform(X_test_new)回顾一下:
Pipeline提供一种快速方法,按顺序将不同的预处理转换器应用于数据使用ColumnTransformer是一种很好的方法,可以按顺序将单独的预处理步骤应用于不同的特征子集FeatureUnion能够并行应用不同的预处理转换FunctionTransformer提供一种超级简单的方法来编写自定义特征工程函数并将其集成到你的管道中